Настройка узла Линейная регрессия
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Диалоговое окно свойств узла Линейная регрессия состоит из трех вкладок: Выбор колонок, Настройки и Общие. На первой вкладке выберите зависимые и независимые переменные. Помните, что зависимая переменная должна быть числовой, целочисленной или относиться к данным типа "дата и время".
Поле Шаблон имени модели используется для того, чтобы указать имя создаваемой узлом модели и подробно описано здесь.
Вкладка Настройки узла Линейная регрессия позволяет пользователю выбрать метод контроля статистической значимости модели линейной регрессии.
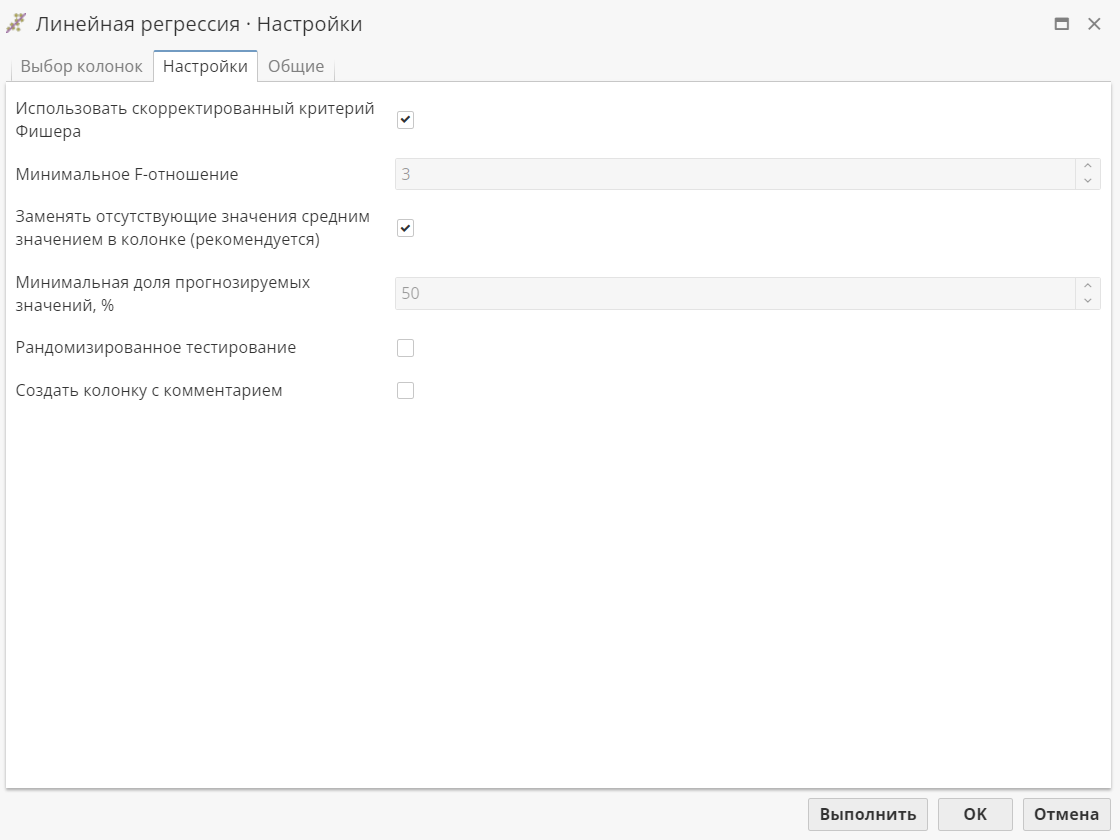
В PolyAnalyst используется два подхода к решению проблемы: критерий Фишера и рандомизированное тестирование.
F-тесты (критерий Фишера)
Критерий Фишера используется для оценки значимости отдельных регрессионных термов, а также модели регрессии в целом. В первом случае используется коэффициент определения регрессии (R2); во втором случае алгоритм использует отношение квадрата коэффициента регрессии к ожидаемой дисперсии (F-критерий). F-тесты выполняются в двух режимах – автоматическом (настоятельно рекомендуемый режим) и ручном. Если подключить опцию Использовать скорректированный критерий Фишера, используется первый способ. В этом случае критические значения критерия Фишера устанавливаются автоматически и корректируются в соответствии с ожидаемым количеством тестируемых независимых гипотез.
Необходимость корректировки можно проиллюстрировать следующим примером.
Предположим, что мы пытаемся создать 1-мерную модель регрессии для таблицы, состоящей из 1000 колонок, заполненных случайными числами, и понимаем, что вряд ли нам удастся создать сколько-нибудь значимую модель регрессии. Мы устанавливаем часто используемое критическое p-значение 0.01 и находим около 10 значимых моделей. Это понятно: мы проверили 1000 независимых гипотез с вероятностью принятия ложной гипотезы, равной 0.01. Мы могли бы получить правильный нулевой результат, если бы увеличили свой критерий в 1000 раз.
