Настройка узла Извлечение терминов
Окно настроек узла Извлечение терминов разбито на три вкладки. На вкладке Колонки выберите исходную колонку, а также укажите дополнительные колонки, которые необходимо включить в отчет узла. На вкладке Настройки добавьте правила и атрибуты. На вкладке Общие отредактируйте имя и описание узла. Подробное описание вкладок представлено ниже.
Настройка вкладки Колонки
На вкладке Колонки выберите текстовую колонку, которая будет использоваться в качестве исходной. По данной текстовой колонке будет осуществляться поиск заданных паттернов. Также данная колонка будет использоваться при создании других колонок согласно указанным опциям. Выберите колонку в списке Доступные колонки слева и нажмите на кнопку с изображением стрелки. Вы также можете перетащить необходимую колонку из списка в поле Выбранная колонка:
Для того, чтобы исключить исходную колонку из массива выходных данных, отметьте галочкой опцию Убрать колонку из результата. Иногда сохранение исходных записей может быть полезным при просмотре результатов и последующем анализе. С другой стороны, получение массива данных, который включает только найденные соответствия и первичные ключи из массива исходных данных позволяет сократить число колонок в таблице выходных данных, упростив тем самым ее вид.
В разделе Колонка с результатами отметьте галочкой опцию Создать колонку с соответствием (имя колонки можно изменить в соответствующем поле, по умолчанию имя колонки Match) для включения колонки с результатами поиска в массив выходных данных. Данная колонка будет содержать сегменты текста, которые соответствуют правилам, добавленным на вкладке Настройки.
Используйте выпадающее меню Тип для выбора типа данных в колонке с найденными соответствиями. По умолчанию используется значение строка. Строковый тип данных, как правило, применяется в случаях, когда в ходе последующего анализа или обработки данных планируется рассматривать значения колонки как категориальные. Если же вы хотите выделить крупные фрагменты текста, то для этого больше подойдет текстовый тип, поскольку при этом вы снижаете риск потери данных при превышении установленного для строкового типа данных ограничения в 256 символов.
В разделе Дополнительные колонки отметьте галочкой опцию Имя сработавшего правила для создания колонки, содержащей имя правила. При необходимости вы можете изменить имя колонки в поле справа. Рекомендуется добавлять данную колонку в отчет узла при работе с несколькими правилами.
Отметьте галочкой опцию Подсчет извлеченных терминов для добавления колонки, в которой будет указан порядковый номер соответствия в пределах одной записи. Имя колонки можно изменить в соответствующем поле справа.
Опции раздела Колонки с позициями найденных подстрок позволяют настроить отображение дополнительной информации о каждом соответствии (каждой записи в массиве выходных данных). Отметьте галочкой необходимую опцию для включения соответствующей колонки в массив выходных данных:
-
Документ – сохраняет номер записи исходного текста. Например, если правило нашло первую запись в массиве исходных данных дважды, то в отчет узла будут добавлены две записи, и каждая запись в данной колонке будет содержать значение 1.
-
Первое предложение – сохраняет номер предложения, в котором начинается найденный сегмент. Например, если сегмент был найден в первом предложении исходного текста, то в данной колонке сохранится значение 1.
-
Первый токен – сохраняет позицию первого токена из найденного сегмента относительно начала предложения. Токены – это отдельные части предложения, которые выделяются парсером.
-
Последнее предложение – сохраняет номер предложения, в котором заканчивается найденный сегмент. Например, если найденный сегмент заканчивается во втором предложении исходного текста, то в данной колонке сохранится значение 2.
-
Последний токен – сохраняет позицию последнего токена из найденного сегмента относительно начала предложения.
-
Начальный символ – сохраняет номер символа, с которого начинается найденный сегмент.
-
Длина в символах – сохраняет количество символов в найденном сегменте текста.
Например, если найденный сегмент состоял из трех символов, то в данной колонке сохранится значение 3. Это примерно то же самое, как если бы мы добавили дочерний узел Производные колонки для создания колонки с применением SRL-функции len() для подсчета количества символов в каждой строке колонки Match.
Опции вкладки Настройки
Вкладка Настройки выглядит следующим образом:
Таблица в левом верхнем углу содержит правила, при желании в поле ниже добавьте описание правила. Справа расположен редактор, где составляется регулярное выражение для правила. Под редактором расположены опции, которые позволяют дополнительно настроить поведение правил.
Создание правила
Для создания нового правила нажмите на кнопку с изображением плюса в левом верхнем углу.
Вы также можете нажать правой кнопкой мыши на пустую область в пределах таблицы правил и выбрать Добавить в контекстном меню. Каждое новое правило перемещается в конец таблицы. Если после добавления нового правила вы не можете найти его в таблице, попробуйте прокрутить список вниз.
У каждого правила должно быть имя. Когда вы создаете новое правило, PolyAnalyst присваивает ему имя по умолчанию (Правило 1). При создании каждого нового правила индекс в имени колонки увеличивается на один.
Для того, чтобы изменить имя правила, нажмите на текущее значение в таблице. Для сохранения изменений используйте клавишу Enter или переключитесь с помощью мыши на любое другое поле.
Выбор правила
Для того, чтобы выбрать правило, нажмите на соответствующую строку в таблице.
Когда вы добавляете новое правило, оно автоматически выбирается в таблице. Важно следить за тем, какое именно правило выбрано в таблице. Выбранное правило подсвечивается синим цветом. Когда вы редактируете выражение или добавляете описание, значения соответствующих полей будут относиться именно к текущему выбранному правилу. Поскольку новое правило выбирается автоматически после добавления, вы можете сразу перейти к составлению выражения в поле редактора.
Удаление правила
Для удаления правила выберите его в таблице и нажмите на кнопку Удалить на панели инструментов. Вы также можете нажать правой кнопкой мыши на имя правила и выбрать Удалить.
Изменение порядка следования правил
Для того чтобы переместить правило вверх или вниз по таблице, выберите его в списке и нажмите на соответствующую кнопку в виде стрелки на панели инструментов.
Импорт и экспорт правил
Для выполнения экспорта списка правил нажмите на соответствующую кнопку на панели инструментов.
В выпадающем меню укажите тип файла (*.csv или *.ini), его имя и путь для сохранения.
