Настройка узла Файлы
Окно настроек узла имеет следующие вкладки: Настройки импорта, Выборка, Настройки колонок и Общие. На вкладке Настройки импорта вы можете выбрать папку с импортируемыми файлами и настроить несколько других опций. Остальные вкладки также представлены и в других узлах и описаны в соответствующих разделах (по ссылке).
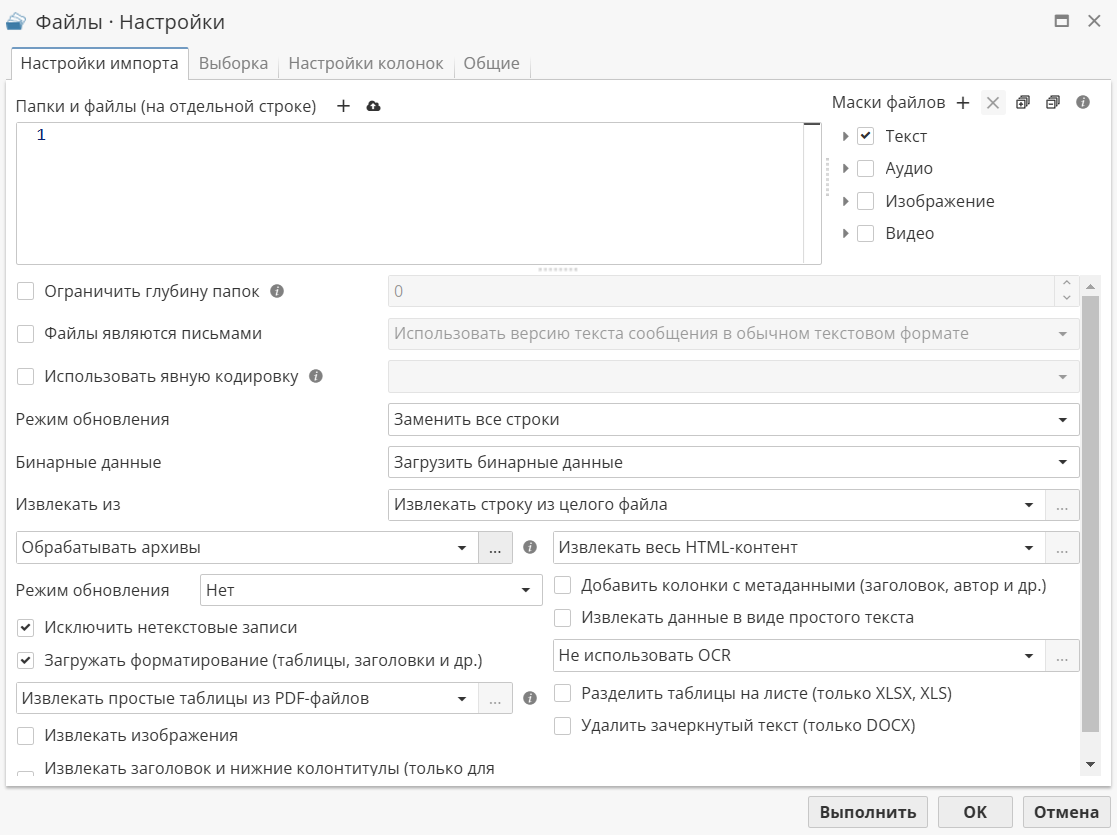
Выбор документов или папок для загрузки
Первый шаг – выбор документов или папки, содержащей документы для импорта. Нажмите на кнопку  и выберите папку в появившемся окне. Нажмите ОК для закрытия окна выбора файлов. Выбранный путь отобразится в текстовом поле ниже. Для добавления другой папки или документа, повторите вышеописанные шаги.
и выберите папку в появившемся окне. Нажмите ОК для закрытия окна выбора файлов. Выбранный путь отобразится в текстовом поле ниже. Для добавления другой папки или документа, повторите вышеописанные шаги.
| Начиная с PolyAnalyst 6.5 версии 2412 при открытии окна настроек узла окно выбора документов вызывается автоматически. |
Для того чтобы загрузить файлы, которые находятся на вашем компьютера, воспользуйтесь кнопкой Загрузить  . Альтернативный способ: просто перетащите файлы с компьютера на скрипт, что приведет к автоматической загрузке файлов и созданию соответствующего предварительно сконфигурированного узла Файлы.
