Настройка колонок при импорте данных
В данном разделе рассматривается настройка опций парсинга данных в CSV-файлах. Однако данная информация применима к любой ситуации, когда PolyAnalyst импортирует значения из любого источника данных, и эти значения не соответствуют типам данных, используемых в системе PolyAnalyst.
Настройка автоматической конвертации и/или распознавания колонок в PolyAnalyst
CSV-файлы не хранят информацию о типе данных, например, в файле нет информации о том, содержит ли колонка числовые данные, даты или строковые данные. Все программные средства, импортирующие CSV-файлы, сталкиваются с этой проблемой. PolyAnalyst использует особую систему распознавания типа каждой колонки на основе результатов сканирования нескольких первых значений в колонке. Эта система может допускать ошибки, и пользователям иногда приходится корректировать тип данных в некоторых колонках.
Многие пользователи часто забывают об этом, либо воспринимают подобные случаи как неисправимые программные ошибки. Рекомендуется просматривать и, в случае необходимости, корректировать тип данных в колонках импортируемой таблицы непосредственно перед импортом, вместо того чтобы полностью полагаться на автоматическое распознавание типов данных в PolyAnalyst.
Чаще всего автоматическое распознавание типов данных выполняется корректно, но иногда возникает необходимость вмешательства пользователей в этот процесс. Вы можете помочь алгоритму распознавания типа данных, который пытается установить исходный тип данных для каждой колонки исходных данных, одним из следующих способов:
-
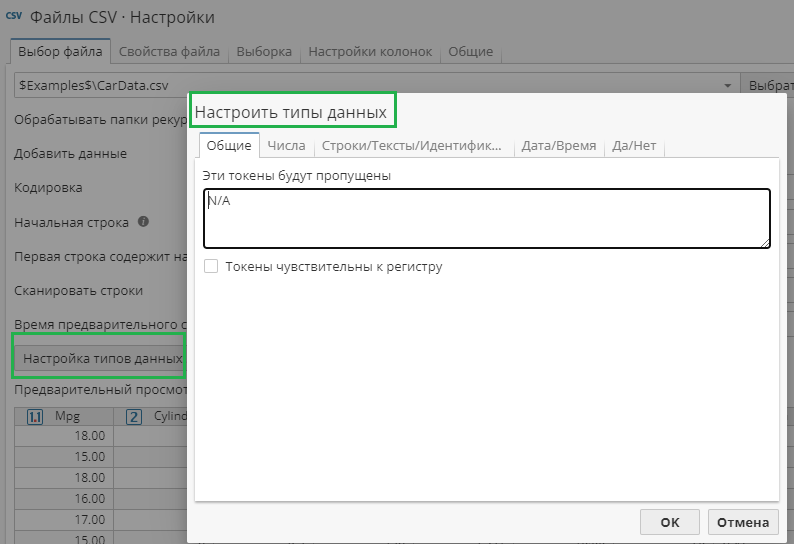
для определения общих настроек всей таблицы данных - нажав на кнопку Настройка типов данных на вкладке Выбор файла (например, в узлах-источниках данных Файлы CSV, JSON, Lotus и XML;
-
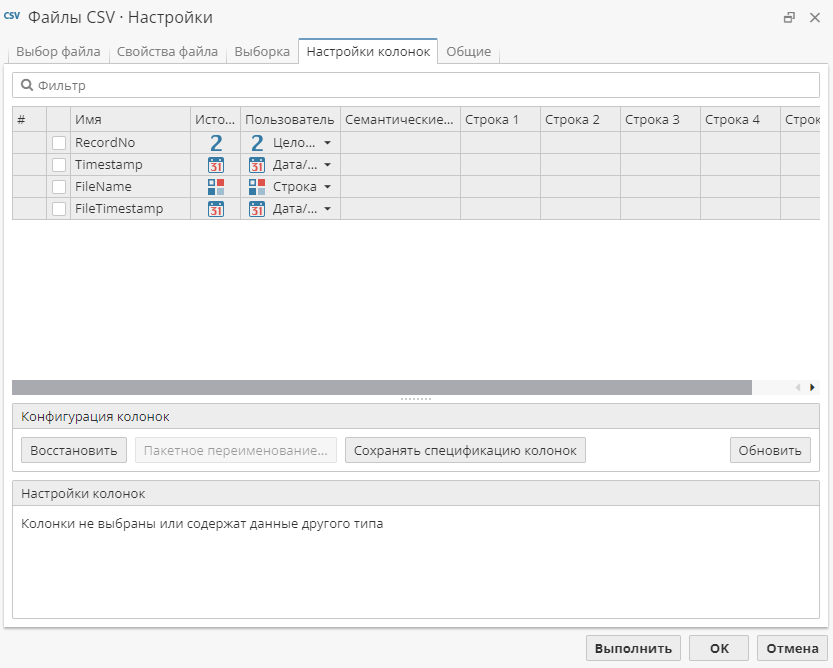
для определения настроек для каждой колонки таблицы - перейдя на вкладку Настройки колонок (в других узлах-источниках данных).
