Выбор колонок во время настройки узлов
В данном разделе рассматривается стандартный способ выбора колонок, который используется при настройке большинства узлов в PolyAnalyst. Как правило, большинство узлов, работающих с колонками, используют похожий интерфейс для выбора колонок.
| Изложенная здесь информация не относится к некоторым узлам; специфика таких узлов описана в разделах по их настройке. |
Данный раздел относится к настройке всех узлов в PolyAnalyst за исключением узлов-источников данных. Для получения дополнительной информации по настройке колонок в момент импорта данных (а не в момент обработки) см. раздел по импорту данных или раздел по настройке колонок при импорте данных.
Как правило, колонки настраиваются на первой вкладке окна свойств всех узлов, которые могут совершать действия с колонками. Обычно эта вкладка называется Выбор колонок. Например, на следующем скриншоте показана вкладка выбора колонок узла Фильтрация колонок:
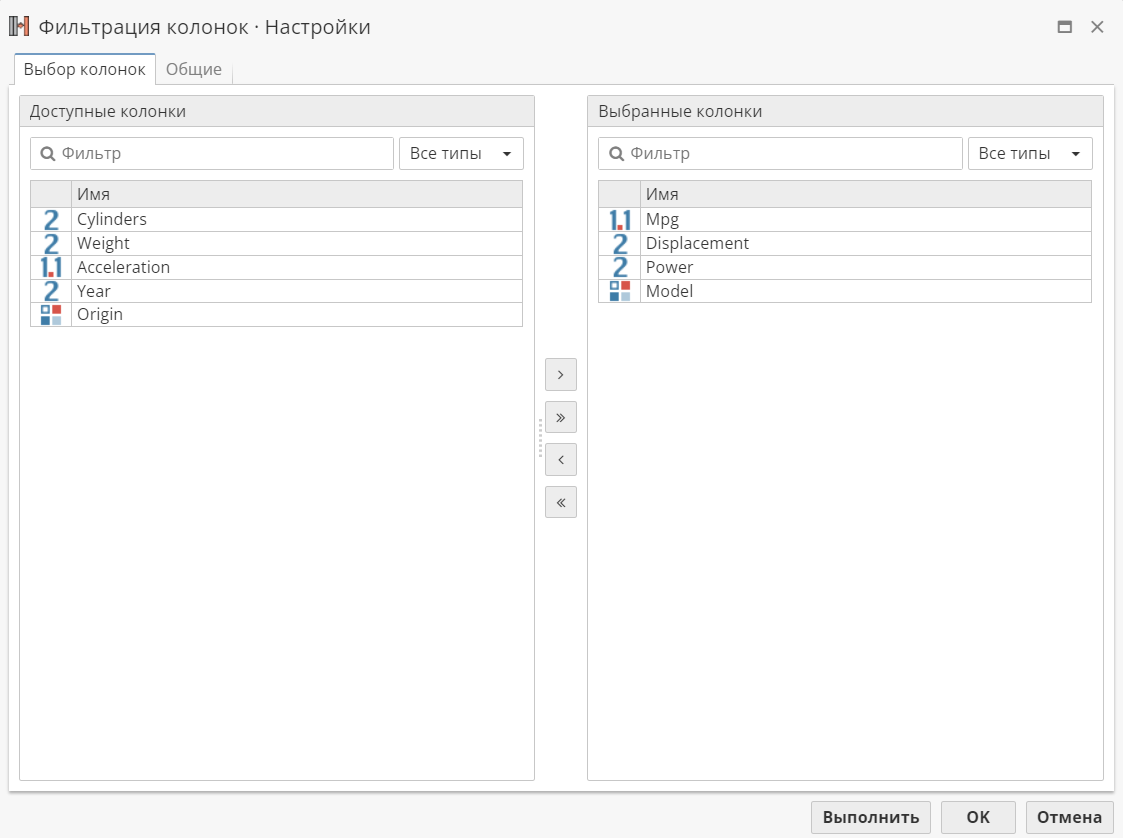
Узел Фильтрация колонок сравнительно просто настраивается по сравнению с некоторыми другими узлами. Существует два списка колонок. Список слева называется Доступные колонки, а список справа - Выбранные колонки. Обычно во время настройки данного узла одна или несколько колонок из списка доступных колонок перемещаются в список выбранных колонок. Перемещение колонок из одного списка в другой может быть выполнено разными способами. Например, вы можете использовать кнопки > и < для перемещения колонок вперед и назад.
Список доступных колонок
Прежде чем продолжать разговор об основных способах перемещения колонок из списка доступных колонок в список выбранных колонок, важно понять, откуда берется список доступных колонок. Возможно, вам нужно будет вернуться к вводному разделу по использованию узлов, прежде чем вы продолжите изучение данного раздела. Когда вы добавляете узлы на скрипт и затем соединяете их, вы направляете поток выходных данных (например, таблицу данных) из одного узла в другой. В приведенном выше примере с узлом Фильтрация колонок список доступных колонок содержит колонки по следующим причинам.
