Настройка узла Индекс
Окно свойств узла Индекс состоит из четырех вкладок.
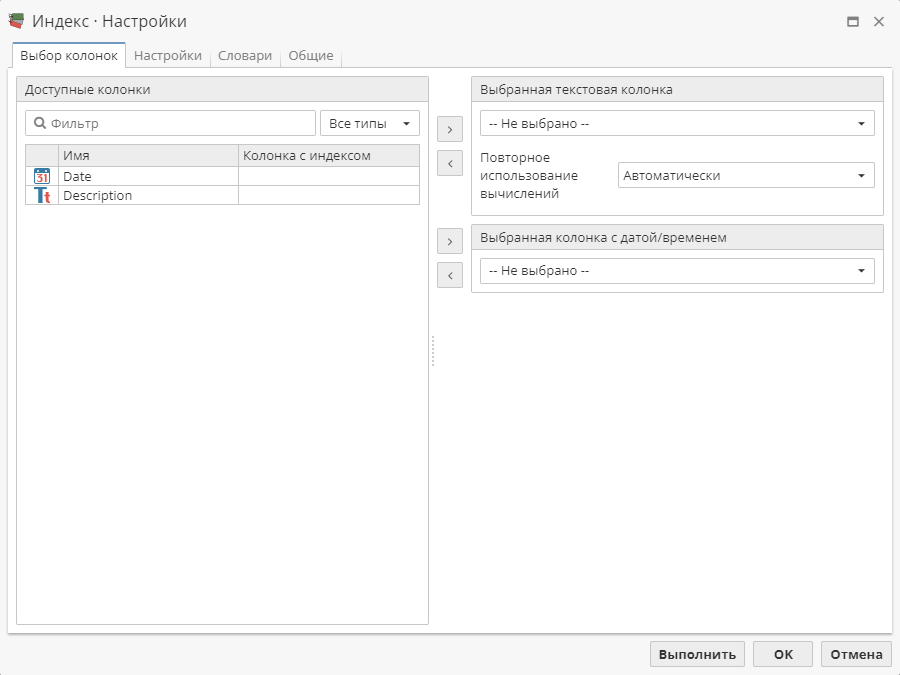
На первой вкладке Выбор колонок выберите исходную колонку для индексирования. На второй вкладке Настройки настройте способ индексирования. На третьей вкладке Словари выберите словарь, который будет использован в ходе индексирования. На четвертой вкладке Общие укажите имя и описание узла.
| Используемые настройки существенно влияют на результаты вашего анализа данных. Последующие узлы в цепи будут использовать только проиндексированные (а не исходные) данные. Ваши настройки позволяют настроить процесс индексирования, а от этого, в свою очередь, полностью зависит результат. Если вы не уверены в назначении какой-либо опции, не изменяйте ее. |
Настройка вкладки Колонки
На первой вкладке, Колонки, слева представлен список доступных колонок из предыдущего узла (см. описание "доступных" колонок в разделе выбор колонок при настройке узлов). В правой части этой вкладки находится поле Выбранная текстовая колонка.
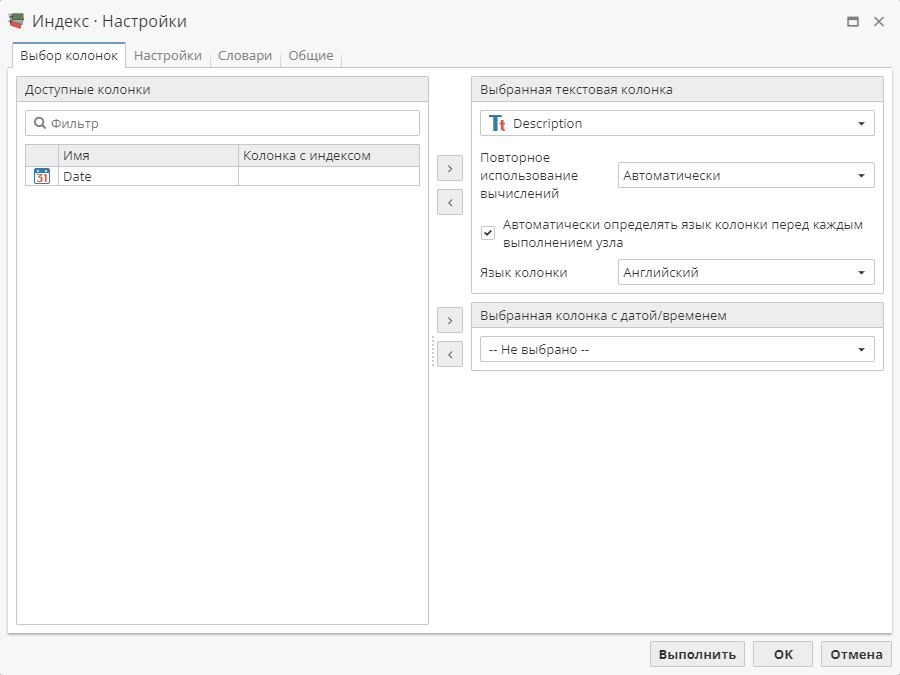
Настройка вкладки предполагает выбор одной из доступных исходных колонок в качестве колонки для индексирования.