| В узлах-источниках данных Файлы CSV, JSON, Lotus и XML доступны оба варианта настройки колонок, однако параметры на вкладке Настройки колонок имеют приоритет. |
| Данную настройку не следует путать с фактической установкой типа данных, которая выполняется позже на вкладке Настройки колонок. Эта группа опций предназначена для настройки методов, которые используются по умолчанию для распознавания типов данных, и того, как PolyAnalyst выполняет парсинг числа, даты и др. |
Настройка типов данных (вкладка Выбор файла)
При нажатии на кнопку Настройка типов данных на вкладке Выбор файла откроется диалоговое окно, которое разбито на несколько вкладок: Общие, Числа, Строки/Тексты/Идентификаторы, Дата/Время и Да/Нет:
Общие

На вкладке Общие в специальном текстовом поле укажите значения, которые PolyAnalyst должен игнорировать при импорте. Эти значения будут пропущены во всех колонках независимо от типа данных. Введите по одному значению на строку в текстовом поле. Количество значений, которые можно игнорировать, не ограничено. Отметьте опцию Токены чувствительны к регистру для того, чтобы PolyAnalyst распознал разные формы написания значений, которые нужно игнорировать.
Данная опция дает пользователям возможность выбирать, имеет ли регистр значение при сравнении значений в списке и реальных значений данных.
Числа
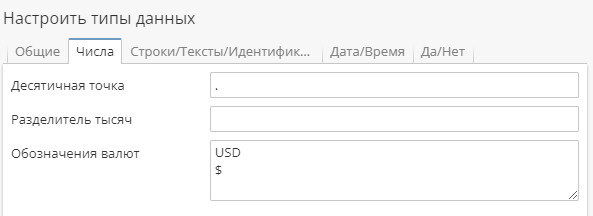
На вкладке Числа пользователи могут настроить обозначения валют, а также символы, используемые для десятичных дробей и в качестве разделителей тысяч.
Десятичные точки и разделители тысяч необходимо настраивать только тогда, когда числовые данные хранятся с использованием других символов. Не все цифровые системы мира используют запятую "," для обозначения десятичной доли, иногда в качестве десятичного и тысячного разделителя используется точка ".".
Строки/Тексты/Идентификаторы
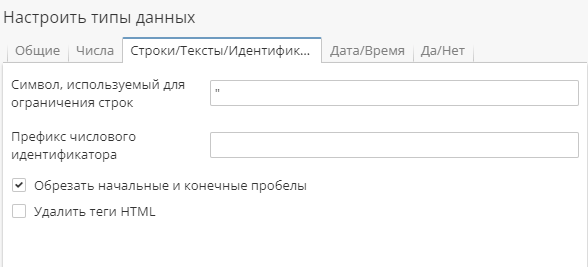
На вкладке Строки/Тексты/Идентификаторы укажите символ, обозначающий кавычки.
