Настройка вкладки Общие
Вкладка Общие в окне свойств узлов выглядит примерно одинаково для всех узлов в PolyAnalyst. Ниже для примера представлен скриншот вкладки Общие узла Файлы CSV.
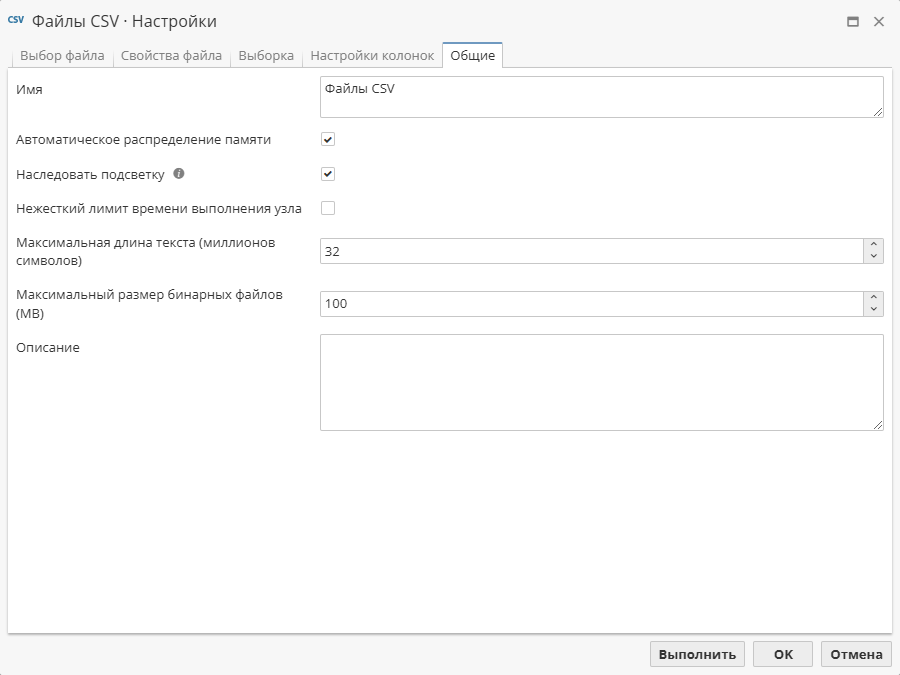
Данная вкладка включает ряд опций, которые могут незначительно отличаться в зависимости от узла. Все настройки на вкладке Общие являются необязательными.
Как правило, данная вкладка включает следующие опции:
Опция Имя (имя узла)
Текстовое поле Имя используется для именования узла. Рекомендуется присваивать узлам такие названия, которые отражают задачи узлов. Это позволяет как пользователю, создавшему узел, так и его коллегам впоследствии быстро понять назначение данного узла в проекте. Например, узел Интернет можно назвать именем сайта, содержимое которого он извлекает. По умолчанию в этом поле выставляется название узла, которое используется в Палитре узлов.
Пользователь может переименовать узел позже.
| Обратите внимание, что число символов в имени узла ограничено: вы можете использовать максимум 1000 символов; в противном случае настройка имени узла не будет сохранена. |
Опция Автоматическое распределение памяти
По умолчанию эта опция включена. Некоторые узлы не имеют этой опции, поскольку невозможно напрямую управлять памятью, доступной для этих узлов. Данная опция используется для настройки поведения узла. Некоторые узлы имеют дополнительные настройки памяти (Административный клиент > Настройки сервера > Настройки нового пользователя Настройки проекта по умолчанию > Настройки узлов по умолчанию). Другие узлы используют Объем памяти, доступной для отдельного узла в настройках проекта по умолчанию.
Опция Автоматическое распределение памяти определяет то, как сервер PolyAnalyst распределяет виртуальную (оперативную) память для выполнения обработки данных в узле. Если эта опция включена, PolyAnalyst будет динамически оценивать потребность узла в памяти в ходе обработки, а затем распределять память по необходимости. Если опция отключена, PolyAnalyst использует настройки памяти, которые являются частью настроек проекта и настраиваются через меню Настройки в самом проекте. Это статическая или постоянная настройка, она относится ко всем узлам в проекте, в то время как опция Автоматическое распределение памяти настраивается для каждого узла.
Если вся память, доступная для сервера PolyAnalyst, не используется полностью, то данная опция почти не влияет на производительность узлов. Эта опция имеет значение только тогда, когда используется вся доступная память и когда память распределяется между несколькими операциями.
