Настройка узла Оптическое распознавание символов
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Окно настроек узла Оптическое распознавание символов включает семь вкладок: Выбор колонок, Ввод/Вывод, PDF, Изображение, Форматирование страницы, Дополнительно и Общие.
Опции вкладки Выбор колонок
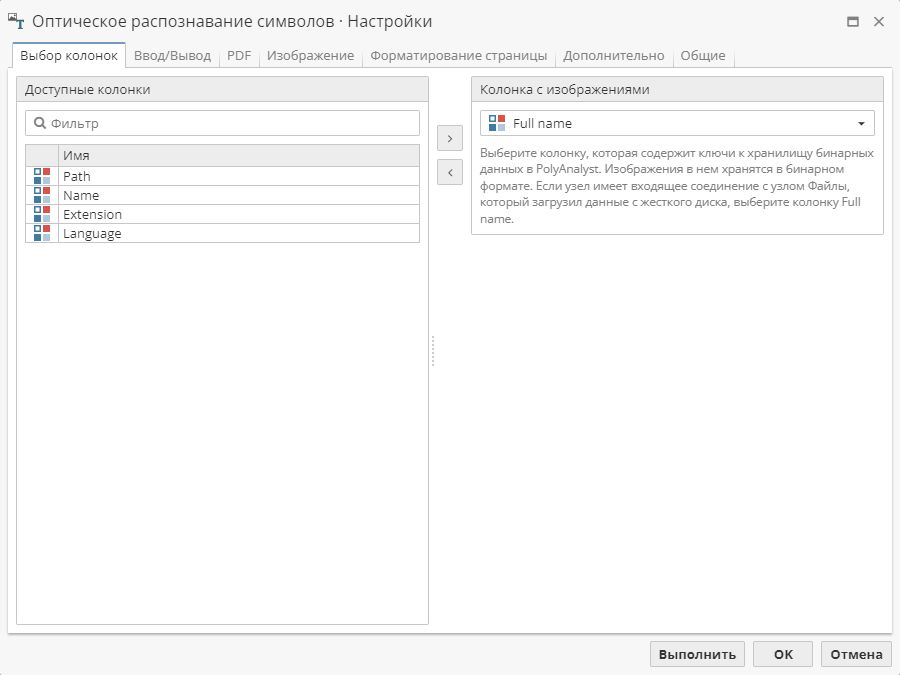
На первой вкладке выберите колонку, в которой содержатся ключи к бинарным данным. Для этого:
-
Выберите колонку в списке Доступные колонки и нажмите на кнопку с изображением стрелки, или
-
Нажмите дважды на имя колонки в списке Доступные колонки, или
-
Используйте выпадающее меню в разделе Колонка с изображениями.
| Если в качестве родительского узла выступает узел Файлы, необходимые ключи обычно хранятся в колонке Full name. В случае с узлом Изображения в колонке Image. Эти колонки выбираются автоматически в качестве Колонок с изображениями на вкладке Выбор колонок, что позволяет сразу выполнить узел, не открывая его настройки. |
Опции вкладки Ввод/Вывод
На второй вкладке устанавливаются дополнительные требования к работе узла.
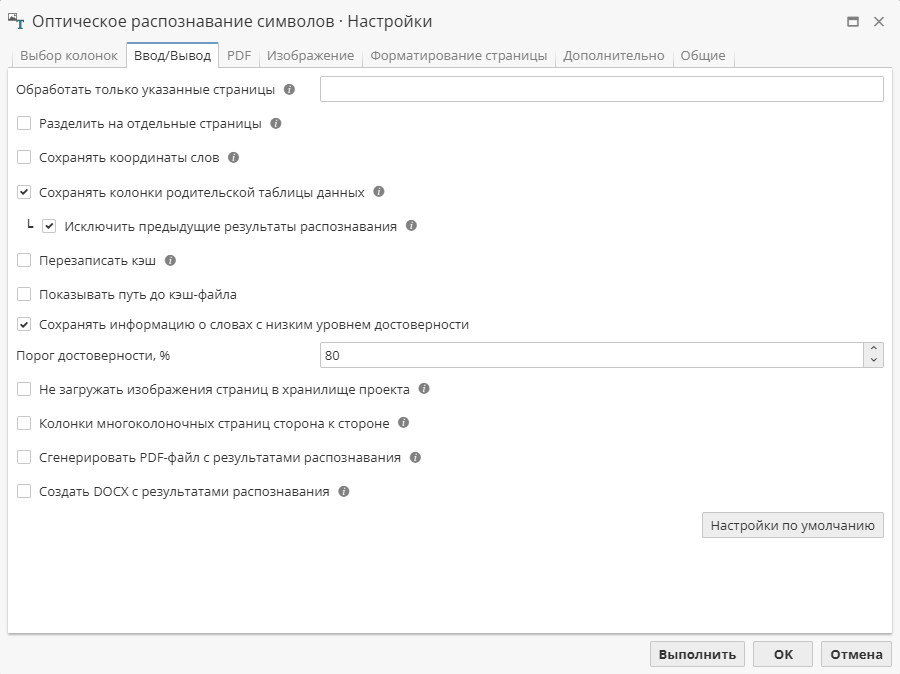
Для того чтобы обработать только часть многостраничного документа, введите в поле Обработать только указанные страницы необходимые номера страниц через запятую или используйте дефис для указания диапазона страниц (-3, 7-10, 15, 22, 33-). По умолчанию поле пустое.