Кавычки могут быть одинарными или обратными. Обычно в CSV-файлах используются стандартные кавычки, но некоторые системы не следуют этому стандарту, и иногда возникает необходимость дополнительно указывать символ кавычек.
-
Отметьте опцию Обрезать начальные и конечные пробелы для автоматического удаления пробелов в начале и в конце любого значения. Это могут быть собственно пробелы, разрыв строки и знаки табуляции. Иногда CSV-файлы хранят эти дополнительные символы вместе со значениями, но в PolyAnalyst обычно эти дополнительные разделители перед значениями и после них не являются значимыми, и их не следует использовать. Пробелы сохраняются только тогда, когда они входят в само значение, но это встречается редко. Обрезание пробелов также сокращает место, занимаемое при хранении значений во внутренней базе данных PolyAnalyst, и значительно облегчает работу с большими объемами данных.
-
При указании Префикса числового идентификатора данные в CSV-файл будут импортироваться без указанного префикса.
Вышеуказанная опция действительна для типа данных "Числовой идентификатор". Аналогичная настройка возможна для отдельных колонок во вкладке Настройки колонок.
Дата/Время
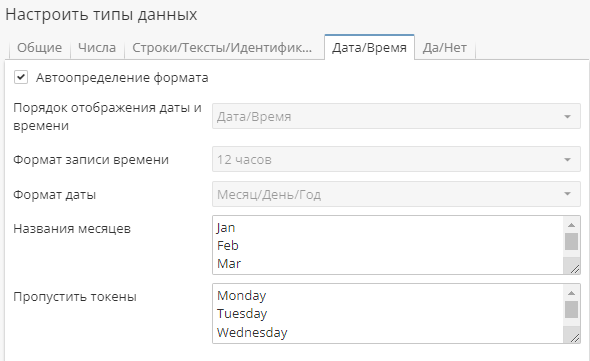
На вкладке Дата/Время настройте то, как PolyAnalyst должен распознавать значения даты в CSV-файлах.
-
Опция Порядок отображение даты и времени определяет, в каком порядке PolyAnalyst распознает значения: дата/время или время/дата, поскольку системы отличаются по способу хранения подобных данных.
-
Формат записи времени может быть 12-часовым (AM и PM) или 24-часовым.
-
Формат даты может быть настроен в зависимости от порядка отображения месяца, года и дня.
-
При включении опции Автоопределение формата вышеуказанные опции выпадающего списка, а также их аналоги на вкладке Настройки колонок становятся неактивными – PolyAnalyst будет использовать встроенный алгоритм распознавания соответствующего формата. PolyAnalyst также может импортировать даты, в которых содержатся не только цифры, поскольку названия месяцев также распознаются.
-
Поле Названия месяцев содержит список названий месяцев, которые PolyAnalyst может распознать.
-
Поле Пропустить токены содержит значения внутри колонок даты/времени, которые PolyAnalyst должен игнорировать. По умолчанию в данном списке присутствуют названия дней недели, поскольку стандартный формат записи даты понедельник, 01/01/2000 уже содержит название дня недели, и его не нужно распознавать.
| Помните, что даты могут быть импортированы как строковые данные, а затем конвертированы с помощью SRL-выражения в узле Производные колонки. |
Да/Нет
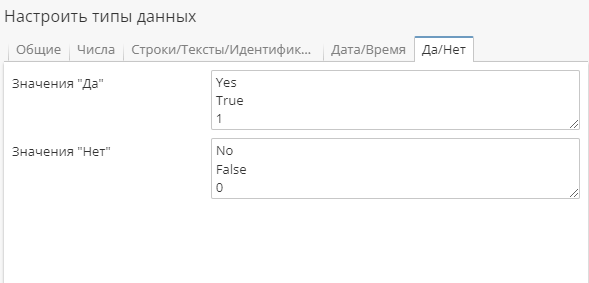
На вкладке Да/Нет введите значения, представляющие значения "истина" и "ложь" в соответствующих текстовых полях.