Файлы сохраняются на вашем собственном компьютере (с которого запущен клиент PolyAnalyst), при этом сервер PolyAnalyst может работать на другом компьютере. Если другой пользователь при работе на своем компьютере в процессе редактирования настроек узла попытается импортировать ваш файл с сохраненными правилами, то он скорее всего не сможет его найти. Во избежание подобных случаев вы можете сохранить файл с правилами на общий сетевой диск или в аналогичном хранилище.
| При экспорте ini-файла PolyAnalyst осуществляет экранирование символов, а также ожидает корректно экранированные значения на входе при выполнении импорта. |
Если имя импортируемого правила совпадает с именем текущего правила в таблице, то последнее будет заменено.
Добавление правил в библиотеку
Для добавления созданного правила в библиотеку нажмите на соответствующую на панели инструментов либо правой кнопкой мыши нажмите на правило в списке правил и выберите опцию Добавить в библиотеку.
Более подробно об использовании библиотеки правил здесь.
Создание атрибутов для правил
Для того чтобы ускорить процесс создания атрибута для вашего правила, нажмите на кнопку Клонировать на панели инструментов.
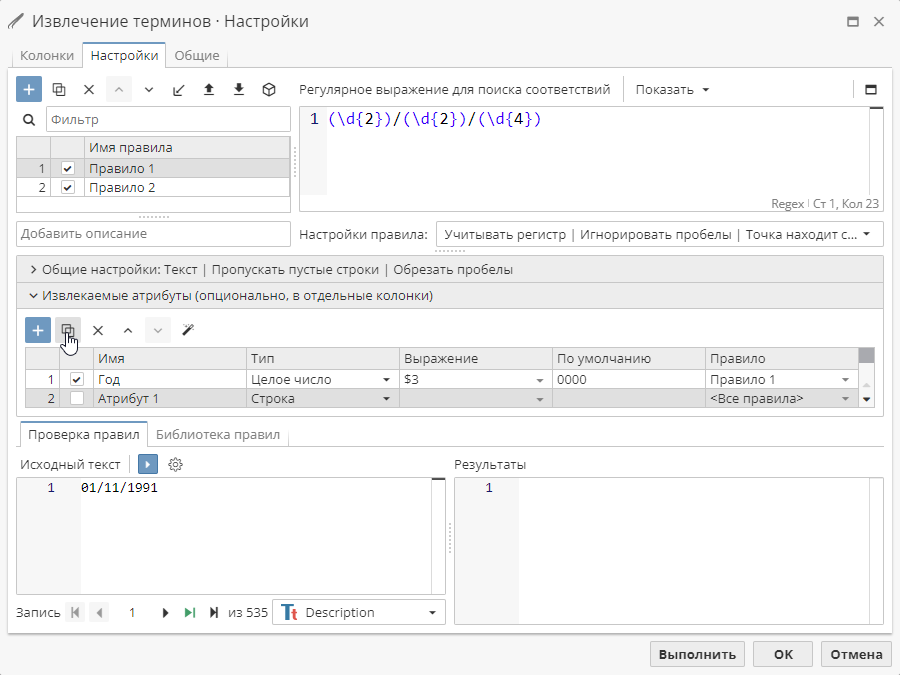
Созданный атрибут появится в таблице Извлекаемые атрибуты в центральной части окна и готов для редактирования.
Удаление и работа с несколькими правилами одновременно
Для выбора нескольких правил в таблице удерживайте клавишу Ctrl при нажатии на имя правила. Для выделения группы правил вы также можете сначала выбрать первое правило, зажать клавишу Shift, затем выбрать последнее правило, при этом автоматически будут выделены и все промежуточные позиции списки. Для снятия выделения нажмите на имя выделенного правила, удерживая клавишу Ctrl.
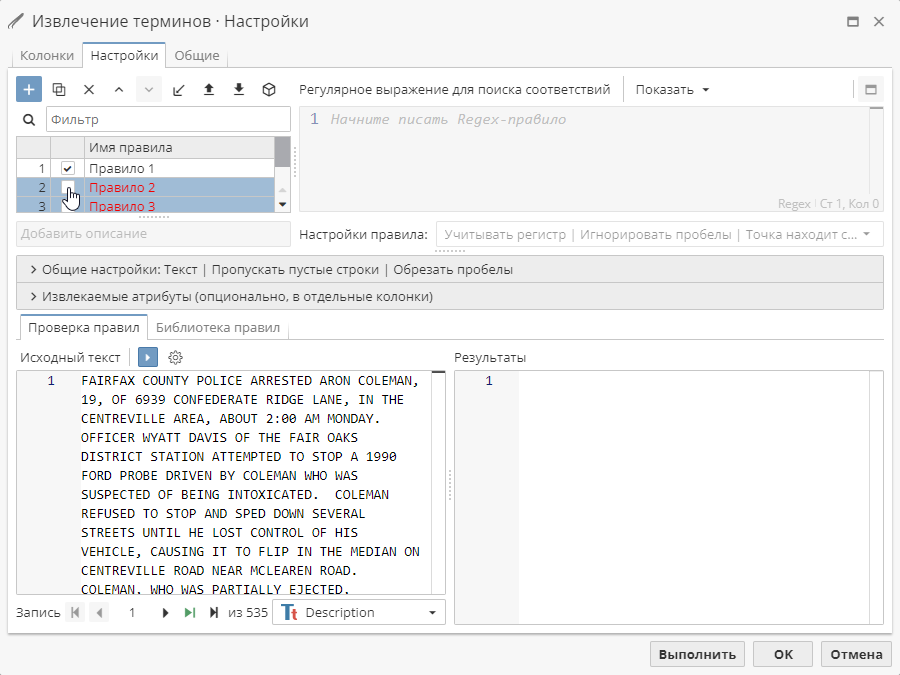
Выбранную группу правил можно копировать, удалять, перемещать вверх или вниз по таблице, а также включать/отключать, выбрав соответствующую опцию в контекстном меню.
Включение и выключение правил
При работе с правилами и различными настройками узла Извлечение терминов иногда лучше отключить правило, вместо того, чтобы удалять его. Составление выражения для некоторых правил – достаточно трудоемкий процесс, поэтому полезнее будет сохранить правило, чтобы использовать его в качестве возможного источника или примера при работе с другими правилами.