Для отображения каждой страницы исходного документа в виде отдельной записи, отметьте галочкой опцию Разделить на отдельные страницы.
Опция Сохранять координаты слов используется в отдельных случаях для документов, содержащих таблицы, с целью включения дополнительной метаинформации в выходные данные. Содержимое связанной колонки (Coordinates) в дальнейшем можно использовать в комбинации последовательно расположенных узлов Индекс и Производная таблица.
Опция Сохранить колонки родительской таблицы данных чтобы отобразить колонки из родителького набора данных. По умолчанию опция активна.
Если вы подключили несколько узлов Оптического распознавания символов друг за другом, то в итоговом наборе данных вы увидете нескольких колонок, которые содержат служебную информацию: например сообщение об использовании OCR, комментарий, предупреждение и достоверность.
Эти колонки создаются автоматически при каждом использовании узла Оптического распознавания символов.
Чтобы удалить такие колонки из результатов, установите чекбокс Исключить предыдущие результаты распознавания.
Чтобы настроить узел на выполнение оптического распознавания без учета предыдущих результатов (даже при повторном выполнении узла), отметьте галочкой опцию Перезаписать кэш. Включение данной опции увеличит время обработки данных.
| При установке нового пакета DLC для узла Оптическое распознавание символов старые файлы кэша не используются для получения результатов, в связи с чем потребуется повторное выполнение процедуры распознавания. |
Отметьте галочкой опцию Показывать путь до кэш-файла для добавления в выходную таблицу данных колонки Cache folder, где будет указан путь до папки, в которой хранится соответствующий кэш-файл узла.
| В Административном клиенте доступна специальная опция, которая позволяет администраторам ограничить размер папки, в которой хранятся файлы кэша. Для этого необходимо перейти в раздел Настройки сервера, выбрать Сервер и указать значение в поле Максимальный размер каталога кэша для оптического распознавания символов. Значение по умолчанию – 102400 MB. При превышении установленного значения более старые файлы кэша удаляются (независимо от их источника). Соответствующая проверка выполняется при каждом обращении инструмента OCR к файлу, но не чаще одного раза в час. |
| Путь к папке c кэшом находится в папке "data" (папка по умолчанию) в директории сервера. Используйте параметр Путь к папке с кэшом в Административном клиенте, чтобы изменить папку, где будет храниться кэш OCR. |
По умолчанию в отчете узел автоматически выделяет (синим) неуверенно распознанные слова, т.е. опция Сохранять информацию о словах с низким уровнем достоверности включена. При необходимости пользователи могут изменить порог достоверности в соответствующем поле, либо вовсе отключить подобную подсветку.
Чтобы снизить размер проекта на диске используйте опцию Не загружать изображения страниц в хранилище проекта, при этом изображения страниц не будут показаны в отчёте узла OCR. Если в дальнейшем возникнет необходимость просмотреть отчёт с показом изображений, можно выполнить узел с отключенной опцией — распознавание не будет проводиться второй раз, результаты и изображения будут прочитаны из кэша.
Колонки многоколоночных страниц сторона к стороне – опция предназначена для страниц с несколькими столбцами текста. Если эта опция включена, такие столбцы размещаются в выходных данных в один ряд друг с другом с помощью пунктирной таблицы с одной строкой. Если этот параметр отключен, такие столбцы идут в порядке чтения — следующий под предыдущим.