. Альтернативный способ: просто перетащите файлы с компьютера на скрипт, что приведет к автоматической загрузке файлов и созданию соответствующего предварительно сконфигурированного узла Файлы.
Как уже ранее было описано в разделе, посвященном подготовке данных для импорта, окно, которое открывается при нажатии на кнопку загрузки, отображает те папки и документы, которые доступны серверу PolyAnalyst. При этом необходимо учитывать ряд важных моментов. Например, некоторые папки могут быть недоступны для сервера PolyAnalyst из-за недостаточных прав или настроек. Например, PolyAnalyst может не иметь доступа к съемным носителям; в таком случае они не будут отображаться в окне выбора папок, даже если вы можете видеть эти папки в проводнике Microsoft Windows. В отдельной папке под вашим именем пользователя в системе PolyAnalyst будут доступны загруженные вами файлы. Некоторые сетевые папки в сети вашей компании могут не отображаться в окне выбора папки, например, если сервер PolyAnalyst запущен от имени конкретного пользователя Microsoft Windows с ограниченными правами.
Как правило, путаница при выборе папки чаще всего возникает тогда, когда пользователь забывает, что сервер PolyAnalyst может быть установлен на другом компьютере, а не на той машине, которую он использует в настоящий момент при работе с Аналитическим клиентом PolyAnalyst. Если вы храните документы в папке на вашем компьютере, это не значит, что сервер PolyAnalyst может иметь к ним доступ и вообще видеть эти папки. Если вы настроите совместное использование папки или сохраните файлы в сетевом хранилище, PolyAnalyst сможет увидеть эту папку и разрешит вам ее использовать в процессе импорта данных. Если сервер PolyAnalyst установлен на вашей локальной машине, и вы работаете с собственным сервером PolyAnalyst, то такая проблема не возникнет: вы увидите все папки, которые хранятся на вашем компьютере.
Подобные сложности связаны с клиент-серверной архитектурой PolyAnalyst и со спецификой работы узла Файлы. Помните, что именно сервер, а не клиент, получает доступ к документам и импортирует их в таблицу данных, которая хранится на том же компьютере, что и сервер. Также помните следующее: поскольку с помощью Планировщика задач вы можете настроить отсроченное выполнение проекта, содержащего цепочку узлов и включающего узел Файлы, необходимо обеспечить доступ к папке в то время, когда сервер будет выполнять проект. Если нужные файлы будут храниться на вашем компьютере, который будет выключен в момент выполнения проекта, то узел не будет выполнен.
| Если узлу Файлы предшествует узел Параметры (с включенной опцией Очистить старые папки), то поле Папки и файлы будет недоступно для редактирования. Подробную информацию см. в разделе Настройка узла Параметры. |
Почему PolyAnalyst всегда включает разрешение в имя файла
Папка с документами в PolyAnalyst выглядит не так, как в проводнике Microsoft Windows.
Например, Microsoft Windows можно настроить так, чтобы скрыть из имени тип каждого файла. Например, файл мойфайл.txt в проводнике Windows может отображаться как мойфайл без расширения ".txt". Это не значит, что имя файла – мойфайл. На самом деле он называется мойфайл.txt, но в проводнике Windows вы видите упрощенное представление названия файла. Когда PolyAnalyst получает доступ к документу и готовится сохранить имя файла в выходных данных узла Файлы, он будет использовать действительное имя файла – мойфайл.txt.
В настройках узла Файлы такое поведение изменить нельзя. Однако вы можете подойти к вопросу творчески и, соединив узел Файлы с узлом Производные колонки, создать колонку, которая является производной от исходного названия файла, но не имеет части, обозначающей расширение. Предлагаем пользователям самостоятельно составить SRL-выражение для узла Производные колонки. Далее, соедините данный узел с узлом Фильтрация колонок для удаления колонки с названием исходного документа, созданную узлом Файлы. Вы также можете создать групповой узел, который включает последовательность этих трех узлов, назначить этот групповой узел в качестве источника данных, а затем назвать его так, как вы бы назвали сам узел Файлы, если бы могли обрезать расширения файлов в самом узле Файлы. Использование группового узла скроет отдельные мелкие операции импорта, создания новой колонки и фильтрации колонок, поскольку на скрипте будет видна одна совмещенная операция по импорту данных.