В CSV-файлах стандарта хранения булевых данных не существует, и системы, генерирующие CSV-файлы, могут хранить данные в виде "да" и "нет", "1" и "0", или "истина" и "ложь". Если настроить эту вкладку правильно, PolyAnalyst сможет распознать любые представления таких данных и импортировать их как истинные или ложные. Вы можете дополнить или отредактировать имеющийся список. В каждом поле значения вводятся по одному на строку.
Вкладка Настройки колонок
Большинство узлов-источников данных также имеют вкладку Настройки колонок, где можно настроить типы данных в колонках. Вкладка Настройки колонок выглядит следующим образом:
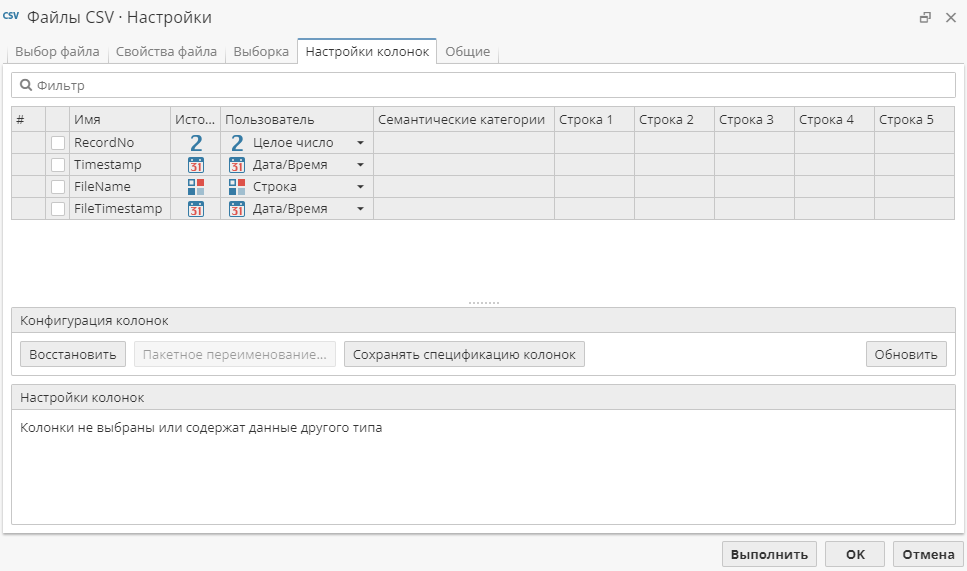
Чтобы изменить тип колонки при импорте данных:
-
Переключитесь на вкладку Настройки колонок. Возможно, вам придется нажать на кнопку Обновить идля того, чтобы в таблице предварительного просмотра в верхней части вкладки отобразились все колонки исходной таблицы данных. В противном случае таблица может содержать только следующие три новые колонки, которые добавлены в результаты узла, если отметить их галочками (их также можно переименовать и изменить тип данных):
-
RecordNo (номер записи) - данная колонка может быть полезна, когда таблица данных не содержит первичного ключа (т.е. в ней нет отдельной колонки с номерами записей), но необходима возможность ссылаться на конкретные записи. Эта новая колонка может служить в качестве первичного ключа, уникально определяя каждую запись просто путем сохранения ее порядкового номера: первой записи присваивается номер 1, второй – номер 2, и т.д. После того, как колонка с номерами записей будет добавлена в выходные данные, вы можете обращаться с ней, как с любой другой колонкой данных, как если бы она изначально хранилась в данных.
-
Timestamp (временная отметка) - работает по тому же принципу. В данной колонке содержится время и дата выполнения узла;
-
FileName (имя файла) - может пригодиться в том случае, если вы выбираете для импорта несколько файлов или папку с файлами, и вам нужно посмотреть, из какого файла взята конкретная запись;
Настройка колонки FileName доступна только в узлах Файлы CSV, E-Mail Архив, JSON, Lotus, Microsoft Excel, SPSS и XML.