Для этого выберите нужную колонку в списке доступных колонок слева. Затем нажмите на кнопку  , чтобы переместить эту колонку в список колонок для индексирования.
, чтобы переместить эту колонку в список колонок для индексирования.
| Если в списке доступных колонок имеется только одна текстовая колонка, она, как правило, автоматически перемещается в список колонок для индексирования после того, как вы соедините родительский узел с узлом Индекс. |
Опция Повторное использование вычислений позволяет настроить использование результатов предыдущего выполнения узла. Кроме узла Индекс, данная опция используется также некоторыми другими узлами текстового анализа, а именно узлами Анализ тональности, Извлечение сущностей и Извлечение фактов.
Если опция включена, при каждом перевыполнении будут индексироваться только вновь добавленные документы. Те записи, которые были проиндексированы в предыдущий раз, индексироваться не будут, а результат их индексирования будет копироваться из полученного ранее результата. Таким образом, скорость индексации увеличится, так как одни и те же документы не будут индексироваться дважды.
| Повторное индексирование документов не выполняется даже в том случае, если при последующей индексации таблицы порядок следования документов в ней изменился. Это происходит потому, что алгоритм ищет документ по его хэш-коду, а не по его позиции, благодаря чему даже при изменении порядка документов информация об их индексации будет восстановлена правильно. |
Если настройка узла Индекс изменится, то результат предыдущего индексирования будет сброшен. Для того, чтобы вручную сбросить результаты предыдущей индексации, нужно выполнить узел Индекс, предварительно отключив опцию Повторное использование вычислений.
Важно помнить о том, что после обновления PolyAnalyst или изменения словарей, результат индексирования документов может меняться. Однако при повторном использовании результатов индексации этот момент учитываться не будет. Если пользователь хочет пересчитать индекс с учетом последних изменений в словарях или в алгоритмах, он должен вручную отключить опцию и выполнить узел.
По умолчанию любой узел, выполняющий индексацию текста, принимает решение о повторном использовании результатов предыдущего выполнения в автоматическом режиме: предыдущие вычисления используются повторно в том случае, если с момента последнего выполнения узла не изменился номер версии PolyAnalyst, версии выбранных словарей и макросы (последние актуальны для узлов Анализ тональности, Извлечение сущностей и Извлечение фактов).
На первой вкладке узла Индекс вы также можете подключить опцию Автоматически определять язык колонки перед каждым выполнением узла. Если включить опцию, в выпадающем меню Выбрать язык колонки, расположенном ниже, автоматически появится язык индексируемой колонки. Если вы не согласны с автоматическим выбором, меню позволяет вам изменить его вручную.
Опция Выбранная колонка с датой/временем на вкладке Колонки также носит факультативный характер: в это поле можно переместить колонку, которая содержит дату и/или время. Это позволяет "привязать" даты к документам текстовой колонки. К этим датам в дальнейшем смогут обращаться различные алгоритмы и пользователь, используя PDL-функцию docdate(). Так, например, это позволяет ограничить временной интервал для извлечения ключевых слов, если узлу Извлечение ключевых слов на скрипте предшествует Индекс (см. описание в разделе Результаты узла Извлечение ключевых слов).
Настройка опций индексирования на вкладке Настройки
Вкладка Настройки включает несколько опций индексирования. Вы можете изменить способ распознавания отдельных слов, сделать так, чтобы некоторые пунктуационные знаки считались частями слова, а не разделителями слов, и т.д.
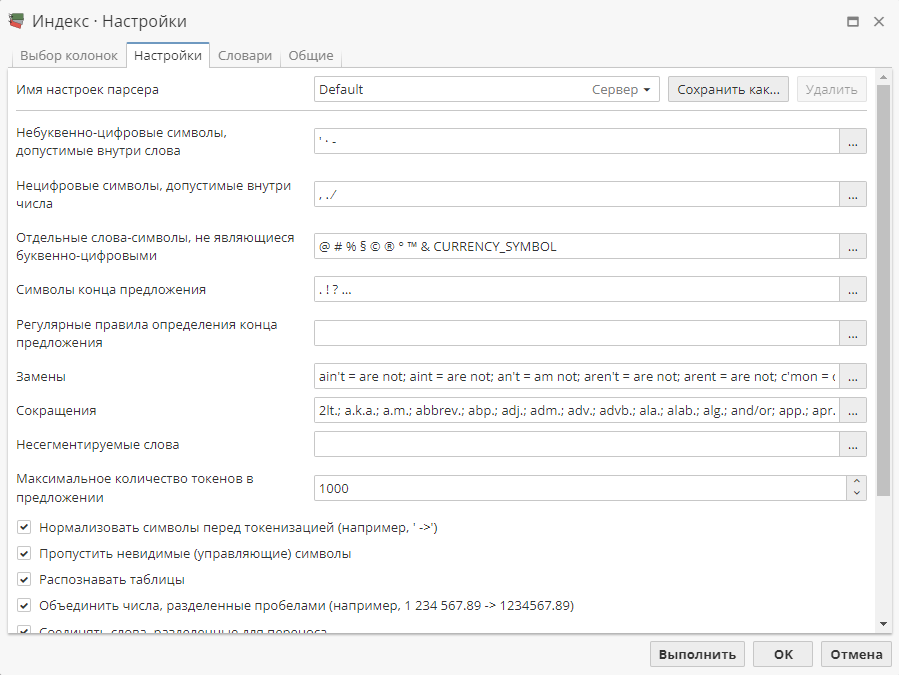
Опция Имя настроек парсера позволяет вам сохранять текущие настройки на вкладке Настройки. Парсер Default, используемый по умолчанию, хранится на сервере. Пользователь может создавать собственные парсеры и сохранять их как на сервере, так и внутри проекта. Последнее позволит вам копировать настройки парсера при экспорте проектов и словарей.
