Настройка узла Интернет
Окно настроек узла Интернет разбито на следующие вкладки:
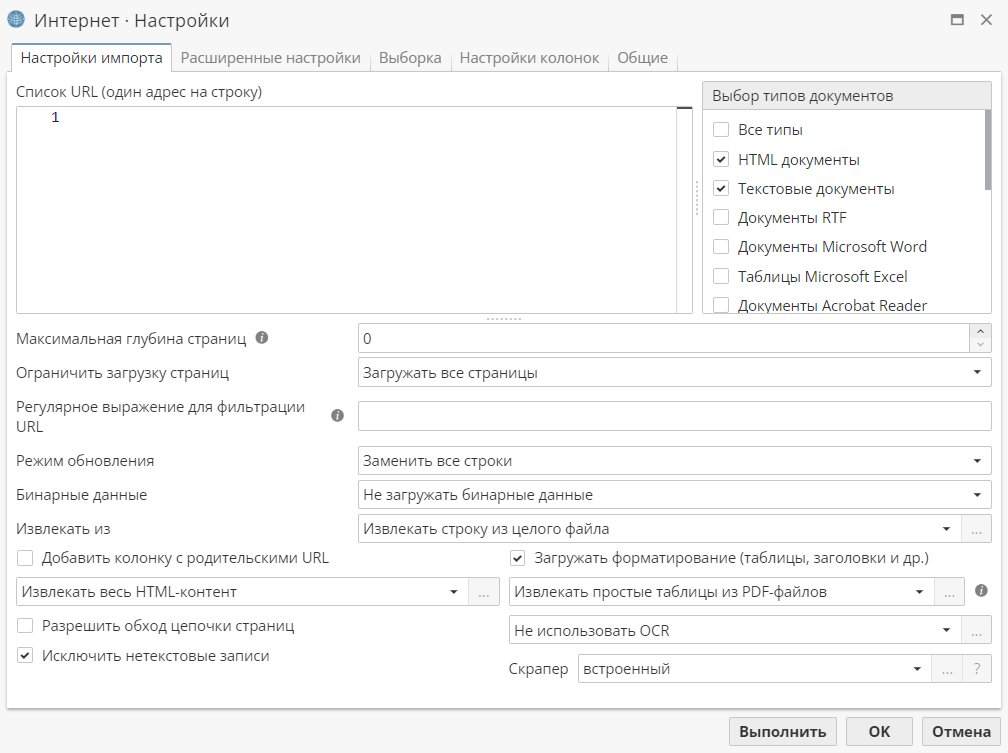
-
Настройки импорта – основная вкладка, используется для ввода параметров работы узла;
-
Расширенные настройки – дополнительные настройки узла;
-
Выборка – используется для ограничения количества записей в выходной таблице данных;
-
Настройки колонок – используется для изменения свойств колонок выходной таблицы данных;
-
Общие – используется для изменения имени и описания узла.
Как правило, настройка вкладок осуществляется слева направо. Основные параметры представлены на вкладке Настройки импорта (см. скриншот выше).
Настройка списка URL
URL (от англ. Uniform Resource Locator) – унифицированный определитель/механизм указания местонахождения ресурсов. Обычно URL указывает на конкретную веб-страницу. Примером URL является http://www.megaputer.com/solutions/. Таким образом, URL – это адрес веб-сайта, который вы хотите посетить, и который вы набираете в строку браузера при использовании сети Интернет.
Узел Интернет принимает любое количество начальных URL. Начальные URL – это исходные точки, с которых алгоритм начинает сбор данных. Веб-страницы соединены между собой гиперссылками. Алгоритм совершает обход содержимого веб-страниц, переходя по этим ссылкам, от страницы к странице. В этом случае можно использовать сравнение с паутиной. Представьте себе, что вы находитесь в сети в определенной точке, а затем переходите по различными линиям сети, чтобы посетить другие точки, подобно тому, как паук ползет по своей паутине. Начальный URL просто является начальной страницей, которая может содержать ссылки на другие страницы. PolyAnalyst сначала обрабатывает эту страницу, затем извлекает ссылки, переходит по этим ссылкам на другие страницы и извлекает их содержимое, после чего процедура повторяется.
От начального URL во многом зависит, какой объем информации сможет извлечь из сети узел Интернет. Не все веб-страницы связаны между собой ссылками. Более того, имеются "островки", "кластеры" или области с большим количеством перекрестных ссылок. Есть и страницы, на которые другие страницы не ссылаются, в результате чего они остаются недоступными для алгоритмов, выполняющих считывание контента подобно узлу Интернет.
Кроме того, традиционный алгоритм обхода контента имеет ограничение по количеству страниц, которые можно посетить (обойти), начиная с исходной страницы. Это значительно увеличивает вероятность того, что не все страницы, которые посещаются данным алгоритмом, являются связанными между собой.
