Настройка узла Уникальные тексты
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Окно настроек узла Уникальные тексты содержит следующие вкладки: Выбор колонок, Настройки и Общие.
Вкладка Выбор колонок предназначена для выбора рабочей колонки узла:
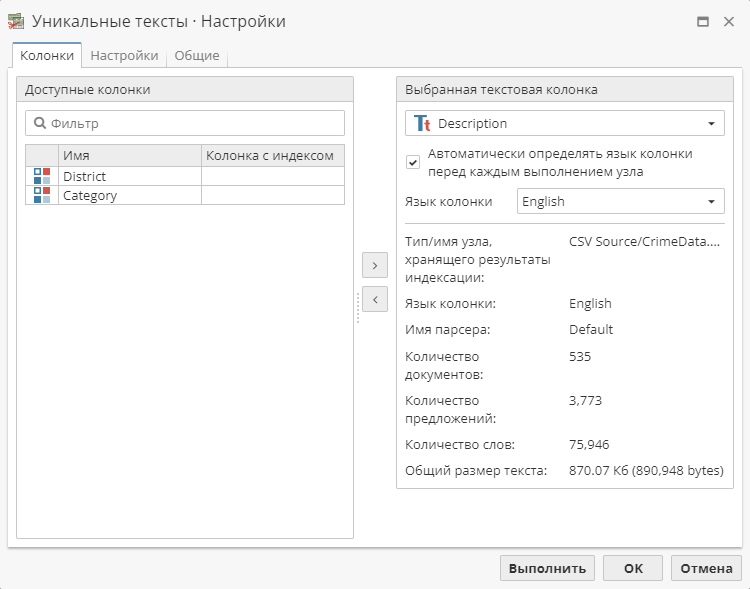
Если в исходной таблице данных имеется только одна текстовая колонка, узел автоматически выбирает ее сразу при соединении данного узла с родительским. Если в исходной таблице имеется несколько текстовых колонок, выберите нужную вам колонку в списке доступных колонок слева, и переместите ее в список выбранных колонок справа с помощью двойного клика или соответствующей кнопки. Кроме того, на первой вкладке пользователь может включить или отключить опцию автоматического определения языка колонки перед каждым выполнением узла (по аналогии с узлом Индекс).
Вкладка Общие имеется во многих других узлах и была описана ранее. Обычно узел настраивается слева направо, начиная с первой вкладки.
Основные параметры работы узла настраиваются на второй вкладке – Настройки. Вкладка выглядит следующим образом:
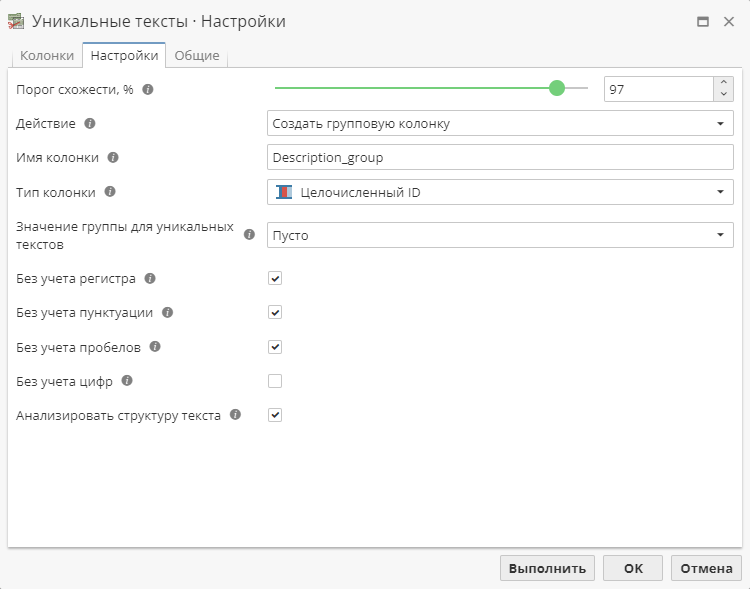
Рассмотрим эти настройки подробнее.
Настройка порога схожести
Первая опция сверху – Порог схожести, %.
| В настоящий момент узел работает корректно, если порог схожести составляет 70% и выше. |
Степень схожести документов находится в диапазоне от 0 до 100, где 0 обозначает абсолютно несхожие документы, а 100 – максимально схожие документы. Для любой пары документов, если схожесть на шкале от 0 до 100 больше порогового уровня, то два текста считаются схожими. Если схожесть ниже порогового уровня, то тексты схожими не считаются. Чем выше порог схожести, тем меньше будет найдено схожих текстов. И наоборот, чем ниже порог схожести, тем легче поиск схожих текстовых значений. Нахождение большего количества схожих текстовых значений означает, что из выходных данных исключается больше записей в связи с их схожестью. Нахождение меньшего количества схожих текстовых значений из-за очень высокого порога означает, что в выходную таблицу попадет больше записей.