Во-первых, вы уже выбрали колонку(и) для использования. На приведенном выше скриншоте некоторые колонки уже были выбраны путем перемещения в список справа. Следовательно, они больше не являются "доступными" и потому не отображаются в списке слева. Однако, колонка может остаться в списке доступных колонок даже после того, как ее уже использовали при настройке узла, поскольку одна и та же колонка в некоторых узлах может использоваться несколько раз.
Во-вторых, на скрипте имеется другой узел, уже соединенный с нашим, и поставляющий ему входные данные. Наш узел использует выходные данные первого узла, которые представляют собой таблицу данных, в качестве входных данных. Список колонок появляется из этой выходной таблицы, которая переходит по соединению между узлами. Если вы настроили данный узел, сохраните свою настройку, нажав ОК, и затем отредактируйте скрипт и удалите соединение между узлами. Когда вы повторно откроете окно свойств, список доступных колонок опять будет пустым.
В-третьих, предыдущий узел был корректно настроен и, возможно, выполнен, поэтому колонки из его выходной таблицы в настоящий момент известны. Как описано во вводном разделе по работе с узлами, а именно в абзаце, посвященном описанию состояний узлов, это означает, что предшествующий узел (узел, соединенный с узлом, который вы настраиваете) находится либо в настроенном, либо в выполненном состоянии. Когда вы устанавливаете соединение между узлами на скрипте, если предшествующий узел уже находился в настроенном состоянии (или позже - в завершенном состоянии) в момент создания соединения, определенная информация пересылается по соединению в последующие узлы, например, рассматриваемый здесь список доступных колонок.
Существует одна важная деталь, которую необходимо учитывать в связи с тем, что сказано выше о состоянии предшествующего узла. Предшествующий узел не обязательно должен быть в завершенном состоянии, чтобы с его помощью настроить последующий узел. Достаточного того, чтобы предшествующий узел был корректно настроен. Здесь необходимо понять то, что это позволяет вам настраивать несколько узлов в цепи до того, как вы выполните какой-либо узел в данной цепи. Выполнение узлов может занять значительное количество времени. Например, узел, импортирующий несколько миллионов записей, может выполняться очень долго. Как следствие, ждать, пока каждый узел будет выполнен, и только потом настраивать последующие узлы в цепочке, неудобно. Пользователю нет необходимости ждать завершения работы узла. После того, как вы надлежащим образом настроили узел, импортирующий данные, но до того, как вы действительно импортировали данные, вы можете соединить другие узлы с узлом импорта и получить возможность настраивать колонки в последующих узлах. Более того, вы можете настроить весь скрипт, состоящий из нескольких узлов, до запуска одного из узлов.
Однако существуют исключительные случаи, когда предшествующие узлы должны находится в завершенном состоянии (узел должен быть выполнен) для того, чтобы настроить текущий или последующие узлы. Как правило, это происходит тогда, когда предшествующий узел может выдавать изменяемое количество колонок. Другими словами, вы можете настроить последующие узлы в цепи до того, как какой-либо из узлов будет выполнен, только в том случае, если каждый из узлов в этой цепи (кроме последнего) выдает фиксированное количество известных колонок. В тот момент, когда вы дойдете до узла в цепи, количество колонок в выходе которого может варьироваться, и потому номер, имя и тип каждой колонки невозможно установить до тех пор, пока такой узел не будет выполнен, вам придется выполнить данный узел, чтобы продолжить настройку.
Но обратите внимание на то, что, если затем вы перенастроите предшествующий узел, чтобы создать другие колонки или дополнительные колонки, эти колонки не будут автоматически выбраны в последующем узле, они будут лишь доступны для выбора. Вам также придется перенастраивать каждый из последующих узлов в цепи для работы с новыми или переименованными колонками. Однако в некоторых случаях переименованная колонка все равно появится в списке выбранных колонок, поскольку некоторые узлы могут распознавать это изменение. Когда вы перенастраиваете узлы или изменяете импортируемые данные, всегда обращайте внимание на такое последствие и всегда проверяйте каждый из последующих узлов, чтобы убедиться в наличии необходимых вам настроек.
Перемещение колонок из одного списка в другой
Вы можете переместить одну или несколько колонок одновременно из списка доступных колонок в список выбранных колонок. Для перемещения одной колонки выберите нужную колонку в списке доступных колонок, нажав левой кнопкой мыши на ее название в списке. Затем нажмите кнопку >. Для перемещения сразу нескольких колонок выберите каждую колонку в списке слева, удерживая кнопку CTRL, и выбирая левой кнопкой мыши имена нужных колонок, нажмите на кнопку > (вы также можете использовать SHIFT для выбора группы колонок, подобно тому, как вы используете SHIFT в Windows Explorer для выбора нескольких файлов в папке). Чтобы переместить все колонки в список выбранных колонок, нажмите кнопку >> (в этом случае не имеет значения, на какие колонки вы нажали левой кнопкой мыши).