-
-
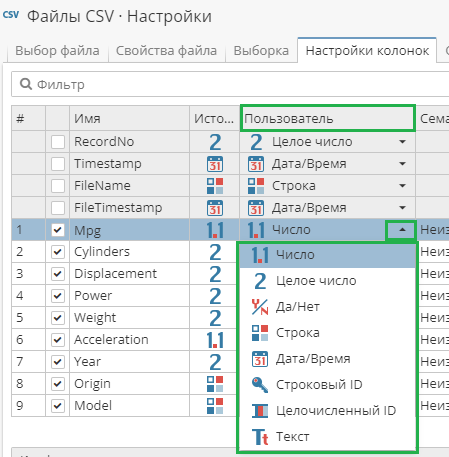
В колонке Пользователь нажмите левой кнопкой мыши на текущий тип данных для вызова выпадающего меню.
-
Выберите новый тип данных из списка:
-
Нажмите кнопку Обновить чтобы увидеть, как будут импортированы значения колонок. В колонках Строка 1 – Строка 5 справа можно предварительно просмотреть измененные типы данных.
Для настройки нескольких колонок одновременно, выберите несколько колонок в области предварительного просмотра, используя клавиши CTRL или SHIFT.
| Обратите внимание, что некоторые свойства колонок могут быть отключены. Активны только те свойства колонок, которые могут быть отредактированы для всех колонок одновременно (например, вы не можете переименовать две колонки сразу, поэтому возможность настройки имени отключается при выборе нескольких колонок). |
Для отмены любых внесенных вами изменений нажмите на кнопку Восстановить. На экране появится окно подтверждения действия, после чего будут восстановлены настройки колонок по умолчанию.
При импорте данных важно правильно выбрать имя для колонки. Когда вы будете настраивать другие узлы для использования импортированных данных, вы будете ссылаться на колонки в данных по имени. Неудобство возникает тогда, когда пользователи возвращаются к настройкам импортирующего узла, чтобы переименовать одну из колонок после того, как настроили несколько других узлов на работу с этой колонкой. Поскольку в настройках последующих узлов проекта уже используется конкретное имя колонки, изменение этого имени приведет к тому, что настройки узлов окажутся некорректными. После переименования колонки вам придется возвращаться к настройкам каждого узла проекта, следующего за узлом, выполнившим импорт, и указывать измененное имя колонки. Этого можно избежать, если на каждом этапе анализа указывать имена колонок, вместо того, чтобы переименовывать колонки постфактум, т.е. после того, как последующие узлы уже настроены. Вы также можете переименовать колонки позже с помощью узла Модификация колонок.
Дополнительные настройки колонок
При выделении колонки в списке колонок в нижней части вкладки открываются дополнительные настройки колонок.
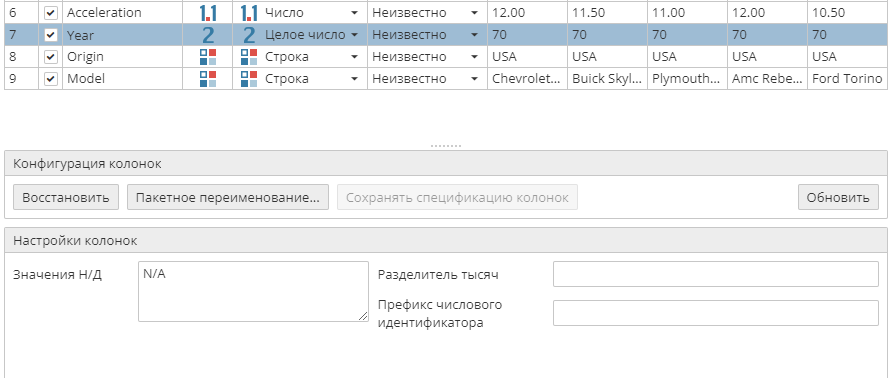
Состав этих настроек может зависеть от типа данных выделенной колонки.