Включение или исключение подпапок
Включите опцию Ограничить глубину папок для импорта подпапок корневой папки. Данная опция применяется ко всем без исключения папкам, расположенным в корневой папке. Вы можете определить максимальную глубину чтения папок, указав число уровней в поле справа.
Обновление данных
Для получения дополнительной информации см. раздел добавление данных в ходе импорта. Данная опция присутствует в нескольких узлах и описывается в отдельном разделе.
По умолчанию для опции Режим обновления выбрано значение Заменить все строки. В данном случае узел при каждом последующем выполнении будет удалять ранее созданную таблицу данных и создавать новую. Если выбрать Добавить строки по ключу, PolyAnalyst не будет удалять ранее созданную таблицу данных при повторном выполнении узла и добавит любые новые документы в виде новых записей в существующую выходную таблицу данных, сгенерированную при последнем выполнении узла. Если узел выполняется впервые, то он создаст новую таблицу. Опция Безусловное добавление строк позволяет добавить новые записи в конец существующей таблицы подобно узлу Конкатенация. Если предыдущих записей нет, то новая таблица данных будет сформирована только из импортированных записей. В отличие от режима Добавить строки по ключу, сравнение записей с целью проверки их наличия не производится, таким образом уменьшается время выполнения узла.
Возможность добавления данных полезна при работе с папкой, содержащей тысячи документов, когда на выполнение узла требуется значительное количество времени. Как правило, при работе с небольшим объемом документов (например, до 10 000) на компьютере с достаточной производительностью настройку данной опции можно проигнорировать, т.к. повторный импорт документов не потребует существенных затрат ресурсов.
Работа с бинарными данными
Меню Бинарные данные предназначено для работы с неалфавитными, нечисловыми и непунктуационными символами, а также файлами изображений в документах.
Инструменты текстового анализа PolyAnalyst не предназначены для работы с бинарными данными, поэтому иногда лучше отфильтровать их при импорте. Фильтрация бинарных данных позволяет сократить размер данных, которые хранятся в PolyAnalyst:
-
Для импорта бинарных данных (с максимально возможных сохранением исходного вида) выберите Загрузить бинарные данные;
-
Для того, чтобы отфильтровать бинарные данные, выберите Удалить бинарные данные;
-
Переключитесь на Перезагрузить бинарные данные для обновления бинарных данных. Используйте данный режим в случаях, когда происходит замена файлов на новые с сохранением исходного имени.
Разбиение документов на предложения и абзацы
Меню Извлекать из позволяет настроить импорт отдельных предложений или абзацев в виде самостоятельных значений вместо того, чтобы импортировать документы полностью. Подробная информация представлена в разделе, посвященном разбиению документов на предложения и абзацы в ходе импорта.
Пользователи также могут воссоздать полный текст документа из составляющих его предложений и абзацев, импортированных ранее по отдельности. Это можно сделать с помощью узла Агрегирование.
Ограничение типов импортируемых документов
Типы (маски) файлов, которые импортирует узел Файлы, приводятся в верхней правой части окна и организованы в виде дерева категорий: Текст, Аудио, Изображение, Видео. Каждая категория включает следующие маски:
-
Текст:
-
*.txt
-
*.doc
-
*.rtf
-
*.html
-
*.htm
-
*.pdf
-
*.ppt
-
*.odt
-
*.ods
-
*.docx
-
*.pptx
-
*.xlsx
-
*.xlsm
-
*.xls
-
-
Аудио:
-
*.mp3
-
*.m4a
-
*.wav
-
*.aac
-
*.aiff
-
*.flac
-
*.ogg
-
*.opus
-
*.spx
-
*.wma
-
-
Изображение
-
*.jpg
-
*.tiff
-
*.png
-
*.bmp
-
*.gif
-
*.webp
-
-
Видео
-
*.mp4
-
*.avi
-
*.mkv
-
*.mov
-
*.wmv
-
*.flv
-
Вы можете включать и выключать любые из представленных масок. Также возможно настроить фильтрацию ненужных типов документов, если они находятся в корневой папке или её подпапках. Файловые маски нечувствительны к регистру.