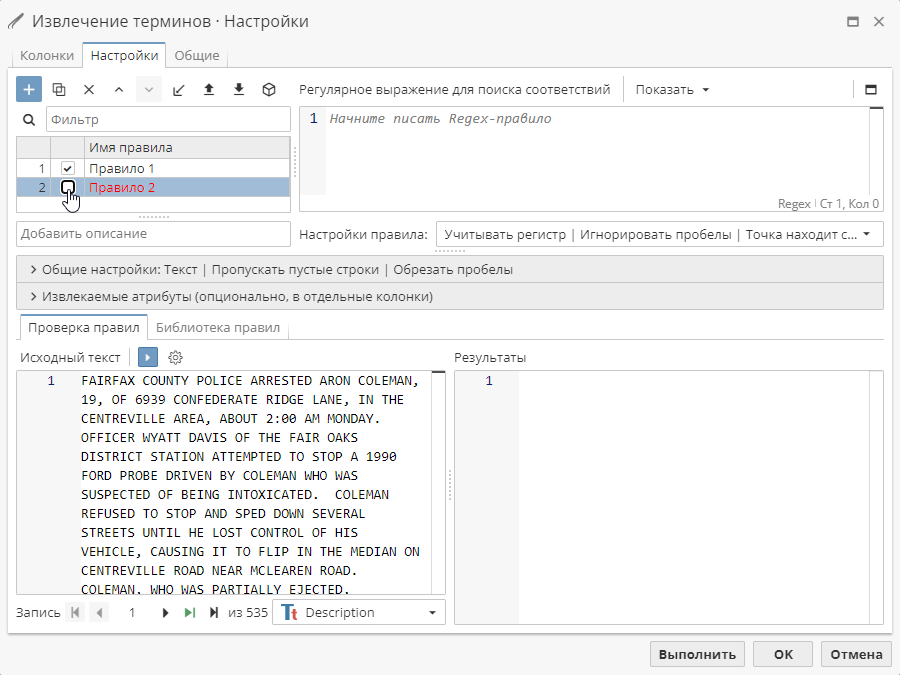
Для отключения правила снимите галочку с флажка рядом с именем правила. Для повторного включения правила нажмите на флажок.
Настройка выражения правила
Для настройки выражения выберите правило в таблице, после чего введите выражение в большую текстовую область справа.
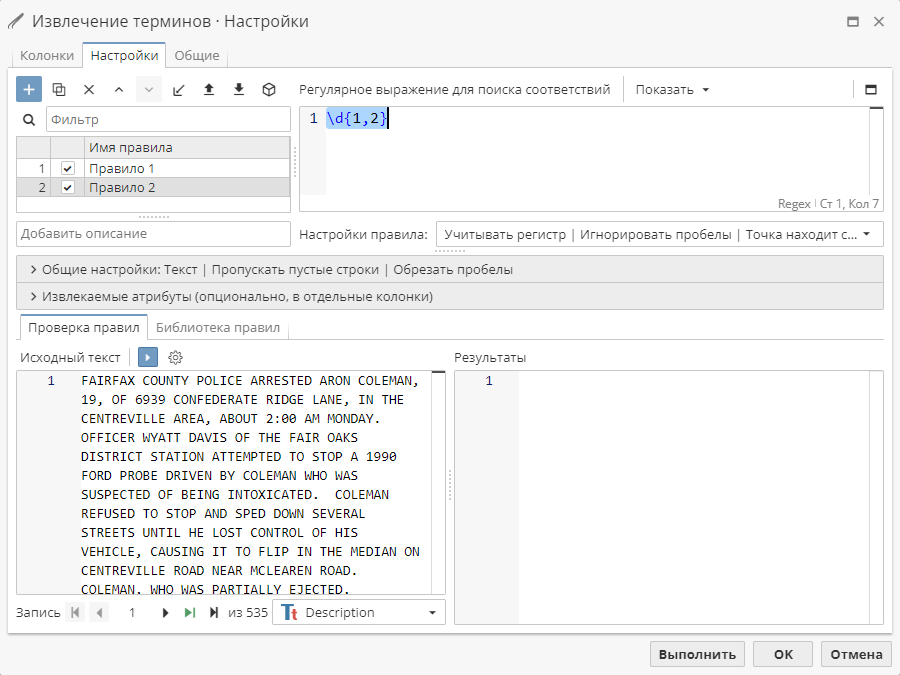
Правила узла Извлечение терминов используют синтаксис регулярных выражений. Для получения подробной информации см. руководство по написанию регулярных выражений.
Настройка дополнительных параметров правила
Используйте выпадающее меню Настройки правила под редактором выражений для управления дополнительными параметрами извлечения терминов.
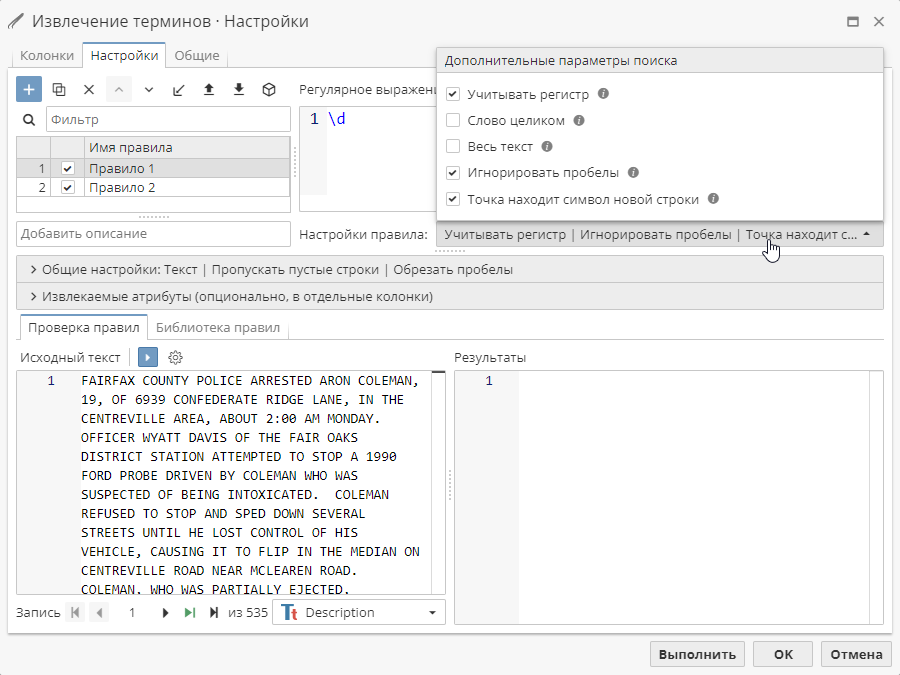
По умолчанию опция Учитывать регистр включена. Отключите ее, чтобы поиск совпадений выполнялся без учета регистра. В большинстве случаев выражение удобнее составлять с использованием символов нижнего регистра, которые будут соответствовать символам и верхнего, и нижнего регистра в тексте. Однако в определенных случаях, например, при поиске названий компаний, учет регистра будет крайне полезен.