Если вы измените текущие настройки, рядом с названием этого парсера появится отметка о том, что парсер был изменен: Default (modified) (справедливо для нативного клиента) или иконка карандаша (для веб-клиента PolyAnalyst). Для того, чтобы сохранить новый парсер, укажите путь его сохранения, используя кнопку Сохранить на сервере/Сохранить в проекте, и введите название парсера.
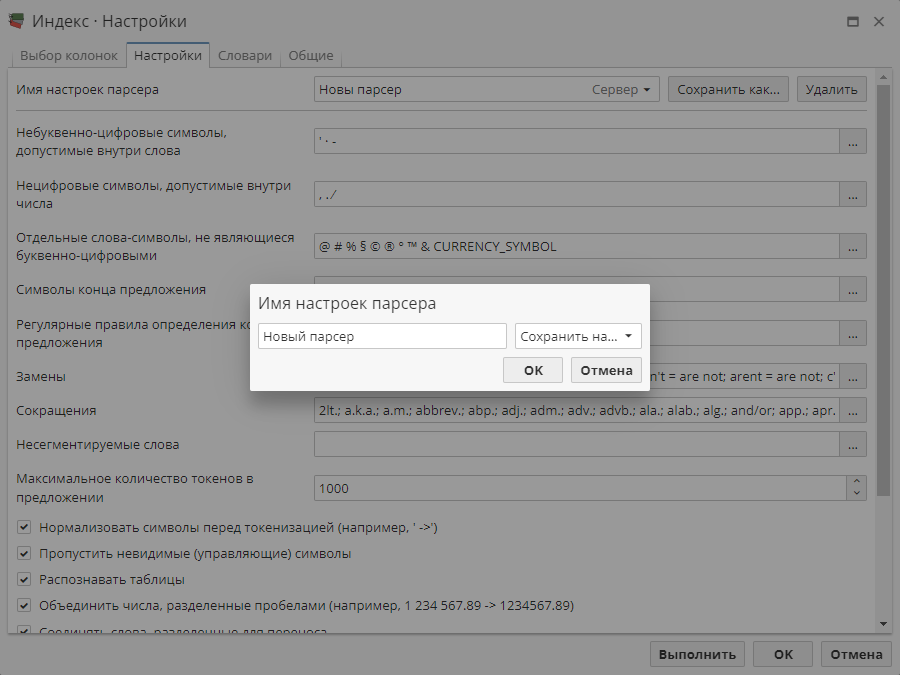
Теперь вы сможете переключиться с настроек по умолчанию к сохраненным настройкам парсера.
Дело в том, что полная настройка узла Индекс может потребовать достаточно много времени. Если в своем анализе вы используете несколько узлов индексации текста, вероятно, удобнее будет воспользоваться готовым набором настроек, который вы создали ранее. В таком случае вам не придется беспокоиться о настройке каждого нового узла Индекс и координации настроек узлов индексации в других проектах (или на ранних стадиях одного и того же проекта). Используя одинаковые настройки, вы можете получить одинаковый, прогнозируемый результат.
При работе с парсерами необходимо учитывать ряд важных моментов:
-
Если вы не сохраните парсер после редактирования опций и переключитесь к парсеру, используемому по умолчанию, внесенные вами изменения будут сброшены, и вы не сможете их восстановить.
-
При создании нового парсера необходимо сначала изменить все необходимые настройки на вкладке, выбрать место хранения парсера, указать имя и нажать ОК. Новый парсер будет доступен во всех последующих узлах индексации текста.