Перемещение колонок из списка выбранных колонок обратно в список доступных колонок выполняется аналогичным образом, но в обратном порядке. Нажмите на имя колонки в списке выбранных колонок справа и затем нажмите на кнопку < для возврата колонки. Вы можете вернуть все колонки в список доступных, используя кнопку <<.
Сортировка списка колонок
Когда список доступных колонок показывается в первый раз (когда вы открываете окно свойств узла для его настройки), колонки в списке показываются в естественном порядке. Термин естественный порядок означает такой порядок колонок, в котором они физически содержатся в исходной таблице узла, настраиваемого вами в настоящий момент. Иногда с таким естественным порядком работать неудобно, особенно когда во входных данных содержится большое количество колонок, поэтому вы можете использовать простую сортировку, чтобы находить нужную колонку быстрее.
Вы можете отсортировать список по типу данных в каждой колонке или по имени каждой колонки. Сортировка производится в восходящем (А-Я) или в нисходящем (Я-А) порядке. Для сортировки нажмите на заголовок колонки типа данных или имени колонки - это самый первый ряд с надписями "Тип" и "Имя". Нажмите левой кнопкой мыши один раз на слово "Имя" для сортировки списка по имени в восходящем порядке. Нажмите левой кнопкой мыши на слово "Имя" еще раз для переключения к нисходящему порядку сортировки. Нажмите левой кнопкой мыши еще раз для возврата к естественному (несортированному) порядку. Таким же образом вы можете отсортировать данные по типу, что, как правило, приводит к сортировке согласно имени каждого типа (например, целые числа показываются перед строковыми данными при сортировке в восходящем порядке, поскольку "i" предшествует "s").
| Вы можете необратимо изменить естественный порядок колонок, используя узел Модификация колонок, а также переместить колонки, переименовать колонки и, возможно, изменить тип данных в колонке. |
Поиск по списку колонок
Для поиска колонки вы можете напечатать имя или часть имени в текстовое поле рядом со словом "Фильтр", расположенным над списком доступных колонок. PolyAnalyst выполняет поиск по мере того, как вы печатаете. Каждый раз, когда вы набираете символ в данное текстовое поле, список фильтруется только для показа колонок, содержащих набранные вами символы.
Для того, чтобы показать все колонки еще раз, удалите набранные символы из текстового поля. Не забудьте удалить фильтр: это одна из распространенных ошибок, когда пользователи забывают о фильтровании списка и в результате не видят некоторых колонок.
Если узел также показывает текстовое поле "Фильтр" над списком выбранных колонок, помните, что второй фильтр, как правило, применяется только к списку выбранных колонок. В некоторых узлах набор текста в одном из текстовых полей над одним из списков приведет к фильтрации обоих списков одновременно.
Фильтрация колонок с помощью шаблонных выражений
Необходимые для анализа колонки можно выбрать и с помощью шаблонных выражений. В PolyAnalyst эта возможность обеспечивается опцией Фильтр колонок по шаблону.
Поле Фильтр колонок по шаблону предназначено для ввода шаблонных выражений, по одному на строку.
Функционал расширенной фильтрации колонок регулируется определенными пользовательскими настройками. В меню Настройки выберите вкладку Настройки пользователя и в разделе Управление проектом и отчетом включите опцию Дополнительный фильтр колонок. По умолчанию эта опция отключена.
Настроив дополнительный фильтр колонок, откройте свойства узла (нажмите на иконку узла правой кнопкой мыши и выберите Настройки. Под списком выбранных колонок появится поле Фильтр колонок по шаблону.
Введите в текстовое поле шаблонное выражение. При необходимости включите опцию Использовать все колонки КРОМЕ выбранных.
Дополнительный фильтр колонок можно включить через контекстное меню, которое открывается после клика правой кнопкой мыши в любом свободном месте в поле выбранных колонок. Администраторы системы PolyAnalyst могут включить такой фильтр для всех новых пользователей, и тогда он будет отображаться на вкладке выбора колонок по умолчанию. Обратите внимание на то, что такие дополнительные опции фильтрации доступны не во всех узлах. Например, их нет в источниках данных. К тем узлам, где дополнительный фильтр колонок может быть использован, относятся Фильтрация колонок, Агрегирование и др.
Настройте другие опции узла и нажмите Выполнить.
Все имена колонок таблицы данных родительского узла, соответствующие условиям введенного шаблонного выражения, будут выделены курсивом. Фильтрация колонок происходит автоматически сразу после редактирования выражения.