При включении опции Слово целиком в результаты будут включены только абсолютные совпадения.
Несмотря на вышеприведенный пример пользователям следует воздержаться от включения данной опции, если конечной целью не является поиск конкретных слов. Вернемся к примеру с поиском фрагментов, которые характеризуют возраст людей. Парсер может быть настроен на разграничение слов с помощью дефиса. Это приведет к тому, что правило не найдет соответствий в тексте, поскольку поиск будет осуществляться в пределах границ слов.
Включите опцию Весь текст для того, чтобы извлекать отдельные тексты, которые соответствуют правилу.
По умолчанию опция Игнорировать пробелы включена, что позволяет извлекать последовательности символов независимо от наличия в них пробелов.
При включении опции Точка находит символ новой строки узел будет рассматривать метасимвол точки (.) как соответствующий любым другим символам, включая символ перевода строки.
Для регулярных выражений установлен порог перебора не более 500 000 000 комбинаций. Это сделано для предотвращения ReDoS-атак (regular expression denial of service). При необходимости перебора большого количества комбинаций рекомендуем устанавливать либо максимальную длину (например, .{1,1000}SECTORS), либо указать, с какого значения необходимо выполнить поиск (например, \A(.*)SECTORS). В противном случае узел будет выполнен с ошибкой "Множественное переполнение стека – количество возможных комбинаций букв превышает 500 миллионов (на текст)".
|
Настройка раздела Общие настройки
Меню Общие настройки, расположенное под полем Описание, содержит ряд опций, которые позволяют настроить режим работы узлы:
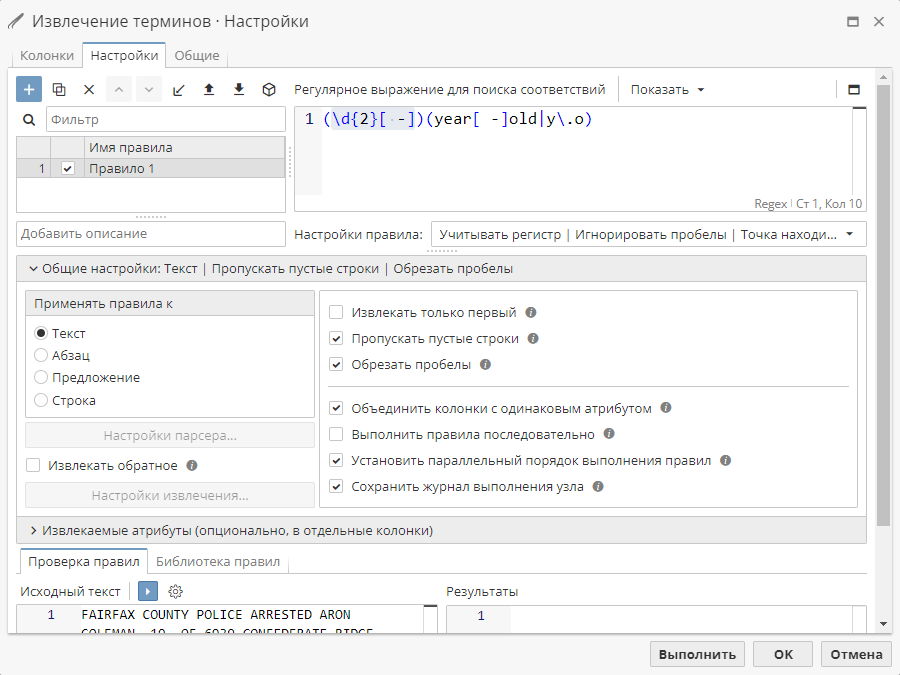
Узел Извлечение терминов может выполнить обработку всей исходной таблицы построчно, либо предварительно разбить текст на абзацы и предложения. В последнем случае пользователю необходимо выбрать необходимый режим с помощью радиокнопок в разделе Применять правила к. Когда строка разбивается на составные элементы (абзацы/предложения/строки), узел Извлечение терминов рассматривает каждый из сегментов как отдельную строку.
Дополнительные параметры парсинга текста на абзацы и предложения настраиваются в отдельном окне, открыть которое можно с помощью кнопки Настройки парсера.
Доступные в окне Настройки парсера опции аналогичны тем, что представлены в окне настроек узла Индекс. Для получения подробной информации см. раздел Настройка узла Индекс.
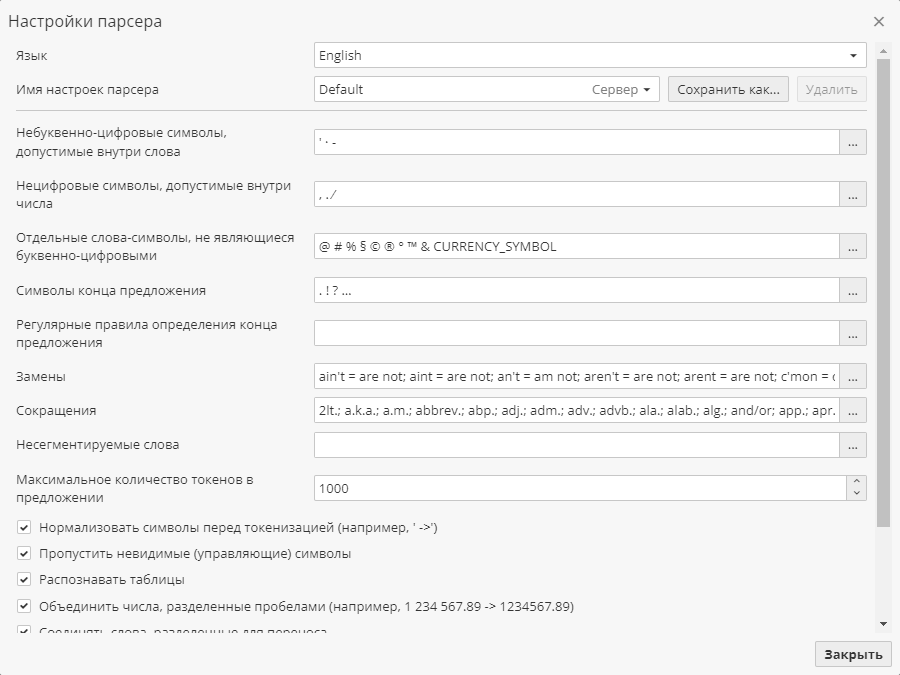
Обычно правило может находить в одной строке текста сразу несколько соответствий. При этом в таблицу выходных данных для каждого случая будет добавлена отдельная строка. Отметьте галочкой опцию Извлекать только первый, чтобы ограничить выходные данные только первым соответствием.