-
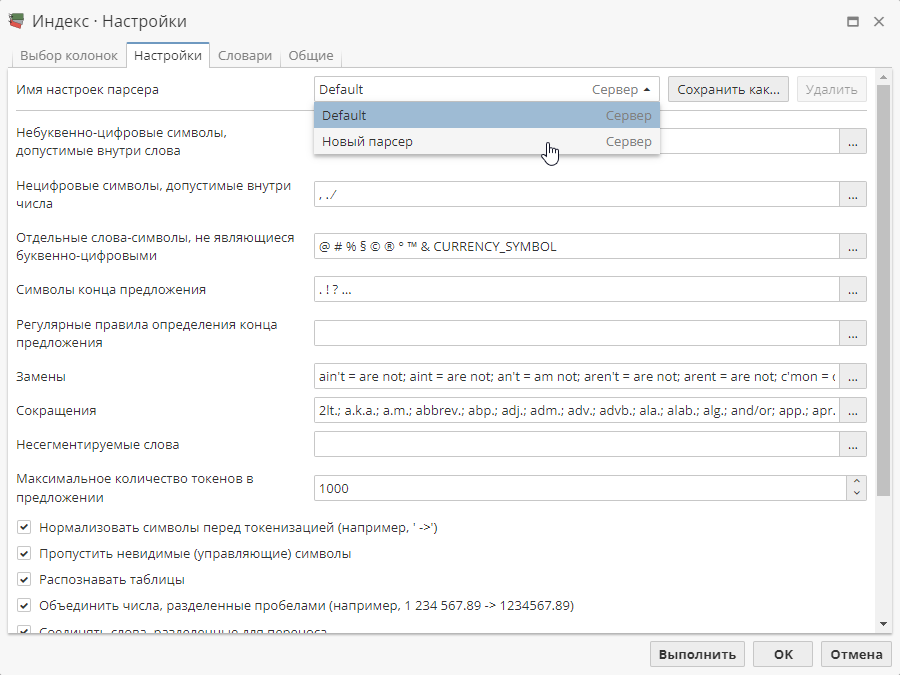
Чтобы переключиться на набор сохраненных опций, выберите имя набора сохраненных опций в меню. Остальные опции на вкладке немедленно обновятся согласно сохраненным настройкам.
-
Если словарь находится и проекте, и на сервере, в выпадающем меню Имя настроек парсера будет отображен только проект (опции парсера, используемые в текущем проекте, будут отображены в интерфейсе).
-
Чтобы удалить набор сохраненных опций, выберите имя парсера в меню и нажмите кнопку Удалить на сервере/Удалить в проекте в правом верхнем углу окна. Нажмите Да, если понадобится подтверждение действия. PolyAnalyst снова будет использовать настройки по умолчанию.
-
Вы не можете назвать ваш новый набор настроек Default (По умолчанию). Это имя зарезервировано системой PolyAnalyst.
| В качестве альтернативы сохранению настроек парсера с последующим их использованием в различных узлах Индекс, вы всегда можете скопировать и вставить узлы индексации, которые вы настроили ранее, в новые проекты или в тот же проект. При копировании и вставке узла его настройки также копируются. Этот метод предпочтителен тогда, когда метод сохранения настроек парсера кажется вам неудобным или слишком сложным. |
| При экспорте проектов экспортируются серверные настройки не по умолчанию и проектные настройки парсеров. |
Настройка опции Небуквенно-цифровые символы, допустимые внутри слова
Прежде чем говорить о назначении данной опции, важно иметь четкое представление о том, как PolyAnalyst индексирует данные. PolyAnalyst уже знает, что символы от "a" до "я" в верхнем или нижнем регистре, скорее всего, являются частью слов. Ему также известно, что цифры от 0 до 9 – символы, которые могут быть частью слова. Эти фоновые знания используются в процессе индексирования и не подлежат изменению. Однако вы можете сделать так, чтобы другие символы рассматривались как часть слова.
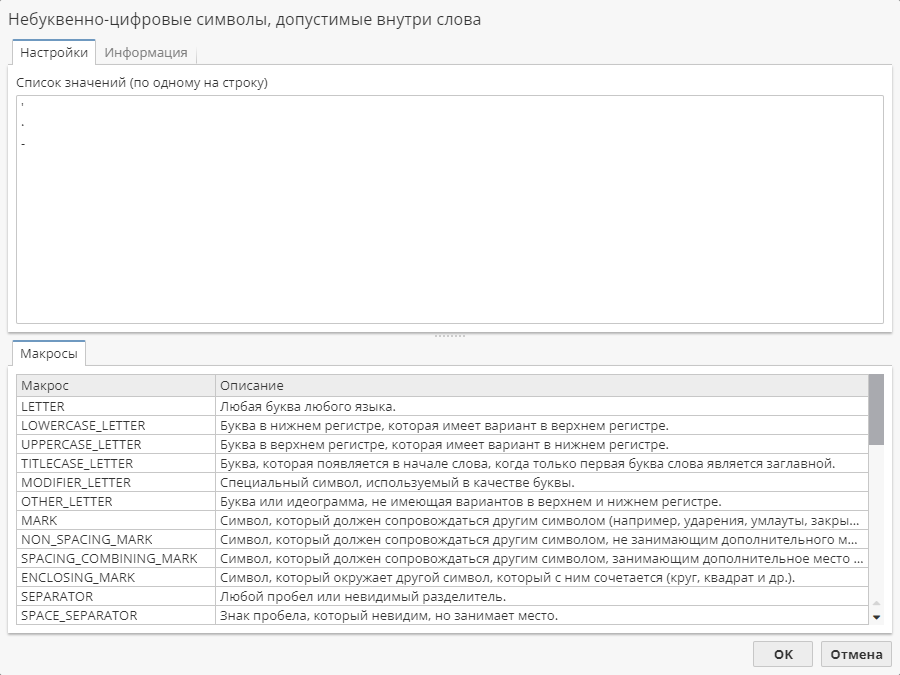
По умолчанию в этом поле будут указаны следующие символы, допустимые в словах:
-
апостроф (
') -
интерпункт (
.) -
знак дефиса (
-)
Символы внутри этого поля разделяются пробелами, но сам пробел не рассматривается как символ, допустимый внутри слова.