Алгоритм, позволяющий определить степень схожести между любыми двумя текстами, основывается на абстрактном понятии «сигнатуры текста». Для любого текстового значения каждой записи выбранной колонки в первую очередь высчитывается его сигнатура. Сигнатуру можно рассматривать как некоторое случайное число между 1 и несколькими миллиардами. Каждому тексту, в зависимости от его характеристики, присваивается какое-либо число из этого диапазона. При выборе слов для определения сигнатуры каждого текста алгоритм предпочитает более длинные слова, поскольку они, как правило, более уникальны.
Подход к определению повторяющегося контента на основе сигнатур очень похож. Предположим, что сигнатура использует до 100 символов. После того, как PolyAnalyst создаст сигнатуру для каждого документа, означающую его уникальность, схожие документы можно будет быстро найти, сравнивая их сигнатуры. Для того, чтобы оценить преимущества такого подхода, можно представить сравнение полного текста одной записи с полным текстом другой записи (буква за буквой, слово за словом), с одной стороны, и сравнение двух записей по их ID – с другой.
Показатель cхожести двух сигнатур определяется как отношение длины самой длинной общей последовательности символов к длине более длинной из двух сигнатур. Длина означает «количество символов». Например, один текст содержит 20 символов, а второй – 30. 30 является знаменателем в отношении, т.к. число 30 больше 20. Сравнив эти тексты, PolyAnalyst обнаружит, что обе сигнатуры имеют три общие цепочки символов, в одной из которых 2, в другой – 3, в третьей – 10 символов. Самая длинная цепочка состоит из 10 символов. Таким образом, выражение для определения степени схожести выглядит так: 10/30, где 10 – самая длинная цепочка символов, а 30 – длина самой длинной сигнатуры, использованной при сравнении. Степень схожести в таком случае равна 30%.
Опции меню Действие
Узел Уникальные тексты может производить различные типы выходных данных. Выпадающее меню Действие позволяет выбрать тип выходных данных узла.
По умолчанию выбрана опция Создать групповую колонку. При выборе этой опции выходная таблица будет содержать все повторяющиеся записи исходной таблицы. Однако в конец входной таблицы будет добавлена новая колонка. Это действие похоже на работу узла Производные колонки, в котором создается новая таблица, содержащая все колонки исходной таблицы, а также одну новую колонку. При выполнении этого действия новая колонка будет содержать целочисленное значение для каждой записи. Значение представляет собой уникальный идентификатор каждой "группы" найденных повторяющихся записей. Например, если в исходных данных есть три записи, содержащие схожие тексты, то для каждой из этих трех записей в новой колонке в выходных данных узла будет указан номер этой группы.
Опция Создать групповую колонку дает пользователю возможность изменить имя новой колонки или использовать имя, присвоенное ей по умолчанию (обычно это имя исходной текстовой колонки и добавленный к нему суффикс group). Можно выбрать тип данных в новой колонке – "числовой идентификатор" или "целое число". Выбор типа данных колонки зависит от того, как вы будете использовать эту колонку в ходе дальнейшего анализа.
Использование опции Создать групповую колонку полезно тогда, когда вы хотите исследовать записи, рассматриваемые узлом как дубликаты, более тщательно. Также можно впоследствии использовать более точный инструмент для удаления повторяющихся записей. Например, вы можете использовать узел Агрегирование. В нем можно выбрать новую колонку в качестве ключа агрегирования, а затем использовать различные методы агрегирования, чтобы получить оптимальные выходные данные.
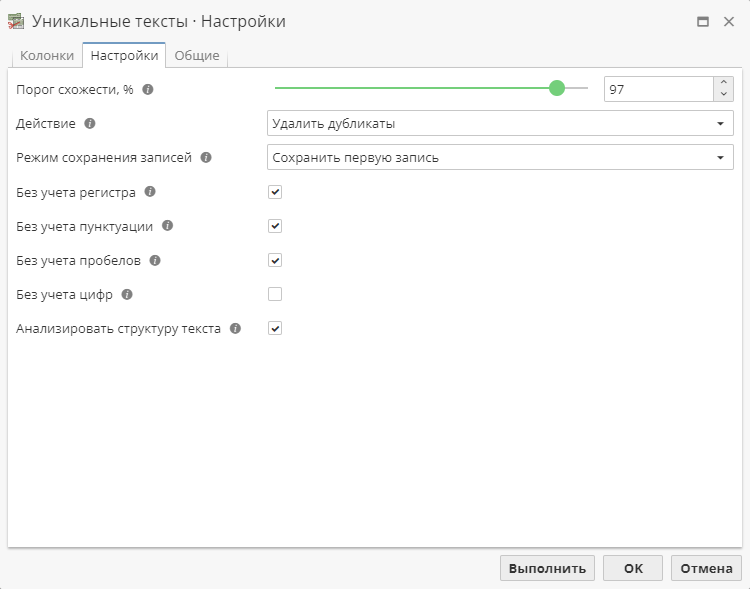
Опция Удалить дубликаты создает иной тип выхода. При использовании этой опции узел генерирует таблицу, из которой удалены все дубликаты (повторяющиеся записи). Из группы найденных узлом дубликатов в выходную таблицу входит только один дубликат (первый, последний, самый длинный или самый короткий) в зависимости от выбранного режима сохранения записей (см. описание ниже).