Фильтрация значений колонок
Поле Значения Н/Д содержит список значений, которые узел игнорирует и/или приводит к нулю в ходе импорта.
Иногда CSV-файлы содержат данные, в которых ноль представлен ненулевым способом. Хорошо было бы, если бы ячейка в таблице в случае нулевого значения оставалась пустой, но не все программные продукты соответствуют такому стандарту, поэтому пользователю иногда приходится конвертировать представления нулевых значений в действительные нулевые значения. Кроме того, пользователи могут использовать данное поле для фильтрации любых ненужных классов, категорий или числовых значений из данных во время импорта. Пользователи должны быть осторожны, поскольку это может привести к искажению данных, которые будут проанализированы далее в ходе проекта. В связи с этим подобная фильтрация значений в ходе импорта данных не должна быть единственным способом решения проблемы отсутствующих значений. Пользователи могут использовать последующий узел Аудит данных для исследования пропущенных, аномальных значений или настройки специальных опций для работы с отсутствующими значениями в зависимости от алгоритма (описания опций представлены в разделах, посвященных конкретным аналитическим узлам).
Исключение колонок при импорте данных
При создании и настройке нового узла-источника данных, все колонки включаются в выходные данные узла по умолчанию. Вы можете исключить отдельные колонки из результата в ходе загрузки данных, используя вкладку Настройки колонок узла-источника данных.
Чтобы исключить колонку из выходных данных, перейдите на вкладку Настройки колонок и снимите выделение с чекбокса слева от имени соответствующей колонки:
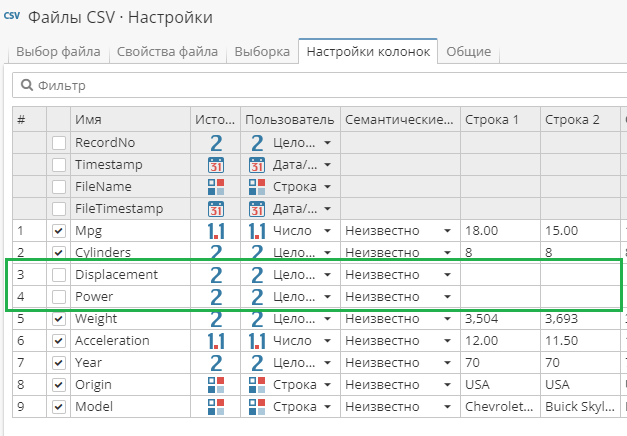
Для того, чтобы вернуть колонки в выходную таблицу, снова отметьте соответствующие чекбоксы.
В области предварительного просмотра на вкладке Выбор файла исключенные колонки выделены серым цветом:
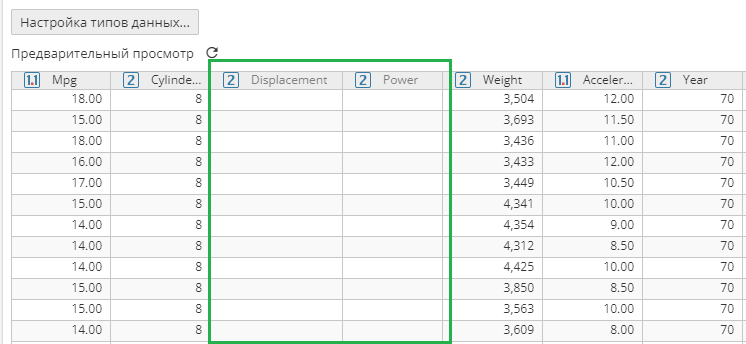
Если колонка исключена из выходных данных, вы не сможете изменить ее настройки на данной вкладке, поскольку предполагается, что если вы исключаете колонку, необходимости в ее настройке нет.