Вы можете добавить дополнительные, или наоборот, удалить ненужные символы из поля. Кнопка со знаком многоточия (…) справа позволяет открыть окно, в котором отдельные символы отображаются по одному на строке, что делает редактирование отдельных документов более удобным и снижает риск ошибок.
Выбор символов, которые допускаются внутри слова, может значительно повлиять на результаты анализа. Рассмотрим упрощенный вариант работы инструмента для анализа тональности текста, который может использовать такое правило: "если текст содержит последовательность didn’t like X, то X имеет негативную модальность". Это правило будет нарушено, если символ ' не будет рассматриваться как часть последовательности didn’t; в результате мы получим неточный вывод о тональности текста. Вы можете полностью изменить результаты последующего анализа путем простого изменения списка допустимых символов.
Настройка опции Нецифровые символы, допустимые внутри числа
Алгоритм индексирования PolyAnalyst предназначен для распознавания нескольких основных типов "слов":
-
Слова, которые состоят только из алфавитных символов (и других символов, которые, согласно . настройкам, допустимы внутри слова) – "алфавитные" слова.
-
Слова, которые состоят только из цифровых символов (цифр от 0 до 9) – "цифровые" слова.
-
Слова, которые состоят и из букв, и из цифр, называются буквенно-цифровыми терминами.
Опция Нецифровые символы, допустимые внутри числа применима только к цифровым терминам, т.е. словам, состоящим из символов 0123456789. Эта опция позволяет указать дополнительные символы, которые могут считаться частью цифрового слова.
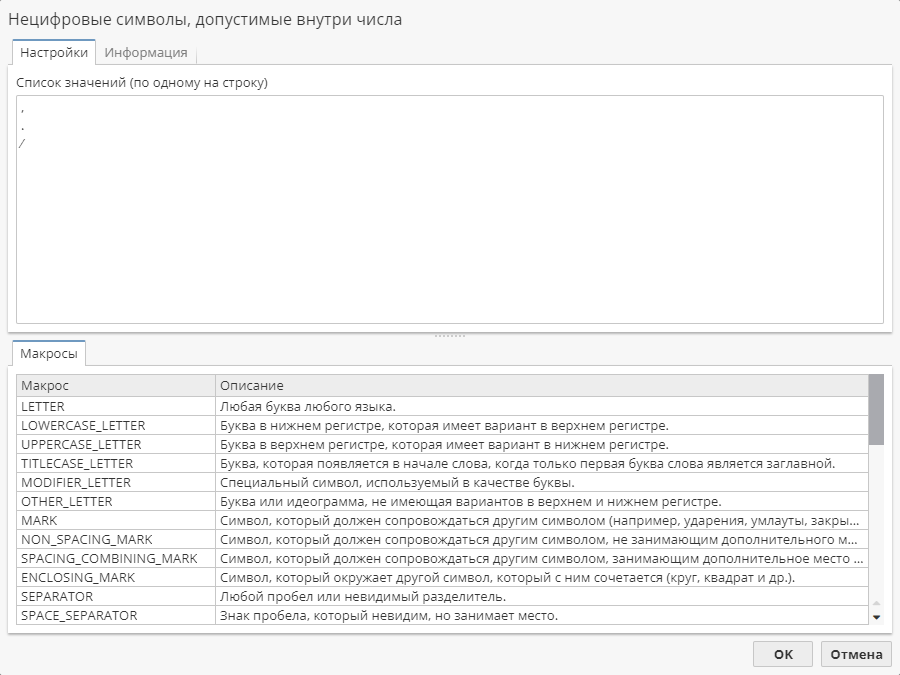
По умолчанию в этом поле будут указаны следующие символы, допустимые внутри числа:
-
запятую (
,) -
точку (
.) -
прямой слэш (
/)
Эта опция редактируется так же, как и предыдущая. Вы можете набрать значение прямо в поле, разделяя символы одним или несколькими пробелами. Вы также можете нажать на кнопку со знаком многоточия (…), чтобы отредактировать список.