Вы можете управлять алгоритмом обхода контента, указав один или несколько URL. Обычно используется более одного URL, когда существует вероятность того, что не все страницы из ряда страниц для импорта связаны ссылками с начальным URL. Обычно выбирается начальный URL с качественным контентом, либо URL, представляющий надежный, авторитетный ресурс.Такие URL должны выступать в качестве центров кластеров, о которых говорилось выше. Например, чтобы обойти сайт, вы скорее всего будете использовать URL домашней страницы, а не второстепенный URL одной из дочерних страниц, поскольку домашняя страница, как правило, содержит ссылки на большинство дочерних страниц.
Чтобы добавить начальный URL, введите URL в поле Список URL в левом верхнем углу вкладки Настройки импорта. Если вы хотите указать несколько начальных URL, обратите внимание на то, что все они должны быть размещены на отдельной строке.
Нажмите правой кнопкой мыши на URL в списке, чтобы просмотреть доступные опции контекстного меню.
Использование файла в качестве источника начальных URL
В поле Список URL вы также можете указать путь к файлу со списком URL. Можно использовать два типа файлов:
-
Простой текстовый файл, который содержит только список URL, по одному на строку. Необходимо добавить к пути файла префикс
@. Файл может быть локальным или сетевым. -
Файл, содержащий URL, с тегами
<a href=""></a>,<html>и</html>в начале и конце файла соответственно. В начале пути файла вам нужно поставить префиксfile://. Файл может быть локальным или сетевым.
В первом случае узел работает так же, как если бы вы ввели все ссылки из этого файла в настройках узла самостоятельно. Сам файл не отображается в выходной таблице данных, а ссылки в нем имеют нулевой уровень. Во втором случае, узел принимает файл за обычную HTML-страницу и помещает его в выходную таблицу данных (в первую строку). Следовательно, сам файл находится на уровне 0, а ссылки в нем – на уровне 1.
Альтернативные форматы начальных URL
-
Допускается опускать начальный протокол (т.е. не писать
http://). Так, например, вы можете использовать иwww.megaputer.com, иhttp://www.megaputer.com. По умолчанию PolyAnalyst используетhttp://, если в URL нет указаний на конкретный протокол. -
Допускается опускать поддомен, особенно в случае с
www. Так, например, вы можете использовать иwww.megaputer.com, иmegaputer.com. -
Допускается опускать конечный слеш
/. Так, например, вы можете использовать иwww.megaputer.com/, иwww.megaputer.com. -
Допускается использовать IP-адреса или пользовательские обозначения. Так, например, вы можете использовать и
127.0.0.1, иlocalhost, иwww.megaputer.com. -
Допускается опускать часть пути URL. Так, например, вы можете использовать
http://www.megaputer.comилиhttp://www.megaputer.com/index.html. В этом случае частью пути выступает/index.html. Если элемент пути отсутствует, PolyAnalyst будет использовать данные, которые получит от веб-сервера в ответ на запрос о доступе к веб-странице.
Выбор типов документов
В правом верхнем углу расположено поле выбора типов документов, с которыми будет работать узел Интернет. По умолчанию отмечены два вида – HTML документы и Текстовые документы.
Настройка опции Максимальная глубина страниц
Максимальная глубина страниц – это расстояние страницы от начального URL. Страницы, на которые имеются прямые ссылки с начального URL, имеют глубину со значением 1. Страницы, на которые имеются ссылки со страниц с глубиной 1, имеют глубину со значением 2. Глубина самого начального URL составляет 0.
Установка глубины страниц позволяет задать верхний предел количества страниц, найденных узлом Интернет. Глубина – это обязательное поле. Страницы с глубиной больше заданной отсеиваются. Значение глубины должно быть целым неотрицательным числом.
Помните, что при увеличении этого значения увеличивается количество загружаемых страниц. Увеличение глубины с 1 до 2 позволяет узлу захватить 10-15 дополнительных страниц (если считать, что это среднее количество ссылок на любой веб-странице). Если же увеличить глубину с 2 до 3, узел захватит 15 * 15 дополнительных страниц. Это дополнительное количество страниц значительно увеличит время работы узла.
Ограничение загрузки страниц
Опция Ограничить загрузку страниц позволяет алгоритму установить ограничение на количество загружаемых страниц из источника, т.е. позволяет вам отфильтровать, какие страницы вы хотите загрузить. Всего доступно четыре параметра:
-
Загружать все страницы;
-
Только указанный домен;
-
Только указанный путь URL;
-
Указанный путь URL и сам URL как подстрока.
Последний режим позволяет загружать все страницы, URL-адреса которых содержат данный адрес, например, если вы указали https://mail.com в качестве URL-адреса, выходные данные узла будут содержать все ресурсы, где присутствует "mail.ru", т.е. https://auto.mail.ru или https://health.mail.ru и т.д.
| Если вы хотите использовать опцию Только указанный путь URL, то сначала необходимо указать сам путь в поле Список URL (например, https://www.megaputer.ru/blog/page/3/). |
| Опции Только указанный путь URL и Указанный путь URL и сам URL как подстрока работают только тогда, когда установлен параметр Максимальная глубина страниц. |
Включение информации о родительских URL в отчет
Возникают ситуации, когда пользователям необходимо проследить связь между начальными URL, которые были указаны при настройке узла, и конкретными URL в результирующей таблице.
