Настройка нескольких зависимых переменных
Некоторые узлы системы PolyAnalyst поддерживают одновременную обработку и моделирование нескольких зависимых переменных. Зависимые переменные называются целевыми. Для того, чтобы использовать несколько целевых переменных, выберите несколько колонок из списка доступных колонок на первой вкладке окна настроек узла. Выбор колонок был подробно описан ранее.
Помните, что многие узлы анализа данных в PolyAnalyst могут работать с отдельными типами целевых переменных. Например, такие узлы-классификаторы, как Случайный лес решений, в качестве целевой переменной могут принимать только категориальные колонки (строковые, булевы данные или целочисленные идентификаторы). В связи с этим, если вы хотите обучить модель классификации для числовой колонки, вам понадобятся дополнительные манипуляции с данными: с помощью узла Модификация колонок вам придется изменить тип данных в колонке. Инструменты регрессионного анализа, например, узел Линейная регрессия, работают с числовыми или целочисленными целевыми колонками. При выборе одной или нескольких целевых переменных убедитесь в том, что они содержат подходящий тип данных. В противном случае вы получите сообщение об ошибке после того, как нажмете OK, при попытке выполнить узел или просмотреть его результаты.
Для правильной настройки и работы узлов необязательно выбирать несколько целевых переменных. Часто используется одна целевая колонка.
| При настройке нескольких зависимых, или целевых, переменных, целевая колонка будет автоматически исключена из списка независимых колонок. |
Выбор нескольких целевых переменных предполагает, что PolyAnalyst выполняет дополнительное обучение модели. Таким образом, увеличивается время обработки данных, и это влияет на производительность Сервера PolyAnalyst во время работы узла.
Если вы использовали несколько целевых переменных, как правило, в верхней части окна просмотра результатов таких узлов появится дополнительное выпадающее меню для выбора одной из целевых колонок:
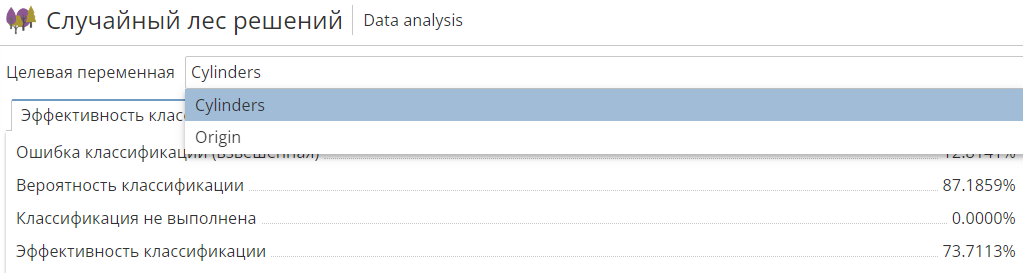
Результаты классификации, представленные на всех вкладках отчета, будут меняться в зависимости от выбранной в окне просмотра целевой переменной.
Именование моделей
Все узлы моделирования в системе PolyAnalyst позволяют пользователям указывать имена моделей.
Если вы хотите использовать несколько моделей на входе в узлы Объединение моделей или Применение моделей, рекомендуется использовать уникальные имена моделей, которые описывают их предназначение.
Имя модели обычно задается на первой вкладке визарда узлов моделирования. В нижней части окна расположено поле Шаблон имени модели:

Данное поле содержит редактируемый шаблон имени модели. Для того, чтобы имя модели было уникальным и интерпретируемым, рекомендуется указывать код создавшего ее алгоритма (P), имя целевой колонки (V) и тип модели (T). Доступны следующие коды именования моделей
Код |
Значение |
P (код алгоритма) |
|
$AR |
|
AB |
|
BA |
|
BM |
|
CA |
|
CB |
|
CL |
|
CN |
|
CU |
|
DA |
|
DB |
|
DN |
|
DT |
|
FA |
|
KN |
|
LRC |
|
LR |
|
LO |
|
MA |
|
NB |
Наивный байесовский классификатор (Байесовская классификация) |
NN |
|
PY |
Python (Классификация) / Python (Кластеризация) / Python (Декомпозиция) / Python (Регрессия) |
RC |
|
RF |
|
TB |
|
TS |
|
TX |
|
SN |
|
SV |
|
|
применение модели (доступно для всех узлов) |
|
создает комментарии для применения модели (доступно для узлов с опцией Создать колонку с комментарием в настройках узла, например для узла Дерево решений |