-
Для добавления новой маски к стандартному списку нажмите на кнопку Добавить, которая находится над деревом категорий. В конце списка появится новая категория Настраиваемый, содержащая добавленную маску.
-
Для удаления добавленной маски выберите ее в списке в категории Настраиваемый и нажмите на кнопку Удалить над деревом категорий.
-
Кнопки Развернуть все/Свернуть все позволяют развернуть/свернуть все категории одновременно.
-
Кнопки Выделить все/Отменить все позволяют соответственно выбрать все маски или отменить выбор всех масок.
| Если маски не выбраны, узел будет считывать файлы всех типов в указанной директории. |
Дополнительные настройки импорта
В нижней части окна представлены дополнительные настройки импорта:
Обрабатывать архивы – позволяет импортировать архивные файлы. Узел поддерживает следующие форматы: *.zip, *.arj, *.rar, *.tar и *.7z. Узел также может обрабатывать вложенные архивы.
Исключить нетекстовые записи – позволяет игнорировать нетекстовое содержимое веб-страниц. При выключенной опции узел пытается извлекать ссылки на изображения.
Загружать форматирование – позволяет загружать данные о форматировании документов (таблицы, заголовки и др.).
| Данная опция работает "на перспективу": результат ее работы можно увидеть только в последующем узле Индекс и других текстовых узлах, которые за ним следуют. |
По умолчанию узел Файлы настроен на обработку простых таблиц в PDF-файлах, т.е. выбрано значение Извлекать простые таблицы из PDF-файлов. В данном случае алгоритм будет находить только те таблицы, которые обозначены границами.
Сам по себе формат PDF не предоставляет информации о структуре документа, такой как главы, абзацы, заголовки, таблицы, графики и тому подобное. PDF-файл дает лишь геометрическую информацию о том, где на странице расположены фрагменты текста и линии. Поэтому он по своей сути гораздо ближе к изображению, чем к текстовому документу. Путем анализа этой геометрической информации можно сделать предположение о структуре документа, что и происходит в системе PolyAnalyst при чтении PDF-файлов.
При выборе значения Извлекать сложные таблицы из PDF-файлов включается более глубокий анализ структуры страниц. Этот анализ в некоторых случаях может улучшить распознавание структуры документа, а также позволяет распознавать таблицы по выравниванию блоков текста. При извлечении сложных таблиц время работы алгоритма может увеличиться приблизительно в 10 раз. Поскольку основная задача алгоритма заключается в поиске всех возможных таблиц, он будет выполнять более агрессивный поиск и иногда выдавать ложноположительные результаты, т.е. находить таблицы там, где их нет. Нажмите на кнопку  для доступа к дополнительным настройкам. Здесь вы можете включить/отключить опцию Объединять смежные таблицы при совпадении, изменив тем самым конечный вид некоторых таблиц.
для доступа к дополнительным настройкам. Здесь вы можете включить/отключить опцию Объединять смежные таблицы при совпадении, изменив тем самым конечный вид некоторых таблиц.
При работе с PDF-документами также следует учитывать:
-
в некоторых PDF-файлах могут содержаться не текстовые фрагменты и векторная графика, а просто растровые изображения с отсканированным текстом. В таких случаях рекомендуется использовать инструмент OCR (значение по умолчанию – Не использовать OCR), далее необходимо включить опцию Обработать все файлы и выставить Пороговое соотношение извлеченного текста и PDF-источника в соответствующем поле. Подробная информация представлена ниже;
-
при неудовлетворительной работе обоих видов PDF-парсеров (при выборе значения Извлекать простые таблицы из PDF-файлов или Извлекать сложные таблицы из PDF-файлов) можно попробовать принудительно использовать OCR;
-
иногда PDF-парсерам может помочь предварительная обработка документа. Можно пропустить документ через программу Ghostscript, воспользовавшись командой:
gswin64.exe -sDEVICE=pdfwrite -dNOPAUSE -dBATCH -sOutputFile="new_file.pdf" "initial_file.pdf".
Извлекать изображения – позволяет импортировать изображения.
Извлекать заголовок и нижние колонтитулы (только для DOCX) - включите опцию, чтобы из документов формата docx извлекались заголовки и нижние колонтитулы.