Отметьте галочкой опцию Добавить колонку с родительскими URL, чтобы включить в выходную таблицу данных информацию о родительских URL. В этом случае узел создаст отдельную колонку Parent URL для родительского URL на каждом уровне.
Количество дополнительных колонок будет соответствовать значению, указанному в поле Максимальная глубина страниц.
Извлечение информативного HTML-контента
В выпадающем меню выберите одну из двух опций: Извлекать весь HTML-контент или Извлекать только информативный HTML-контент.
Опция Извлекать только информативный HTML-контент позволяет повысить точность и полноту распознавания текстов и сохранить форматирование (заголовки, списки и т.д.). При выборе этой опции в выпадающем меню справа активируется кнопка, открывающая окно с дополнительными настройками:
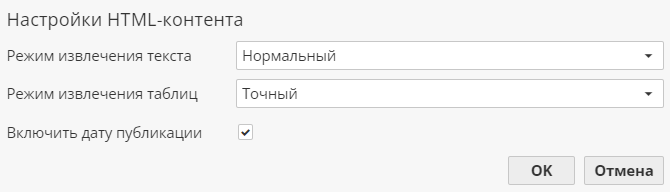
Режим извлечения текста позволяет выбрать оптимальный режим извлечения текстовых данных:
-
Нормальный режим извлекает текстовые данные с учетом общих правил и шаблонов, обеспечивая баланс между точностью и полнотой.
-
Точный режим в PolyAnalyst более внимателен к деталям и проводит более глубокий и точный анализ текстовых данных, что может быть полезно при работе с сложными и структурированными документами, но текстовые данные извлекаются только в случаях высокой уверенности в ответе.
-
Полнота - режим, позволяющий извлечь максимально возможное количество текстовых данных. Он может быть полезен в случаях, когда важна полнота информации без потери данных.
Режим извлечения таблиц позволяет выбрать оптимальный режим извлечения таблиц из текстовых документов:
-
Нормальный режим обеспечивает оптимальное сочетание точности и полноты. Стандартные алгоритмы извлечения данных из таблиц применяются к большинству типов таблиц.
-
Точный режим извлекает таблицу только в случае высокой уверенности в ответе. Таблица может быть извлечена не во всех случаях, но точность извлечения будет максимальной.
-
Полнота - режим, извлекающий таблицы почти во всех случаях, но точность извлечения может быть ниже.
Включить дату публикации - отобразит в выходном документе дату публикации веб-странцы.
Обход цепочки страниц
При включении опции Разрешить обход цепочки страниц алгоритм автоматически будет выявлять цепочки страниц, такие как << < … 3, 4, 5 … > >>, и будет пытаться собрать их в единый текст.
Исключение нетекстовых записей
При включенной опции Исключить нетекстовые записи узел игнорирует нетекстовое содержимое веб-страниц. Если опция отключена, узел попытается извлечь ссылки на изображения и графики.
Настройка опции Загружать форматирование
Опция Загружать форматирование используется для загрузки информации о форматировании веб-страниц (таблицы, заголовки и др.).
| Обратите внимание, что данная опция работает "на перспективу": результат ее работы можно увидеть только в последующем узле Индекс или других узлах текстового анализа, которые за ним следуют. |
Использование пользовательских скраперов
Кроме встроенного веб-скрапера, пользователи также могут использовать скраперы собственной разработки, написанные на языках Python, Perl и др., для извлечения данных с веб-сайтов. После того, как пользователь PolyAnalyst с правами администратора зарегистрирует скрапер в Административном клиенте в разделе Настройки сервера (категория Веб-скраперы), он будет доступен в выпадающем списке Скрапер на вкладке Настройки импорта узла Интернет.
Вы также сможете использовать опцию Разрешить заменять скрапер в ходе HTML-авторизации, если соответствующие настройки HTML-авторизации заданы администратором.
Расширенные настройки
Вкладка Расширенные настройки позволяет вам использовать User-agent: пользовательскую строку, в которой можно указать браузер, операционную систему и другие параметры. Для использования user-agent отметьте соответствующий чекбокс и заполните поле. Поле можно также оставить пустым.
Настройка интервала записи данных
Опция Интервал записи данных устанавливает время ожидания (в секундах) после каждого запроса.
Так, например, если количество потоков в узле Интернет равно 10, а Интервал записи данных равен 1, то узел Интернет будет делать не более 10 запросов в секунду. *
Если Интервал записи данных не указан, то будет использовано значение по умолчанию, установленное в Административном клиенте.
Количество потоков
Опция Количество потоков определяет количество запросов, выполняемых одновременно, например, в течение 1 секунды или более. Значение времени устанавливается в опции Интервал записи данных, которая описана выше. Значение по умолчанию задается в Административном клиенте в разделе Настройки сервера (категория Соединения).
Настройка других опций
Информацию по настройке остальных опции см. в разделах Настройка узла Файлы и Обновление импортированных данных.