Отметьте галочкой опцию Пропускать пустые строки для исключения из выходных данных строк, которые не имеют соответствий. Обычно такие строки включаются в выходной массив данных, но имеют пустые значения для остальных колонок (например, для колонки Match).
Отметьте опцию Обрезать пробелы, чтобы обрезать значения в колонке Match. Эта опция полезна тогда, когда найденные соответствия включают пробелы, которые стоят до или после извлеченного значения, и вы планируете использовать подобные сегменты в виде категориальных значений (например, сохранить их как строковые). Если опция включена, значения с пробелами будут рассматриваться так же, как и значения без пробелов.
При включении опции Извлекать обратное в результаты будут включены только те фрагменты текста, для которых не были найдены соответствия.
Дополнительные параметры извлечения настраиваются в отдельном окне, открыть которое можно с помощью кнопки Настройки извлечения.
При включенной опции Извлекать обратное выражение рассматривается как разделитель (оно разделяет значения).
Если опция Извлекать обратное включена, а в исходных данных встречается текстовое значение, которое не соответствует правилу, выступающему в качестве разделителя, то обычно такое значение не включается в выходной массив данных.
Если включить опцию Пропускать строки без разделителя, то данная строка наоборот будет добавлена в выходной массив данных (для этого нажмите кнопку Настройки извлечения чтобы открыть меню настроек извлечения).
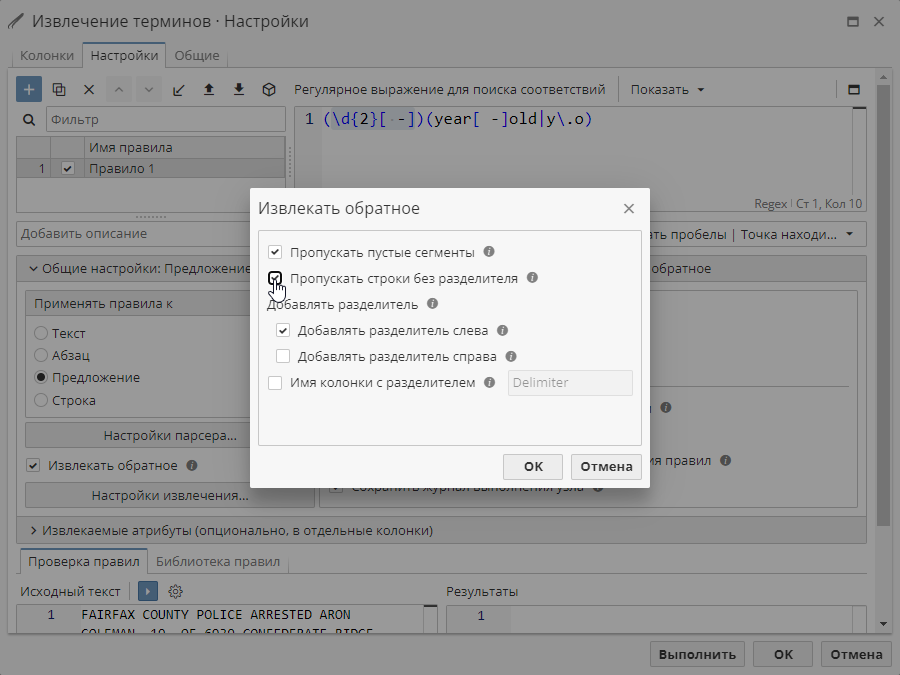
Если опция Извлекать обратное включена, и были найдены соответствия, то несоответствующие правилу части текста будут включены в выходные данные. При включении опции Добавлять разделитель в выходные данные будут включены как несоответствующие, так и соответствующие части текста.
Если опция Добавлять разделитель включена, к выходным данным добавляется новая колонка. Имя колонки можно изменить в поле справа. Значением данной колонки выступает сам разделитель.
Если опция Добавлять разделитель включена, то разделитель также будет включен в выходные данные. Он появится как часть текста до или после соответствия, поскольку соответствие и есть разделитель.
Если включена опция Сохранить журнал выполнения узла, в дополнение к массиву данных PolyAnalyst создаст специальный отчет. На скрипте нажмите правой кнопкой мыши на выполненный узел Извлечение терминов и выберите Показать журнал. Журнал содержит информацию по конкретным соответствиям и сведения об обработке исходных данных. Журнал будет содержать соответствующий отчет вне зависимости от настроек других опций.
По умолчанию узел Извлечение терминов создает отдельную колонку для каждого атрибута из таблицы Извлекаемые атрибуты. При большом количестве атрибутов это может привести к переполнению отчета. При включении опции Объединить колонки с одинаковым атрибутом колонки атрибутов с одинаковыми именами будут объединены в одну.
| Если атрибуты содержат разные типы данных, объединение колонок выполняться не будет. Вместо этого к названию колонки будет добавлен индекс, например, Атрибут1. Обратите внимание на то, что в поле Проверка правил определение типов данных не выполняется, поэтому здесь подобные колонки с одинаковыми именами могут быть объединены в одну, таким образом результаты в области предварительного просмотра будут отличаться от фактических. |
По умолчанию узел работает в режиме Установить параллельный порядок выполнения правил. В этом случае каждое правило будет использовать свой механизм поиска для формирования независимых результатов. Если вы хотите, чтобы результат одного правила выступал в качестве источника для другого, отметьте галочкой опцию Выполнять правила последовательно.