Сгенерировать PDF-файл с результатами распознавания – создает файл PDF со строками и линиями, нарисованными в тех местах, где они были найдены системой распознавания. Файл сохраняется в отдельную колонку выходного датасета.
Кнопка Настройки по умолчанию позволяет восстановить исходные настройки для текущей вкладки.
Опции вкладки PDF
Опции третьей вкладки позволяют настроить условия выполнения оптического распознавания PDF-файлов.
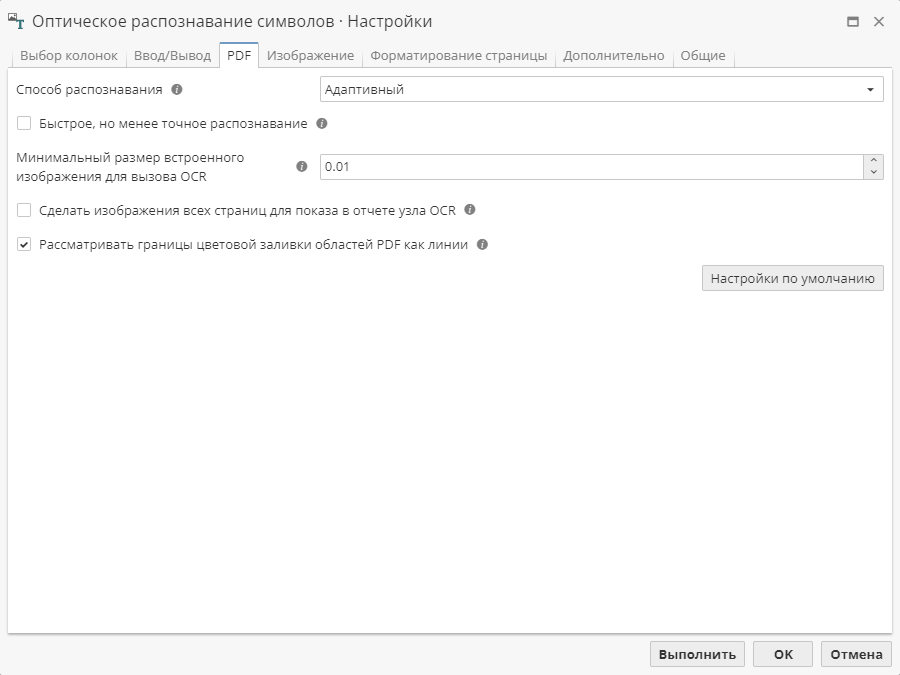
Способ распознавания PDF-документа имеет три режима:
-
Как изображение подходит для отсканированных документов или для документов со сложными метаданными. Файл будет распечатан в растровое изображение и подвергнут обработке методами узла.
-
Как текст распознает качественно и быстро правильно сформированные текстовые PDF-документы, которые не содержат отсканированные страницы. Файл будет проанализирован как текст/метаданные/скрипт PDF.
-
Адаптивный комбинирует два вышеперечисленных режима. Этот режим работает на уровне отдельных прямоугольных областей конкретной страницы, каждая область рассматривается отдельно. Из тех мест страницы, где нет встроенных изображений извлекаются метаданные, а к областям страницы, которые заполнены встроенными изображениями, применяется оптическое распознавание символов (OCR). Далее полученные результаты объединяются и производится их дальнейший анализ.
Быстрое, но менее точное распознавание – опцию удобно применять для наиболее простых случаев: текстовых PDF-файлов с простейшим форматированием или PDF-файлов, состоящих только из встроенных изображений (сканированных изображений). Опция может быть использована для следующих режимов распознавания: Адаптивный и Как текст. В режиме Адаптивный выбор режима распознавания делается на уровне целого файла, а не на уровне отдельных областей каждой страницы. В режиме Как текст используется более быстрый, но вместе с тем и более примитивный парсер PDF. Если опция включена, то все остальные опции на вкладке PDF становятся недоступны.
Минимальный размер встроенного изображения для вызова OCR – это отношение размера встроенного в страницу изображения к размеру самой страницы, ниже которого оптическое распознавание к данному изображению не применяется.
| Например, чтобы Адаптивный режим применял оптическое распознавание только к изображениям размером со всю страницу, нужно выбрать значение "1" или около "0.9". Чтобы оптическое распознавание было применено ко всем изображениям, нужно выбрать значение "0". |
Сделать изображения всех страниц для показа в отчете узла OCR – если опция включена, то страницы PDF будут напечатаны в изображения и появятся в отчёте выполнения узла OCR. Включение этой опции может замедлить процесс выполнение узла.