Если вы не знаете, какой объем памяти доступен для использования, или не испытываете проблем с производительностью, то эту опцию можно проигнорировать.
Опция Наследовать подсветку
Данная настройка на вкладке Общие присутствует всегда. Она позволяет узлам-датасетам наследовать подсветку текста из родительских узлов.
Наследование подсветки позволяет пользователю на более поздних этапах проекта быстро понять, что какой-то текст оказался в дочерней таблице только потому, что в нем ранее были обнаружены какие-то последовательности символов.
Несмотря на то, что действие этой опции мы непосредственно можем наблюдать лишь в узлах текстового анализа, по умолчанию она подключена для всех узлов. Если в каком-то узле в цепочке узлов отключить ее, то наследование подсветки текста прекратится.
Опция Нежесткий лимит времени выполнения узла
Данная опция присутствует практически во всех узлах-источниках данных, а также в некоторых других, например, в узле анализа данных Анализ ближайших соседей. Такие узлы выполняют итеративную, цикличную обработку данных.
Если подключить эту опцию, узел будет знать, что время его выполнения ограничено. В таком случае, если данные будут обрабатываться слишком долго, узел постепенно прекратит работу. Пользователь в подобной ситуации осознанно принимает решение о том, что он будет довольствоваться неидеальным результатом в угоду экономии времени при обработке данных.
Опция Кэшированный результат
Данная опция применяется не во всех узлах в системе PolyAnalyst.
Кэширование результатов узлов позволяет ускорить загрузку данных в окно просмотра результатов этих узлов. По умолчанию большинство узлов не выполняют кэширования, поскольку для этого может потребоваться хранение большого количества избыточных данных.
PolyAnalyst оптимизирует процесс хранения выходных данных узлов.
Хранение ID записей в последующих узлах, как показано в приведенном выше примере, позволяет существенно экономить дисковое пространство. Это становится очевидно, если представить, что вместо всех значений одной записи в узле сохраняется лишь одно значение. Однако такой подход имеет один недостаток: полный вид каждой записи должен воссоздаваться заново всякий раз при просмотре результатов узла, а это происходит медленнее по сравнению с отображением готовой записи.
Если вы работаете с относительно небольшим набором данных, и у вас много свободного места на диске, вы, возможно, пожелаете, чтобы результаты узлов отображались максимально быстро. Вы можете добиться этого, включив опцию Кэшированный результат для некоторых узлов.
Для того, чтобы кэшировать результат узла, отметьте галочкой опцию Кэшированный результат на вкладке Общие во время настройки узла, затем выполните узел заново. Результат узла теперь будет сохраняться в кэше. Позже вы в любой момент можете отключить данную опцию для экономии места на диске.
Кэширование результата невозможно в узлах-источниках данных, которые импортируют данные. Импортируемые данные всегда копируются. Экономия рабочего пространства диска возможна в PolyAnalyst только в узлах, не являющихся источниками данных.
|
Доступ к данным таблиц замедляется вместе с увеличением длины цепочки от узла, который запрашивает колонку, до узла, в котором эта колонка определена (один из узлов-источников данных, Производные колонки, Агрегирование, Производная таблица и др). Степень замедления зависит и от того, какие узлы находятся между источником данных и их потребителем. Если же кэшировать результат какого-то узла, то он сам превращается в источник данных и цепочка получения данных на нем останавливается. В связи с этим, мы рекомендуем кэшировать результаты нескольких узлов в некоторых ключевых точках скрипта, например, в тот момент, когда с данными закончены все преобразования и начинается стадия анализа. Также мы рекомендуем кэшировать узлы и на этапе подготовки данных, например, каждый 4-ый, или 8-ой - в зависимости от того, скольким свободным местом на диске пользователь готов пожертвовать в угоду увеличению производительности программы. |
|
При подключении опции Кэшированный результат, кэшируются только сами данные узла, а все остальное - индексы, подсветка и прочая служебная информация - не сохраняется. Если использовать какой-то узел текстового анализа после кэшированного узла, то про все необходимые индексы, созданные ДО него, система не узнает, и будет создавать их снова, как будто их и не было. Во-первых, на повторную индексацию крупных таблиц потребуется дополнительное время. Во-вторых, это может привести к различным неожиданным результатам. |
Опция Описание (описание узла)
Текстовое поле Описание может быть использовано для того, чтобы пользователь мог добавить собственное описание узла. Например, здесь можно вкратце описать, что уже сделано, и что предстоит сделать с помощью данного узла, прокомментировать его настройку или неожиданные результаты, и др.