Таким образом, мы настоятельно рекомендуем использовать автоматический режим, поскольку это - единственный способ гарантировать надежность создаваемой модели.
Для чего сохраняется вторая возможность? Представьте следующую ситуацию. Мы исследовали (используя автоматический режим) таблицу с тремя предикторами и обнаружили значимую модель регрессии. Добавим 1000 колонок со случайными числами, выполним узел линейной регрессии снова и ничего не обнаружим. Ничего не изменилось – зависимость между целевой переменной и теми тремя предикторами по-прежнему существует, но мы не можем ее обнаружить, поскольку используем слишком строгие статистические критерии. В таком случае (когда мы не можем обнаружить значимую модель регрессии, хотя уверены в том, что она существует) мы можем попытаться отключить автоматический режим, убрав флажок. Тогда нам необходимо вручную ввести критическое значение критерия Фишера для коэффициентов регрессии в соответствующее поле окна настроек узла.
Критическое p-значение критерия Фишера для всей модели регрессии в таком случае равно 0.03. Установив для критического F-отношения приемлемо маленькую величину (например, 3), мы снова получаем модель регрессии. Правда, теперь она наверняка содержит некоторые дополнительные колонки со случайными числами, но мы увидим, что полученное F-отношение для истинных предикторов в несколько раз выше случайных колонок. Следовательно, эта модель позволяет понять факторы, которые влияют на целевые колонки. Но она подходит только для этой цели – она не может быть использована для оценки значений целевых колонок для новых записей, поскольку со статистической точки зрения, полученная модель ненадежна. Еще раз подчеркнем, что в этом случае было бы правильнее убрать ненужные колонки (используя какой-нибудь критерий корреляции колонок), вместо того, чтобы отключать автоматический режим.
Критическое значение критерия Фишера, установленное на 0, означает, что никаких проверок значимости выполнено не будет, а модель будет включать все имеющиеся исходные переменные.
Минимальная доля прогнозируемых значений используется для вычисления отсутствующих значений в таблице. Если один из атрибутов, используемых для создания целевых атрибутов, отсутствует, то целевой атрибут заполняется отсутствующим значением. Здесь необходимо указать определенное количество значений (в процентах), которые должен содержать целевой атрибут. Увеличение этого количества может привести к тому, что алгоритм будет использовать атрибуты, которые содержат больше значений, даже если другие атрибуты (содержащие больше отсутствующих значений) имели бы более высокую способность прогнозирования.
Рандомизированное тестирование
Опция Рандомизированное тестирование представляет собой возможность проверки значимости путем сравнения результатов, полученных для реальных исследуемых данных с результатами, полученными для тех же данных, но со значениями целевой переменной, представленными в рандомно измененном порядке. Для использования рандомизированных тестов требуется дополнительное время вычисления, они должны использоваться в случае нехватки данных (когда риск незначительности результата выше).
В то время, как значимость результатов, получаемых при выполнении каждой из этих элементарных статистических процедур, может быть оценена известными прямыми методами, оценить значимость всего исследования, например, множественной линейной регрессии, невозможно. Одним из наиболее часто используемых способов оценки является сравнение результатов, полученных для реально исследуемых данных с результатами, полученными для тех же данных, но со значениями переменных, в случайном порядке перемещенными для разных записей (это называется «рандомизированными данными»). Используя эти случайные тесты, мы оцениваем эмпирические параметры распределения точности, полученные для рандомизированных данных, а потом видим разницу между среднеквадратической погрешностью, полученной для реальных данных (Ereal) и для рандомизированных данных. Единица измерения этой разницы обозначается как S=(ErandavgEreal)/StddevErand, где Erandavg- значение среднеквадратической погрешности, полученной для рандомизированных данных; StddevErand. – стандартное отклонение от среднеквадратической погрешности, полученной для рандомизированных данных. Обычно значения S больше 3 подтверждают статистическую значимость полученных результатов. Выполнение рандомизированных тестов требует дополнительного времени вычисления. Иногда времени требуется в несколько раз больше, чем на исследование самих реальных данных. По этой причине опция по умолчанию отключена. Желательно, чтобы эта опция была включена в случае недостатка данных (когда риск получения бесполезных результатов выше). Кроме того, в этом случае время вычисления невелико. Для исследования большого количества данных может понадобиться очень много времени. К счастью, как правило, исследование рандомизированных данных занимает меньше времени, чем исследование реальных данных, так как первые не содержат искомых зависимостей.