Рассматривать границы цветовой заливки областей PDF как линии – существует два основных способа рисования векторной графики (линий и контуров) в PDF: "обводка" и "заливка". Если данная опция выключена, то линиями считаются только обведённые (прочерченные) контуры. Если опция включена, то оба типа контуров считаются линиями, поэтому граница области другого цвета также считается линией.
Кнопка Настройки по умолчанию позволяет восстановить исходные настройки для текущей вкладки.
Опции вкладки Изображение
Вкладка Изображение используется для того, чтобы задать настройки распознавания текста, который дается в виде отсканированного изображения.
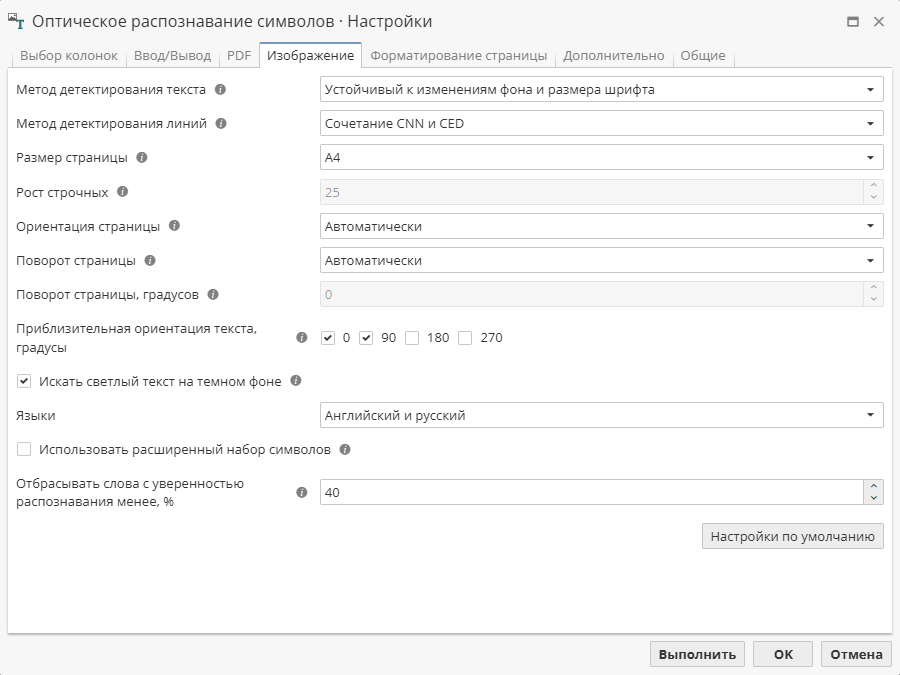
Представлено два метода детектирования текста:
-
Устойчивый к изменениям фона и размера шрифта
-
Для стандартных документов
Первый метод предполагает, что текст размещен на неоднородном фоне и шрифт текста может различаться от буквы к букве, например, это может быть текст на дизайн-макете рекламного объявления или изображение с водяными знаками.
Второй метод направлен на распознавание "стандартного" текста, который представлен в виде изображения (на однородном фоне и без изменений шрифта).
Выпадающее меню Mетод детектирования линий позволяет настроить параметры распознавания линий. В настоящее время доступны следующие методы:
-
Сверточная нейронная сеть (CNN)
-
Детектор границ Канни
Первый метод основан на использовании сверточной нейронной сети – нейронной сети, которая основана на принципах распознавания образов человеческим глазом и предназначена для работы с изображениями. Более подробную информацию см. здесь.
Детектор границ Канни представляет собой алгоритм, который используется для распознавания краев изображения: внутренних и внешних границ объекта.
По умолчанию выбран комбинированный метод распознавания.
Размер страницы для распознавания устанавливается через выпадающее меню Размер страницы, по умолчанию выбрано значение A4 (стандартная страница). Доступны следующие опции:
-
Авто – размер будет определен автоматически (значение по умолчанию).
-
По росту строчных – за размер текста берется высота буквы "x" в нижнем регистре.