Извлекать весь HTML-контент - позволяет извлекать содержимое из HTML источников. Извлекать только информативный HTML-контент – позволяет отфильтровать информацию, которая, скорее всего, не представляет никакой пользы для анализа. Речь идет об информации, содержащейся в шапке страницы или в нижнем колонтитуле, элементах навигации и др.
Добавить колонки с метаданными – включите опцию, чтобы добавить в выходную таблицу дополнительные колонки с метаданными импортируемых текстов (заголовки, авторы и др.).
Извлекать данные в виде простого текста – позволяет загружать файл в виде простого текста без обработки форматными парсерами. Если опция отключена (поведение по умолчанию), при импорте файлов пользователь самостоятельно определяет их формат, и узел извлекает текстовую информацию, очищенную от тэгов и служебной информации.
Опция Разделить таблицы на листе используется при импорте документов Microsoft Excel, когда на одном листе представлено сразу несколько таблиц. При включении данной опции узел будет ориентироваться на пустые колонки и строки для определения границ.
В верхней части окна вы можете найти опцию Файлы являются письмами. Данная опция позволяет импортировать файлы с расширением *.eml, которые хранятся офлайн. Для этого необходимо указать путь к одному или нескольким файлам, добавить маску *.eml в список файловых масок справа и выполнить узел.
Опция Использовать явную кодировку позволяет выбрать кодировку текста импортируемого файла в случае его неправильного отображения. Если опция не включена, PolyAnalyst попытается угадать кодировку файла самостоятельно.
Оптическое распознавание символов
В правом нижнем углу вкладки Настройки импорта расположено поле, позволяющее настроить инструменты оптического распознавания символов (англ. Optical character recognition, OCR), которые будут использованы при выполнении узла.
По умолчанию распознавание символов не выполняется (выбрано значение Не использовать OCR). Нажмите на данное поле для отображения доступных инструментов OCR:
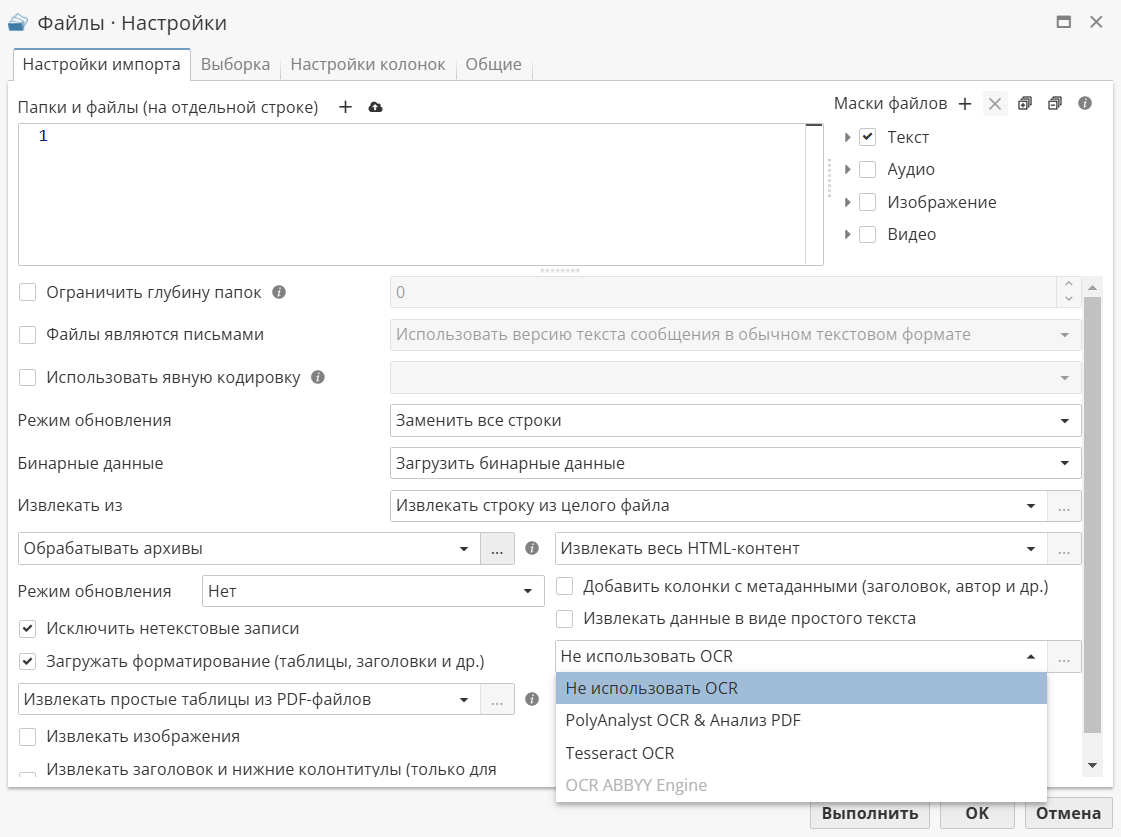
Пункт OCR ABBYY Engine доступен в только в случае, если на сервере установлен ABBYY FineReader Engine, и PolyAnalyst может определить место его установки. В противном случае данная опция будет неактивна. Подробная информация о настройке ABBYY FineReader Engine представлена в специальном разделе.