В разных языках, даже в близкородственных, например, в американском и британском английском, имеются различные соглашения об обозначениях в написании чисел.
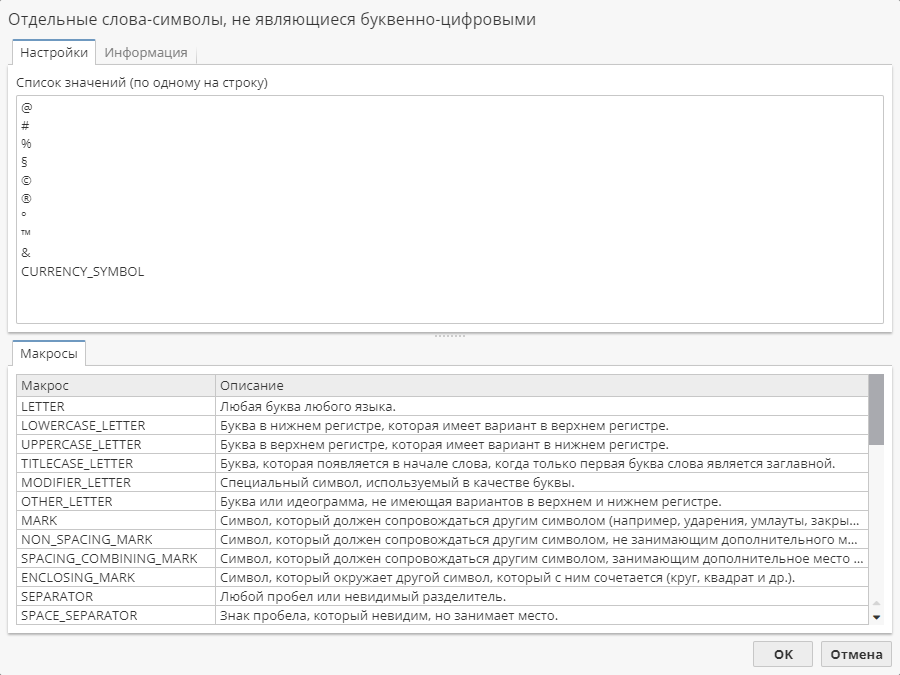
Настройка опции Отдельные слова-символы, не являющиеся буквенно-цифровыми
Эта опция менее интуитивно понятна, чем предыдущие, но в целом ее можно понять следующим образом. После того, как алгоритм приступил к задаче по выделению в тексте слов и чисел, он обнаруживает и другие последовательности символов, которые не являются ни словами, ни числами. Эта опция определяет поведение PolyAnalyst при встрече с такими типами слов. По умолчанию PolyAnalyst игнорирует такие слова, как будто их вовсе нет в документе. Однако иногда вам нужно сохранить некоторые из этих "слов", поскольку они могут представлять аналитическую ценность.
В случае, если алгоритм встречает один символ, который не является ни буквенным, ни цифровым, то он по умолчанию игнорируется. Однако, если символ считается "односимвольным словом", он сохраняется и включается в индекс как слово.
Эта опция настраивается точно так же, как и предыдущие опции. Вы можете набрать значение прямо в поле, разделяя символы одним или несколькими пробелами. Вы также можете нажать на кнопку со знаком многоточия (…), чтобы отредактировать список во всплывающем окне. Для получения информации по набору символов в этом поле см. предыдущие разделы.
Если вы испытываете трудности с набором определенных символов, которые вы не можете найти на клавиатуре, сначала наберите символ в текстовом редакторе, например, Microsoft Word, затем скопируйте его и вставьте в это поле.
Как вы уже могли заметить по настройкам данной опции по умолчанию, можно увидеть символ CURRENCY_SYMBOL. Он называется макросом.
Настройка опции Символы конца предложения
Существует много разных типов алгоритмов индексирования текста, которые в большей или меньшей степени отличаются друг от друга. В то время, как многие алгоритмы индексирования останавливаются после первого этапа обработки, или после обнаружения отдельных слов в документе, алгоритм индексирования в системе PolyAnalyst выполняет еще один этап анализа. Этот второй этап называется парсингом, или идентификацией предложений. В специальной терминологии такой анализ называется распознаванием конца предложения (анг. EOS parsing, End of Sentence parsing). Эта опция управляет параметрами процесса идентификации предложений и определяет, какие символы или последовательности символов вероятнее всего означают конец одного предложения и предшествуют началу следующего. К таким символам по умолчанию относятся точка, восклицательный знак, вопросительный знак и многоточие.
В этот список вы можете добавить свои символы конца предложения.
Каждый символ в этом списке помогает алгоритму выявить границы между предложениями. Документ, или непрерывная последовательность символов, фактически разбивается на ряд менее крупных цепочек символов, каждая из которых означает одно предложение. Без этой разбивки документ будет восприниматься как одно большое непрерывное предложение.