Таким образом, правила будут применяться в порядке следования в списке. Одновременное включение обеих опций не предусмотрено. Также не рекомендуется отключать обе опции, т.к. это может привести к наложению совпадений (правила, которые находятся ближе к началу списка будут иметь больший приоритет, чем остальные) и искажению результатов.
Настройка атрибутов
Таблица Извлекаемые атрибуты находится в центральной части окна.
Для создания атрибута нажмите на кнопку с изображением плюса на панели инструментов, которая расположена над таблицей атрибутов.
Каждый атрибут определяется следующими параметрами:
Имя – имя атрибута. Данное имя будет использовано для обозначения колонки, содержащей значение атрибута, в таблице выходных данных. Для изменения имени установите курсор в соответствующее поле и введите новое значение. Для сохранения изменений установите курсор в другое поле или раздел.
Тип – тип данных атрибута. Определяет тип данных колонки в результирующей таблице. По умолчанию для каждого нового атрибута используется Строка. Для изменения типа нажмите на текущее значение и выберите необходимый тип данных в выпадающем меню.
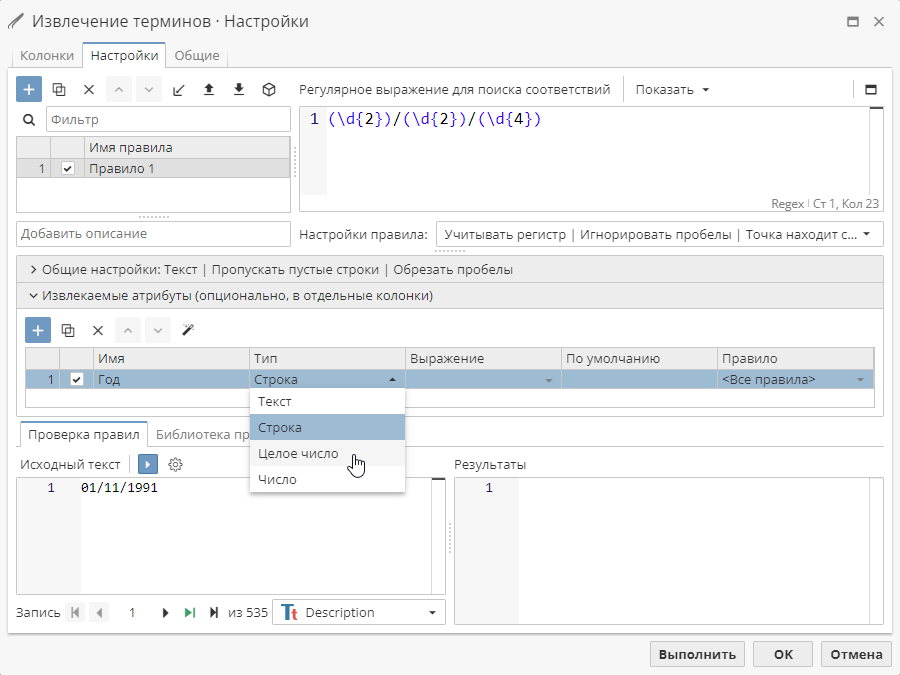
При этом убедитесь, что извлекаемый атрибут соответствует указанному типу.
Выражение – выражение для атрибута. Используйте символы \ или $ в сочетании с порядковым номером для ссылки на часть правила.
При составлении правила вы можете условно разбить его на части с помощью круглых скобок.
Узел Извлечение терминов также поддерживает использование именованных групп в выражении.
По умолчанию – если атрибут не содержит значение, что иногда происходит при работе с регулярными выражениями, использующими условную логику (например, найти фамилию человека, перед которой может стоять обращение "господин" или "госпожа").
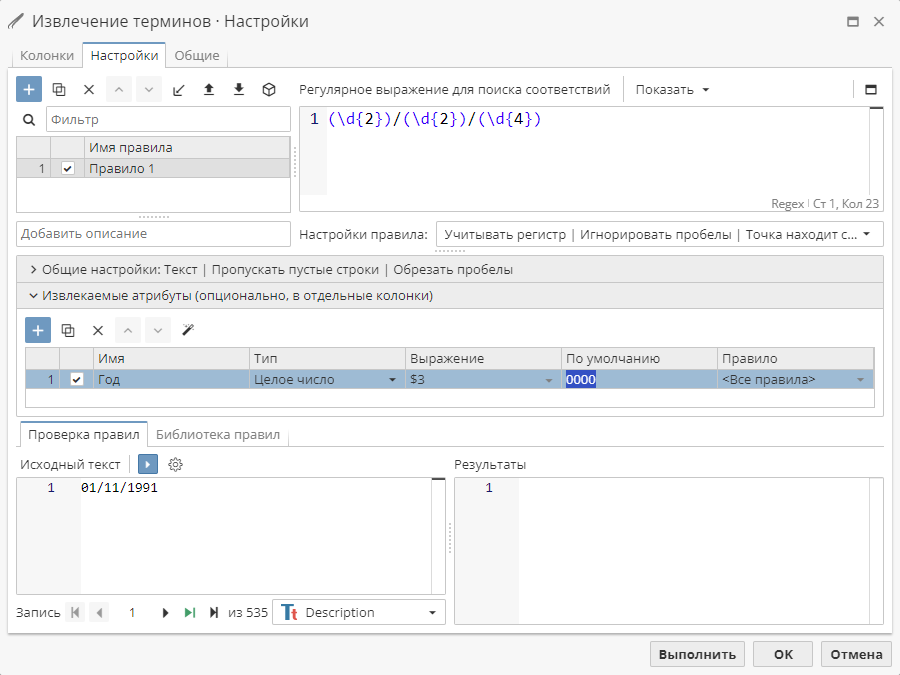
Вы можете указать значение по умолчанию, которое будет добавлено в результирующую колонку атрибута.
Правило – атрибут может применяться ко всем или только к конкретным правилам. По умолчанию каждый атрибут применяется ко всем правилам (<Все правила>). Для изменения режима работы атрибута нажмите на текущее значение и отметьте галочкой необходимые правила в списке.