В качестве альтернативы вы можете использовать Tesseract OCR или PolyAnalyst OCR & PDF Analysis.
| При использовании инструментов оптического распознавания символов не забудьте указать необходимые расширения файлов (например, *.png, *.jpeg, *.tiff) в разделе Маски файлов. |
После выбора инструмента OCR нажмите для перехода к расширенным настройкам.
Опции инструмента PolyAnalyst OCR & PDF Analysis подробно описаны в разделе Настройка узла Оптическое распознавание символов
Tesseract OCR и ABBYY FineReader Engine имеют схожие опции. Ниже представлено окно настроек инструмента Tesseract OCR:
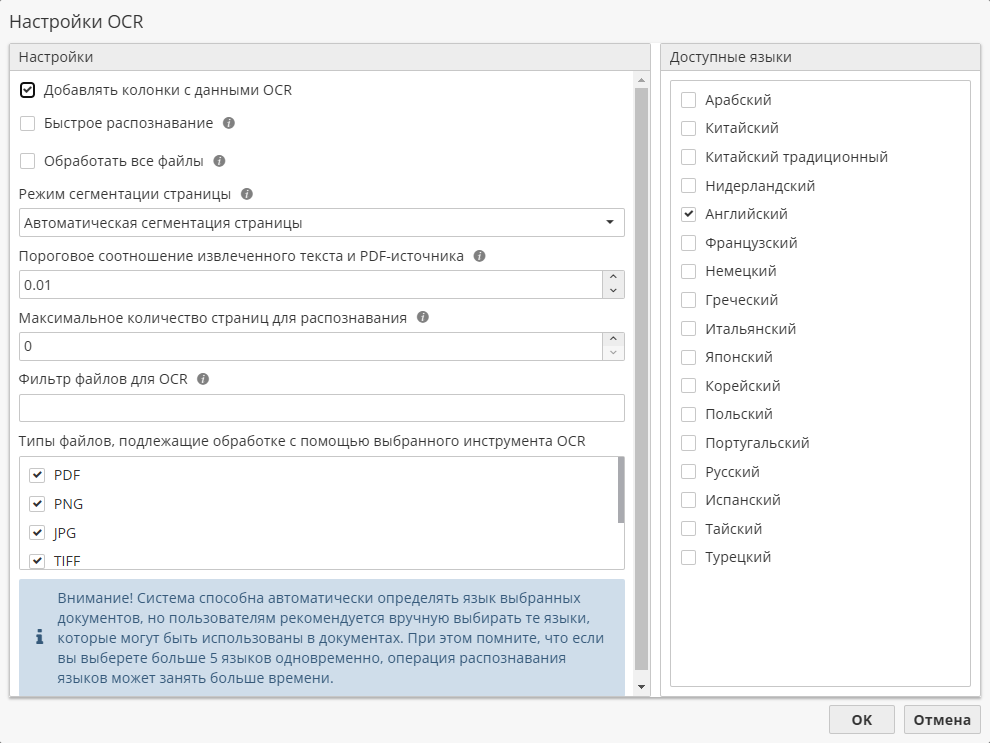
По умолчанию опция Добавлять колонки с данными OCR включена для всех инструментов и позволяет включить в результирующую таблицу данных дополнительные колонки (например, числовую колонку с показателями надежности OCR). Если подобная информация кажется вам лишней, отключите данную опцию.