Разбивка документа на предложения имеет несколько преимуществ. Обратите внимание, что мы рассматриваем документы на "естественном языке", которые напоминают прозаический художественный текст, состоят из ограниченного числа абзацев и предложений. Мы знаем, что авторы используют предложения и абзацы, чтобы разделить одну большую идею на ряд мелких, и предполагаем, что в каждом предложении заключена одна уникальная мысль. Мы обращаем внимание на слова, находящиеся в определенной близости друг от друга в пределах одного документа. Мы понимаем, что если любые два отдельных слова находятся в разных предложениях, то по большому счету это означает, что они относятся к двум разным идеям. Поскольку автор уже сам организовал свои идеи в логические единицы – в отдельные предложения, мы можем использовать этот дополнительный уровень информации, чтобы обработать текст не только на уровне символов, а на уровне семантики. Таким образом, уже в самом начале анализа мы можем выделить некоторые семантические центры в текстовом документе, вместо того, чтобы просто определить случайное расположение слов в нем.
Если вы не планируете выполнять более глубокий семантический анализ текста, и точность, с которой PolyAnalyst разбивает документы на отдельные предложения, вас не интересует, вы можете просто проигнорировать эту опцию.
| Некоторые узлы в системе PolyAnalyst, например, некоторые узлы-источники данных, обладают встроенной способностью разбивать документы на предложения. Однако в таких узлах нет возможности кастомизации настроек такого разбиения (например, пользователи не могут изменить список символов конца предложения, используемый по умолчанию). Если вы считаете, что настройки по умолчанию приводят к неточным результатам, то разумнее не выполнять сегментацию текста на предложения во время импорта данных, а использовать исходные данные в первоначальном виде в узле Индекс, который предоставляет возможность пользовательской настройки парсера. Главное преимущество узла Индекс заключается в том, что благодаря тонкой настройке опций парсера, вы можете рассчитывать на более точный результат. |
Настройка опции Регулярные правила определения конца предложения
Алгоритм парсинга конца предложения исследует, какие символы или последовательности символов могут завершать предложение, а затем решает, действительно ли эти символы находятся в конце предложения. Алгоритм можно настроить так, чтобы он считал, что, например, присутствие точки не означает конец предложения. Это происходит потому, что точка используется и для других целей, например, в аббревиатуре Dr.. Обычно в этом случае анализируется ближайшее окружение символа.
Символы или последовательности символов конца предложений – это те символы, которые гарантированно означают конец предложения. Другими словами, присутствие таких символов всегда означает конец предложения. Дополнительной обработки для проверки исключений из этого правила не проводится.
Обычно, но не всегда, последовательность двух новых строк означает конец одного предложения и начало другого. Следовательно, \n\n – одно из регулярных выражений, которое можно использовать для определения конца предложений.
Настройка опции Замены
В дополнение к разбиению текста на предложения и слова, вы также можете настроить алгоритм индексирования на автоматическую замену некоторых слов или последовательностей слов другими словами. Заменой называется двухстороннее отношение слов или их последовательностей, где первая часть означает слово, которое нужно найти в исследуемых данных, а вторая часть представляет собой новый текст, который должен заменить найденный фрагмент. Замены помогают стандартизировать текст, исключая использование разных вариантов одного и того же сочетания в одном тексте.
Сокращения, которые автоматически заменяются узлом Индекс на полные формы, даны в таблице:
you’re |
you are |
we’re |
we are |
they’re |
they are |
Замена сокращений бывает необходима для работы с такими узлами, как Таксономия или Поисковый запрос: т.к. слово может быть сокращено, поиск подобного слова в тексте будет представлять собой довольно непростую задачу.
| Также можно использовать узел Замена терминов для изменения слова, поскольку он работает с необработанным текстом, и используется в проекте до индексирования. |
PolyAnalyst предоставляет вам список некоторых часто используемых замен на английском языке. Это поле уже заполнено. В отличие от остальных опций на данной вкладке, мы рекомендуем редактировать его только в отдельном всплывающем окне. Для отображения всплывающего окна нажмите кнопку со знаком многоточия справа от поля.
