Создание выборки данных во время импорта
Многие источники данных в системе PolyAnalyst могут быть настроены так, что они будут пропускать отдельные записи при импорте данных. Использование такой возможности уже в ходе импорта данных, а не на более поздних этапах проекта, позволяет сократить объем данных, которые сохраняет PolyAnalyst. Это может быть полезно или даже необходимо при работе с крупными таблицами. В качестве альтернативы вы можете импортировать всю таблицу данных целиком, а затем использовать один или несколько узлов, таких как Выборка или Фильтрация строк, для сокращения объема данных. Недостаток такого подхода заключается в том, что данные, подлежащие хранению, будут импортированы в полном объеме. И даже если вы создадите подмножество данных для анализа с помощью последующих узлов, вся таблица данных в полном объеме будет храниться в PolyAnalyst и занимать достаточно много места.
Если узел-источник данных позволяет фильтровать отдельные записи, в окне настроек узла вы увидите вкладку Выборка. Вы можете настроить источник данных на пропуск записей в начале таблицы данных, импортировать каждую n-ую запись или остановить импорт после того, как будет обработано определенное количество записей. Ниже представлен скриншот вкладки Выборка для узла Файлы CSV:
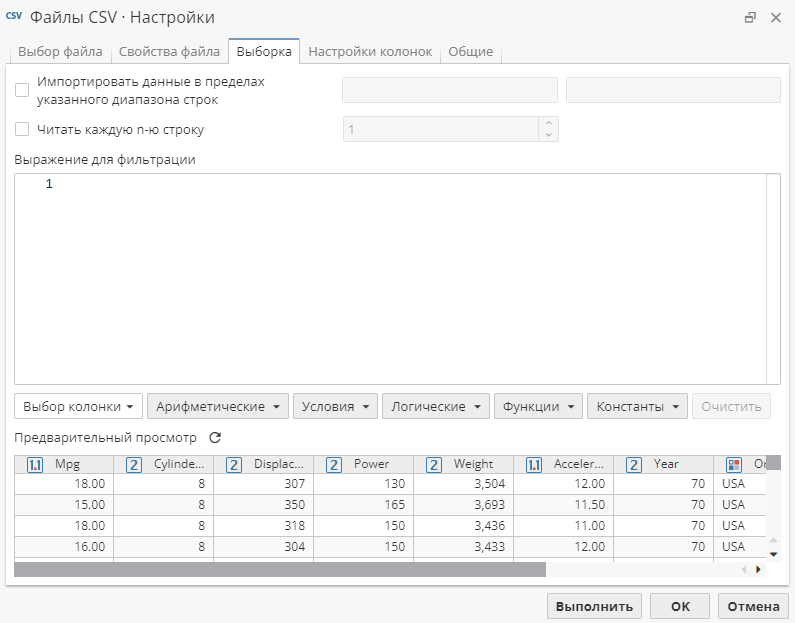
Для того, чтобы пропустить записи в начале таблицы данных, перейдите на вкладку Выборка и включите опцию Импортировать данные в пределах указанного диапазона строк. Найдите первое пустоте поле, обозначающее первую строку. По умолчанию поле остается пустым, что означает, что ни одна запись исходной таблицы не будет пропущена.
Для того, чтобы пропустить записи в конце таблицы данных, найдите второе пустое поле, обозначающее последнюю строку. По умолчанию данное поле остается пустым, что означает, что ни одна запись в конце таблицы не пропускается. Введите целое число больше 1, которое означает номер записи, на которой узел должен завершить импорт таблицы (эта строка будет импортирована последней).
Выберите опцию Читать каждую n-ю строку, чтобы узел пропустил строки через указанный интервал, и затем введите значение интервала в поле, которое активируется справа от опции. Значение должно быть целым числом больше 1.
Если данные во внешней таблице сохранены в случайном порядке, используя данную опцию вы можете создать случайную выборку этих данных.
Вы можете выполнить расширенный поиск, используя поле Выражение для фильтрации, куда можно ввести SQL-выражение.
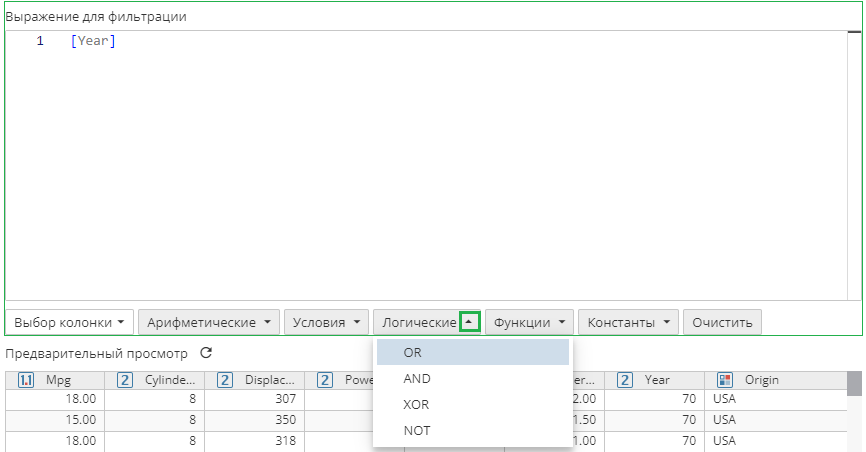
Используйте кнопки под полем, чтобы выбрать колонки (Выбор колонки) или ввести Арифметические, Логические и прочие операторы, Константы, Условия и Функции.