Опция Быстрое распознавание позволяет увеличить скорость распознавания символов за счет некоторого снижения качества.
Опция Маркировать неуверенно распознанные символы доступна только для инструмента ABBYY FineReader Engine. По умолчанию она включена, что позволяет извлекать информацию о неуверенно распознанных словах и символах. Подобные области будут подсвечиваться в записях после индексации текстовой колонки с помощью узла Индекс.
Опция Явные границы таблиц также присутствует только в настройках инструмента ABBYY FineReader Engine. Если данная опция включена, при обработке таблиц узел будет учитывать только видимые границы. В противном случае узел предпримет попытку определения и распознавания таблиц со скрытыми разделителями.
Опция Обработать все файлы (по умолчанию отключена) указывает парсеру обрабатывать все типы файлов в безусловном порядке (игнорируя все другие фильтры). При включении данной опции поля Пороговое соотношение извлеченного текста и PDF-источника, Фильтр файлов для OCR и Типы файлов, подлежащие обработке с помощью выбранного инструмента OCR станут неактивными.
Режим сегментации страницы определяет направленность анализа и особенности обрабатываемого объекта. Данная настройка является специфичной для инструмента Tesseract OCR.
Поле Пороговое соотношение извлеченного текста и PDF-источника позволяет указать процентное соотношение размеров извлеченного текста и исходного PDF-документа, ниже которого выполняется оптическое распознавание. Например, если в поле указано значение 0,3, а размер извлеченного текста (в символах) составляет менее 30% размера исходного PDF-файла (в байтах), то распознавание выполняется. В противном случае извлеченный текст возвращается без дополнительной обработки.
Если ваш файл состоит из нескольких страниц, используйте опцию Максимальное количество страниц для распознавания, чтобы ограничить их количество при анализе. Значение по умолчанию = 0 означает, что будут обработаны все страницы. Данная опция недоступна для ABBYY FineReader Engine.
В поле Фильтр файлов для OCR вы можете указать строковое значение, которое будет использоваться для определения файлов, подлежащих обработке. Инструмент распознавания будет применен только к тем файлам, в названии которых или в пути к которым присутствует заданное строковое значение.
В нижней части окна представлен список типов файлов, с которыми может работать выбранный инструмент OCR. Для включения/исключения конкретного типа используйте соответствующие флажки.
В правой части окна представлен список доступных языков, которые поддерживает инструмент OCR. Выбор языков осуществляется с помощью флажков. Если какой-то конкретный язык ранее не использовался для распознавания документов, то перед началом операции автоматически будет загружен необходимый пакет DLC.
| При использовании инструментов Tesseract и ABBYY FineReader Engine не рекомендуется одновременно выбирать более пяти языков, поскольку это существенно замедлит процесс распознавания. |
Настройка вкладки Общие
Помимо стандартных для всех узлов опций, вкладка Общие узла Файлы содержит уникальную опцию Количество потоков, которая позволяет значительно увеличить производительность при парсинге сложных документов. Опция Количество потоков настраивает количество потоков для выполнения импорта документов. Значение по умолчанию - 6 (если данное число не превышает количество ядер процессора). Если количество ядер процессора больше 6, то количество потоков равняется количеству ядер.
Настройки узла по умолчанию
Вместо того, чтобы каждый раз настраивать узел Файлы вручную, вы можете задать настройки узла по умолчанию. Для этого выберите Настройки на панели меню Аналитического клиента, перейдите в раздел Настройки пользователя, раскройте группу Настройки проекта по умолчанию, а затем Настройки узлов по умолчанию, после чего выберите Файлы. Справа отобразятся настраиваемые опции:
Здесь вы можете задать маски файлов, настроить обработку бинарного контента, архивов, добавление данных, распознавание таблиц и др.
| Опция Распознавать таблицы по их границам в настоящее время работает только с файлами формата ".docx". |
Возникают ситуации, когда Excel-документы содержат скрытые листы. По умолчанию PolyAnalyst их не импортирует. Отметьте флажком опцию Показывать скрытые листы для отображения и обработки подобных листов.