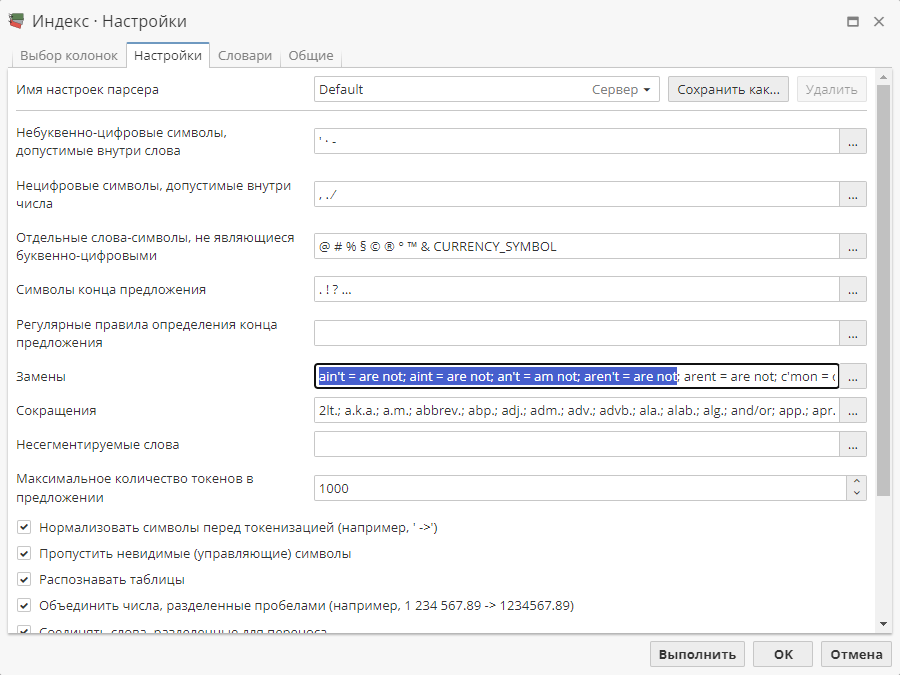
Каждая строка в открывающемся окне соответствует простому синтаксическому правилу "слово = слово". Слово слева от знака равенства – то слово, которое нужно найти в тексте. Слово справа от знака равенства есть слово, которым нужно заменить найденное ему соответствие. Например, первая строка в открывшемся окне, скорее всего, будет содержать значение ain’t = are not. Это означает, что при выполнении узла Индекс каждый раз, когда встречается слово ain’t, узел распознает это сочетание как два отдельных слова: are и not.
Настройка опции Сокращения
Парсинг предложений – один из серьезных вопросов обработки естественного языка. Оказывается, точно определить, где одно предложение заканчивается и начинается следующее, труднее, чем кажется.
Предположим, что вам нужно создать собственный подобный алгоритм, а для этого подумать о правилах, которые алгоритм должен соблюдать при движении от символа к символу в документе. Мы можем придумать некоторые очевидные базовые правила и легко получить алгоритм парсинга, дающий наполовину точные результаты. Например, мы можем создать правило, согласно которому алгоритм при обнаружении в тексте определенного символа конца предложения (точки, вопросительного или восклицательного знака) должен распознавать его как границу между словами. И это правило будет работать. Однако, что произойдет, когда в тексте встретится сокращение Dr., которое не заканчивает предложение, несмотря на наличие точки? Алгоритм ошибочно разобьет одно предложение на два, а это существенно повлияет на результаты дальнейшего анализа.
Опция Сокращения позволяет увеличить точность распознавания границ между предложениями в документе. Каждый раз, в тексте встречается одна из имеющихся в списке аббревиатур, PolyAnalyst не рассматривает содержащиеся в них точки как символы конца предложений. Если при последующем использовании узлов Поисковый запрос или Таксономия вы обнаружите, что точность парсинга недостаточно высока именно из-за аббревиатур, вы можете вернуться в настройки узла Индекс и дополнить список сокращений.
Так же, как и в случае с редактированием поля Замены, рекомендуем редактировать это поле только во всплывающем окне, которое появляется при нажатии на кнопку со знаком многоточия (…) справа от поля. Всплывающее окно отображает по одной аббревиатуре на строку. Список по умолчанию содержит часто встречающиеся сокращения. Вы можете добавить другие сокращения в список или удалить некоторые аббревиатуры, если вам кажется, что алгоритм парсинга текста работает недостаточно эффективно.
Настройка опции Несегментируемые слова
В данном поле могут быть указаны несегментируемые слова, т.е. такие токены, которые считаются неразделяемыми.
Это может быть важно, например, при парсинге текста, где встречаются такие имена собственные, в названии которых содержится знак препинания (см. "Яндекс.Диск", "Яндекс.Дзен" и т.д.). По умолчанию парсер распознает подобную структуру, как слово (Яндекс), знак препинания (.) и еще одно слово.
| Такие несегментируемые паттерны остаются единым токеном независимо от других настроек парсера. |
Вы можете указать свои собственные несегментируемые слова, нажав на кнопку со знаком многоточия (…), например, для указания других имен собственных.
Также можно добавить список слов из словарей Wordclasses (словари классов слов).
Подробнее о словарях классов словарей см. здесь.
Настройка опции Максимальное количество токенов в предложении
Данное поле позволяет задать максимальное количество токенов в предложении без учета знаков препинания. Например, если количество токенов равно 3, то все последовательности из 3 слов и менее будут рассматриваться как одно предложение.
По умолчанию значение равно 1000. Средняя длина предложения в русском языке намного меньше данного значения. Другими словами, 1000 токенов будет вполне достаточно, чтобы узел правильно проиндексировал текст и корректно разбил его на предложения, ориентируясь на указанные символы конца предложений или заданные правила определения конца предложения.