-
Одна строка – размер одной строки будет считаться за размер страницы, например, в том случае, когда на изображении имеется только одна строка текста.
-
Формат Letter – Североамериканский формат страницы (215,9 на 279,4 мм или 8,5 на 11 дюймов).
-
Формат Legal – Североамериканский формат страницы (216 на 356 мм или 8.5 на 14 дюймов).
-
Формат Tabloid – газетный формат (279 на 432 мм или 11 на 17 дюймов).
-
Форматы A-размеров – международный формат бумаги различных размеров.
Размер страницы можно задать с помощью параметра Рост строчных (x-height), который представляет собой размера буквы в нижнем регистре, основанный на размере буквы "x".
Для настройки положения страницы используются еще два параметра: Ориентация страницы и Поворот страницы. Если для параметра Поворот страницы установлено значение "Фиксированный размер", вы можете задать степень поворота страницы вручную.
Опция Искать светлый текст на темном фоне используется для распознавания текста на темных областях изображения.
Отметьте возможный поворот текста в поле Приблизительная ориентация текста, градусы.
Функция Проверять на перевернутый текст используется для лучшего распознавания повернутых строк, например, когда текст расположен не по горизонтали и/или вертикали, а по диагонали.
Узел поддерживает два языка распознавания: Английский и Русский. Данные языки можно выбрать как отдельно, так и вместе (Английский и русский) в поле Языки.
Включите опцию Использовать расширенный набор символов если необходимо использовать модель распознавания текста с расширенным набором символов: греческие буквы, некоторые научные и финансовые символы. Опция доступна только, если выбраны Английский и русский языки.
Опция Отбрасывать слова с уверенностью распознавания менее, %, используется для получения "чистых" данных: те слова, которые были распознаны с более низким, чем указанный, уровнем достоверности, не будут отображаться как распознанные в результирующей таблице.
Настройка вкладки Форматирование страницы
Вкладка Форматирование страницы позволяет настроить параметры страницы документа.
По умолчанию узел выполняет комплексный анализ структуры документа в режиме Проверять на несколько колонок текста. Не рекомендуется использовать данную опцию, если исходный документ не отличается сложной структурой и представляет собой один столбец текста.
На вкладке также представлены настройки распознавания таблиц. Для этого воспользуйтесь выпадающим меню Метод распознавания таблиц. Доступны следующие опции:
-
Только по линиям – таблица распознается по линиям.
-
Сначала по линиям, затем по выравниванию текста – таблица распознается по линиям, затем по положению текста.
-
По линиям и выравниванию текста одновременно – таблица распознается по линиям и по положению текста.
-
Не искать таблицы – распознавание таблиц отключено.
Чтобы запретить распознаваение линий (включая те, которые представляют границы таблиц), установите флажок Игнорировать все графические линии.
Настройка вкладки Дополнительно
Вкладка Дополнительно используется для настройки параметров производительности узла.
Узел может выполнять анализ, используя различное количество процессорных ядер. Вы можете задать количество ядер, чтобы изменить скорость распознавания текста. Для этого заполните поле Количество потоков. Если установлено значение 0, то PolyAnalyst самостоятельно выделит количество процессорных ядер для выполнения узла.
На вкладке также предусмотрено использование экспериментальных опций:
-
Дополнительный поиск дефисов – опция предназначена для лучшего распознавания дефисов; дефис часто стоит между буквами и может создавать дополнительный "шум" при распознавании текста, что, следовательно, может повлиять на результаты распознавания.
-
Проверять на печатные формы из пунктирных линий – опция предназначена для лучшего распознавания пунктирной линии, такая линия может состоять из точек и/или тире; это может быть полезно при распознавании контрактов или других видов официальных документов.
-
Проверять на печатные формы из сплошных линий – опция предназначена для лучшего распознавания сплошной линии; например. это может быть полезно при распознавании текста со сложной структурой, где части текста разделены горизонтальными или вертикальными линиями.
-
Проверять на наличие ложных вертикальных линий – опция предназначена для распознавания вертикальных линий; наличие вертикальных линий может ухудшить результаты распознавания текста, например, при плохом качестве отсканированного изображения.
Поле Учитывать при поиске таблиц ключевые слова позволяет вам ввести ключевую фразу для заголовка таблицы, что поможет алгоритму распознать таблицу с заданным заголовком.
Опции вкладки Общие
Вкладка Общие обычно используется для изменения имени узла и добавления описания.