При выборе опции Удалить дубликаты под меню Действие будут отображено дополнительное поле – Режим сохранения записей:
Обратите внимание, что использование на текстовой колонке такого метода агрегирования, как Первое значение, приводит к созданию тех же результатов, что получаются в том случае, если использовать опцию Удалить дубликаты, но при этом не следует включать опцию Сохранить последнюю запись. Использование метода агрегирования Последнее значение позволяет получить тот же результат, что и опция Удалить дубликаты при включении опции Сохранить последнюю запись. Вы также можете попробовать другие методы, например, пересортировку данных, при которой записи рассматриваются как первые или последние на основе какой-то другой логики. Здесь можно использовать сотни различных методов. Например, используйте узел Производные колонки для создания колонки с указанием длины текстов, а затем – узел Агрегирование, чтобы оставить только самые длинные записи (при этом для новой колонки c длиной текстов используйте метод агрегирования MAX (Максимальное значение)).
| В любом узле PolyAnalyst при добавлении одной или нескольких новых колонок к исходной таблице данных, они всегда добавляются в самый конец таблицы справа. Для изменения порядка колонок можно использовать узел Модификация колонок. Обратите внимание, что если затем вы планируете использовать узел Агрегирование, то использование узла Модификация колонок для изменения порядка колонок выходной таблицы узла Уникальные тексты не представляется целесообразным. |
Настройка режима сохранения записей
Когда алгоритм находит две или более сигнатуры, которые проходят порог схожести, он создает виртуальную группу схожих текстов. Важен порядок, в котором сигнатуры входят в группу; он зависит от порядка записей в исходной таблице данных. Поскольку мы хотим получить на выходе только уникальные записи, PolyAnalyst должен каким-то образом выбрать, какие записи из группы схожих записей должны появиться в выходной таблице, что подразумевает "удаление" всех остальных записей. Для того, чтобы настроить поведение алгоритма в таких случаях, используйте выпадающее меню Режим сохранения записей, которое расположено в центре вкладки Настройки.
В данном меню доступны следующие опции:
-
Сохранить первую запись – из найденной группы дубликатов сохраняется та запись, которая была первой обнаружена при последовательном прочтении всех записей в исходной таблице от начала до конца. Опция выбрана по умолчанию.
-
Сохранить последнюю запись – из найденной группы дубликатов сохраняется та запись, которая была обнаружена последней.
-
Сохранить самую длинную запись – из найденной группы дубликатов сохраняется запись с максимальной длиной.
-
Сохранить самую короткую запись – из найденной группы дубликатов сохраняется запись с минимальной длиной.
Таким образом, меню Режим сохранения записей позволяет пользователю управлять тем, какие записи должны быть сохранены на выходе. Обратите внимание на то, что при использовании этого метода вам, возможно, понадобится сначала использовать узел Сортировка строк, чтобы данные в исходной таблице были отсортированы в нужном порядке.
Настройка других опций
На вкладке Настройки также находятся некоторые дополнительные опции, которые позволяют увеличить точность и полноту результатов узла:
-
Без учета регистра – позволяет не учитывать регистр символов при сравнении записей, в результате чего, например, слова "test" и "Test" считаются идентичными; опция по умолчанию включена;
-
Без учета пунктуации – позволяет не учитывать знаки препинания при сравнении записей; опция по умолчанию включена;
-
Без учета пробелов – позволяет не учитывать пробелы при сравнении записей; опция по умолчанию включена;
-
Без учета цифр – позволяет не учитывать цифры при сравнении записей; опция по умолчанию выключена;
-
Анализировать структуру текста – позволяет выполнить базовый анализ структуры текста. В ходе сравнения выявляются документы с меньшим весом. Опция не может быть использована, если порог схожести документов равен 100%; опция по умолчанию включена;
-
Маркировать уникальные документы – все уникальные документы в групповой колонке будут содержать маркер "0".
В нижней части вкладки Настройки при наведении курсора на любую из опций отображается ее краткое описание.