Переименование нескольких колонок
Для переименования одной или нескольких колонок в таблице выделите их на вкладке Настройки колонок и нажмите на кнопку Пакетное переименование….
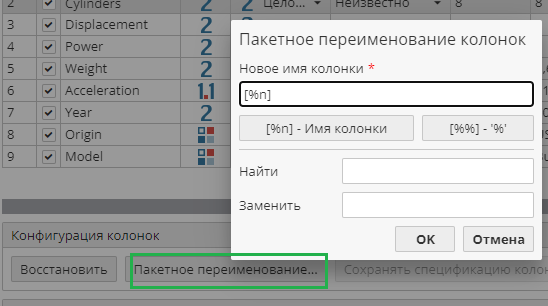
Введите новое имя в текстовом поле Новое имя колонки. Кнопки, расположенные под текстовым полем, позволяют использовать шаблоны в процессе пакетного переименования колонок. Кнопка слева позволяет вставить в новое имя колонки ее существующее имя (в квадратных скобках) и редактировать его. Кнопка справа позволяет добавить какие-то специальные знаки к новому имени, например, знак %. Пользователь также может выбрать, должен ли дополнительный знак отображаться перед именем колонки, или за ним.
Кроме того, поля Найти и Заменить могут быть использованы для того, чтобы заменить отдельные символы или их сочетания в названиях колонок. Например, можно суффикс _1 в названиях нескольких исходных колонок заменить на суффикс _2.
По окончании настройки нажмите ОК. Новое имя колонок будет отображено в колонке Имя в области предварительного просмотра. В ходе выполнения узла оно будет применено ко всем выбранным колонкам.
Можно переименовать колонки после импорта с использованием других операций PolyAnalyst, поэтому не обязательно выбирать окончательное имя для колонки в ходе импорта.
Обработка процентных значений в PolyAnalyst
Существует три варианта того, как PolyAnalyst должен обрабатывать процентные значения, а именно:
-
как десятичное значение числового типа данных;
-
как целую часть числа с использованием знака процента;
-
как обычную строку, также с использованием знака процента.
Таким образом, по умолчанию, когда вы вводите процентное значение, например 56%, оно будет преобразовано в 0,56.
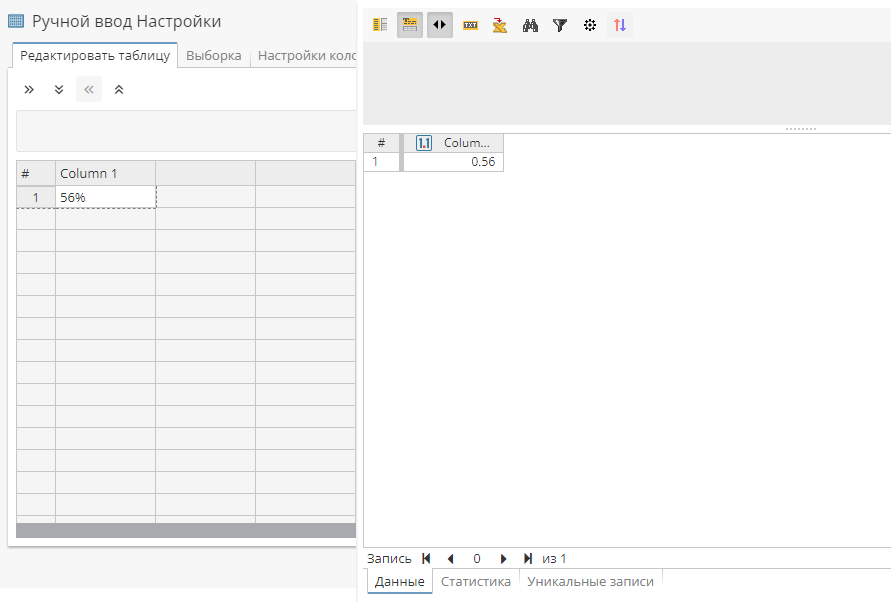
Вы можете просто изменить тип данных, преобразовав значение в строку. Это можно сделать на вкладке Настройки колонок:
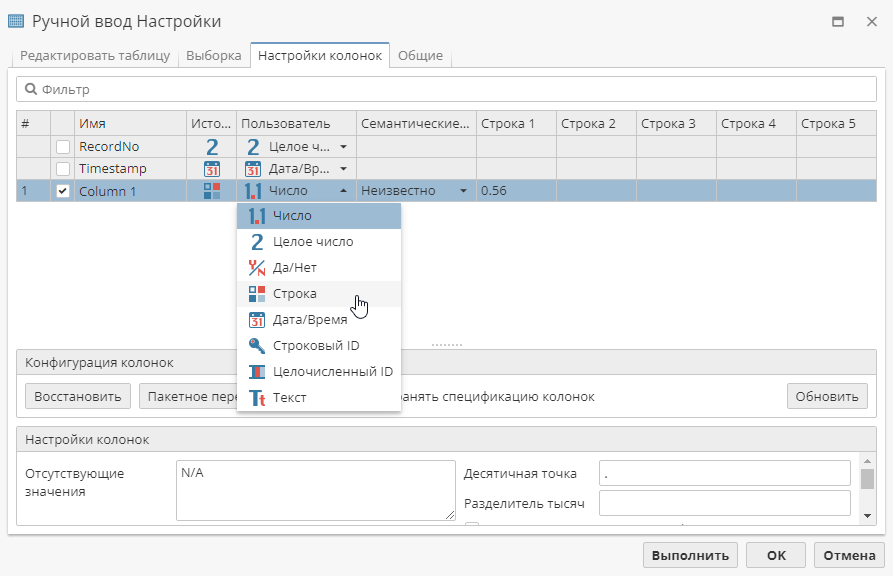
| В данном случае мы использовали узел Ручной ввод в качестве примера. |
Другим способом обработки процентных значений является использование знака процента с заданным числом, например, значение, которое мы использовали в приведенных выше примерах, будет показано как 56% и иметь числовой тип данных. Для этого вам необходимо выполнить следующие несколько шагов по настройке региональной конфигурации колонок:
-
Откройте окно просмотра узла, с которым вы работаете, и щелкните левой кнопкой мыши на опцию Открыть региональные настройки
-
Выберите необходимую колонку, откройте вкладку Региональные настройки и задайте поля Множитель, Формат положительных чисел и Формат отрицательных чисел, как показано ниже.
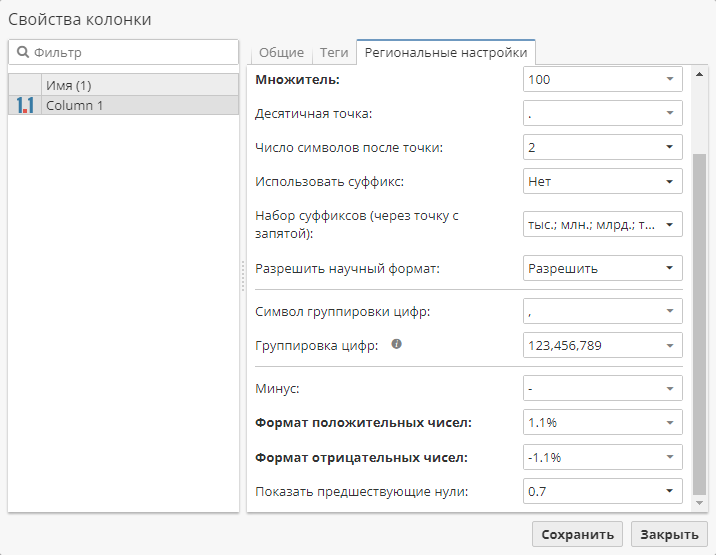
Вы также можете установить количество цифр, которые будут отображаться после десятичной точки в соответствующем поле, чтобы настроить отображение конечного значения, например, 56% или 56,00%.