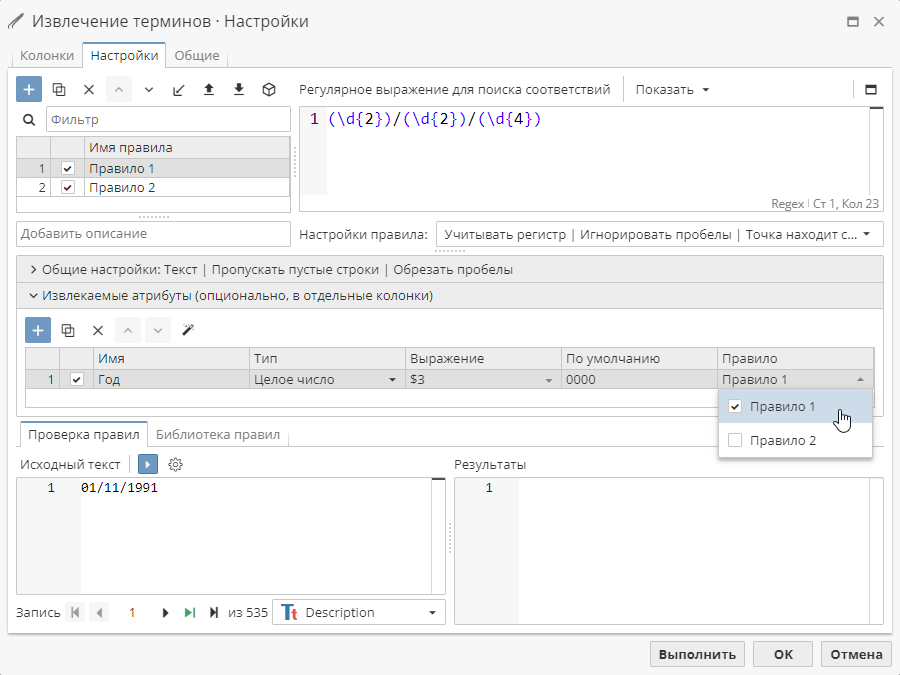
Даже если правило в последующем будет переименовано, повторная настройка атрибута не потребуется.
Отметьте атрибут галочкой, чтобы включить/отключить его.
Для добавления копии выбранного атрибута в таблицу нажмите кнопку Клонировать на панели инструментов.
Для удаления выбранного атрибута нажмите Удалить на панели инструментов.
Для перемещения выбранного атрибута по таблице вверх или вниз используйте соответствующие стрелки на панели инструментов.
Если выражение выбранного правила содержит именованные группы, нажмите кнопку Выполнить автозаполнение атрибутов для автоматического добавления настроенного атрибута для каждой группы.
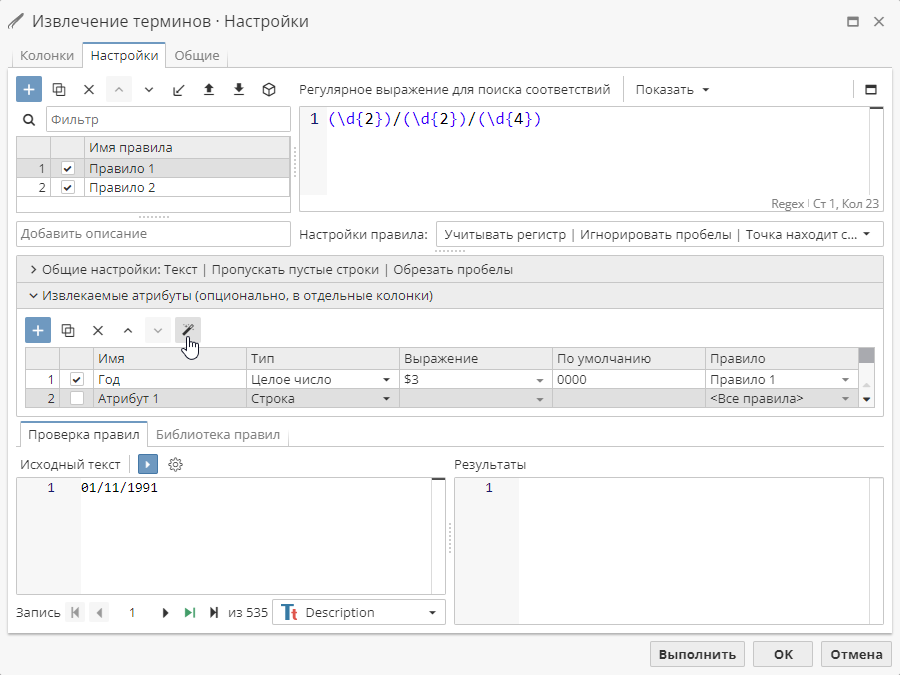
Если вы настраиваете атрибуты вручную, то при добавлении в поле Выражение символа $ откроется список доступных именованных групп. Нажмите на элемент списка, чтобы использовать его в вашем выражении.
Проверка правил
Для того, чтобы проверить работу созданных правил, переключитесь на вкладку Проверка правил в левом нижнем углу и нажмите на кнопку с изображением стрелки. PolyAnalyst выполнит обработку правил и в случае успеха покажет, как будут выглядеть колонки в выходной таблице данных:
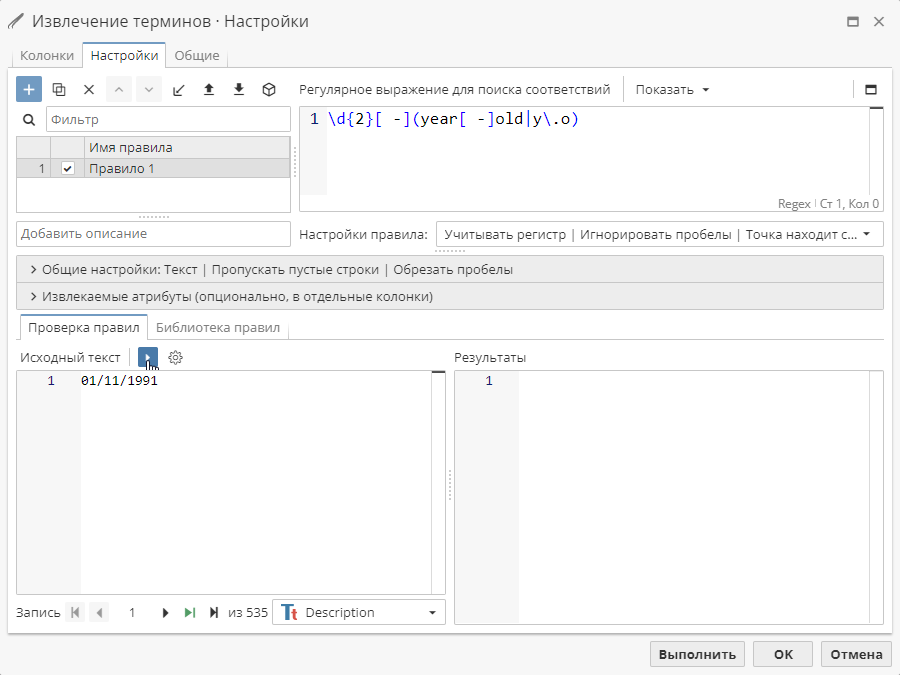
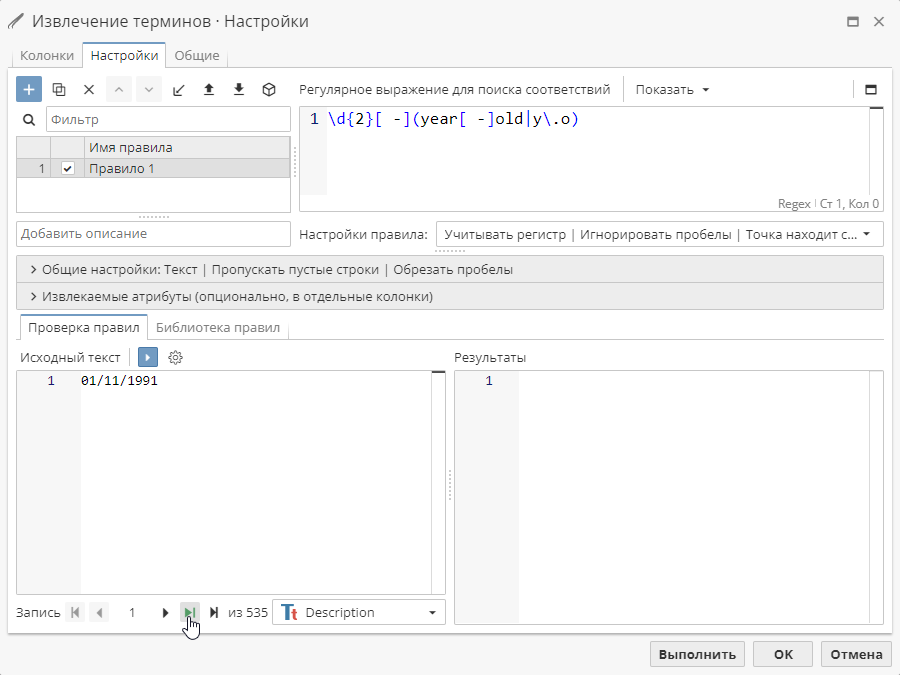
Если для текущей записи не были найдены соответствия, нажмите на кнопку с изображением зеленой стрелки на панели навигации для перехода к следующей записи, содержащей соответствие.
Также вы можете использовать выпадающее меню для переключения между исходными колонками.
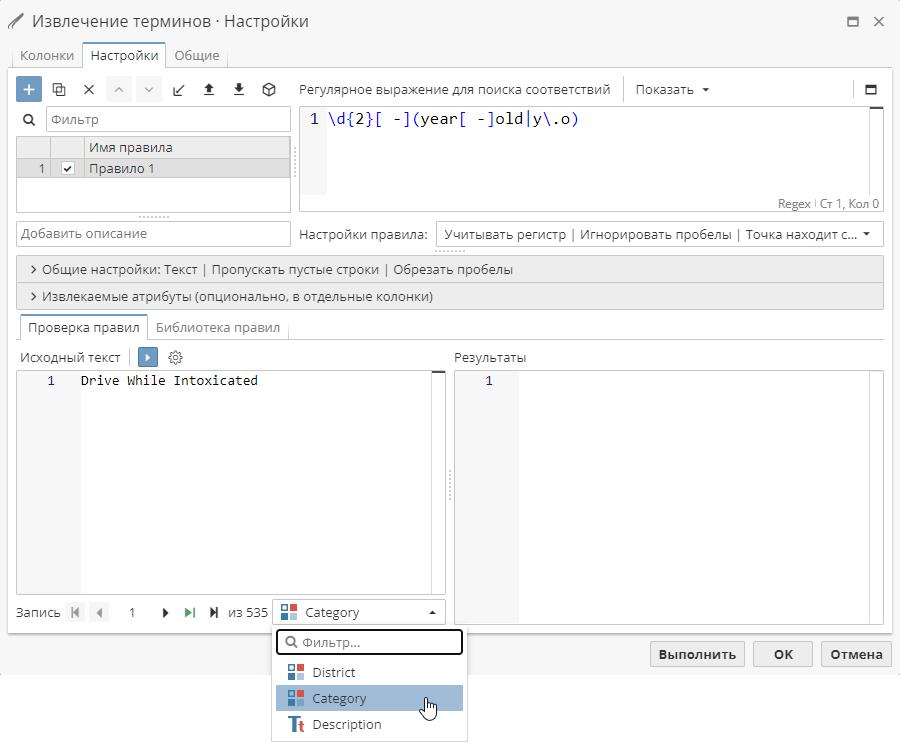
Помимо использования колонок родительской таблицы данных в качестве источника вы можете вручную добавить новое значение в поле Исходный текст и проверить работу правил.
| Когда выполняется проверка правил, исходные тексты и результаты не сохраняются при нажатии на кнопку ОК или Выполнить. |
Если правила синтаксиса регулярных выражений нарушены, появится сообщение об ошибке. Если проверка правил прошла успешно, вы можете выполнить узел.
Использование библиотеки правил
Вкладка Библиотека правил используется в качестве источника справочного материала при настройке правил.
В зависимости от выбранной коллекции вам будут доступны либо примеры правил, либо примеры синтаксиса регулярных выражений:
Нажмите дважды на выражение в коллекции для того, чтобы использовать его в вашем проекте.
Для получения более подробной информации об использовании библиотеки правил перейдите в раздел настройки узла Замена терминов.