Пример использования узла Замена терминов
Ниже приведен типичный пример соединения с источником данных:
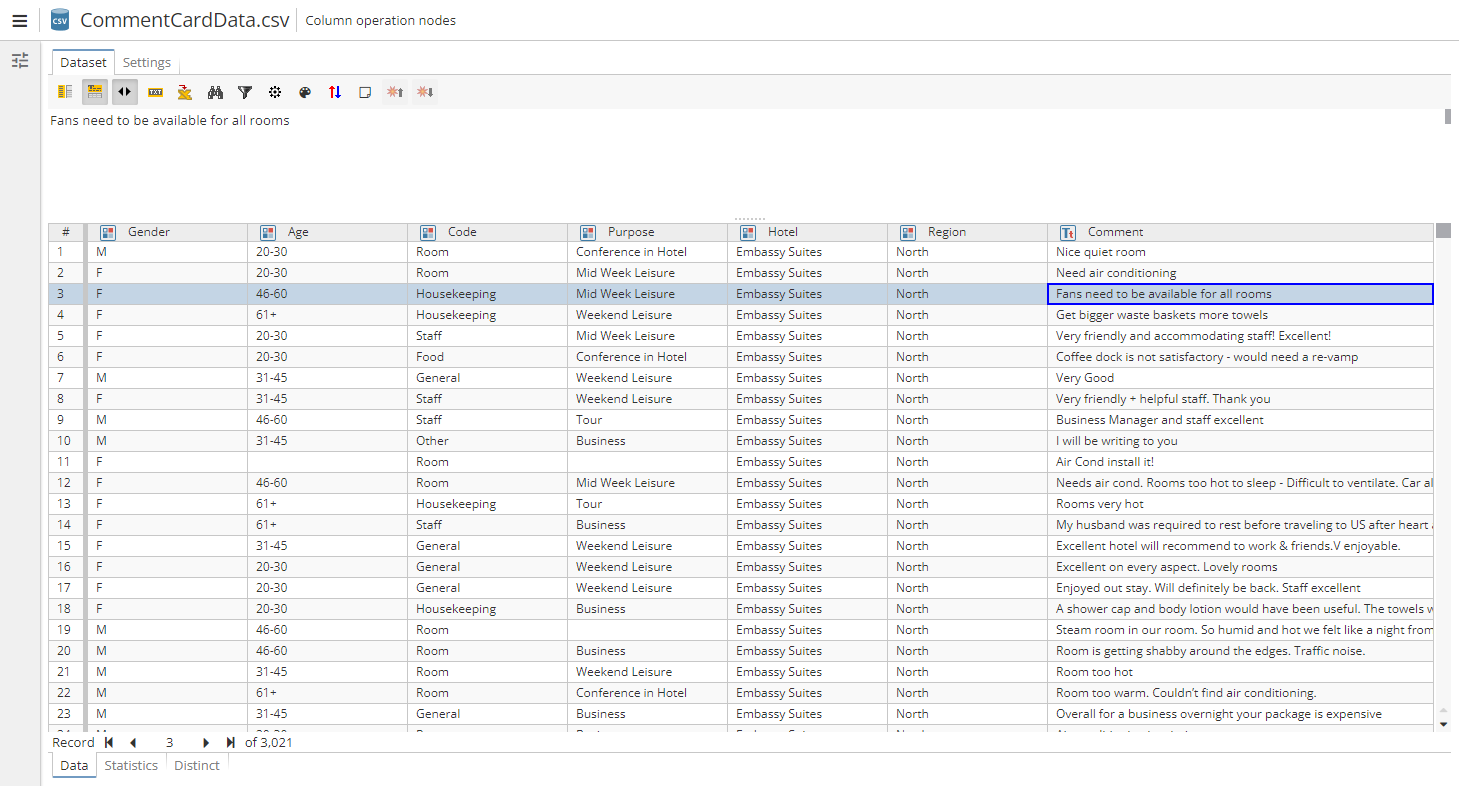
В этом примере таблица данных состоит из трех колонок, две из которых содержит информацию о поле и возрасте комментаторов, третья – текст. Эта таблица может быть использована в данном случае, поскольку она содержит как минимум одну текстовую колонку, с которой может работать узел Замена терминов. После соединения, настройки и выполнения узла Замена терминов его выходные данные будут выглядеть следующим образом:
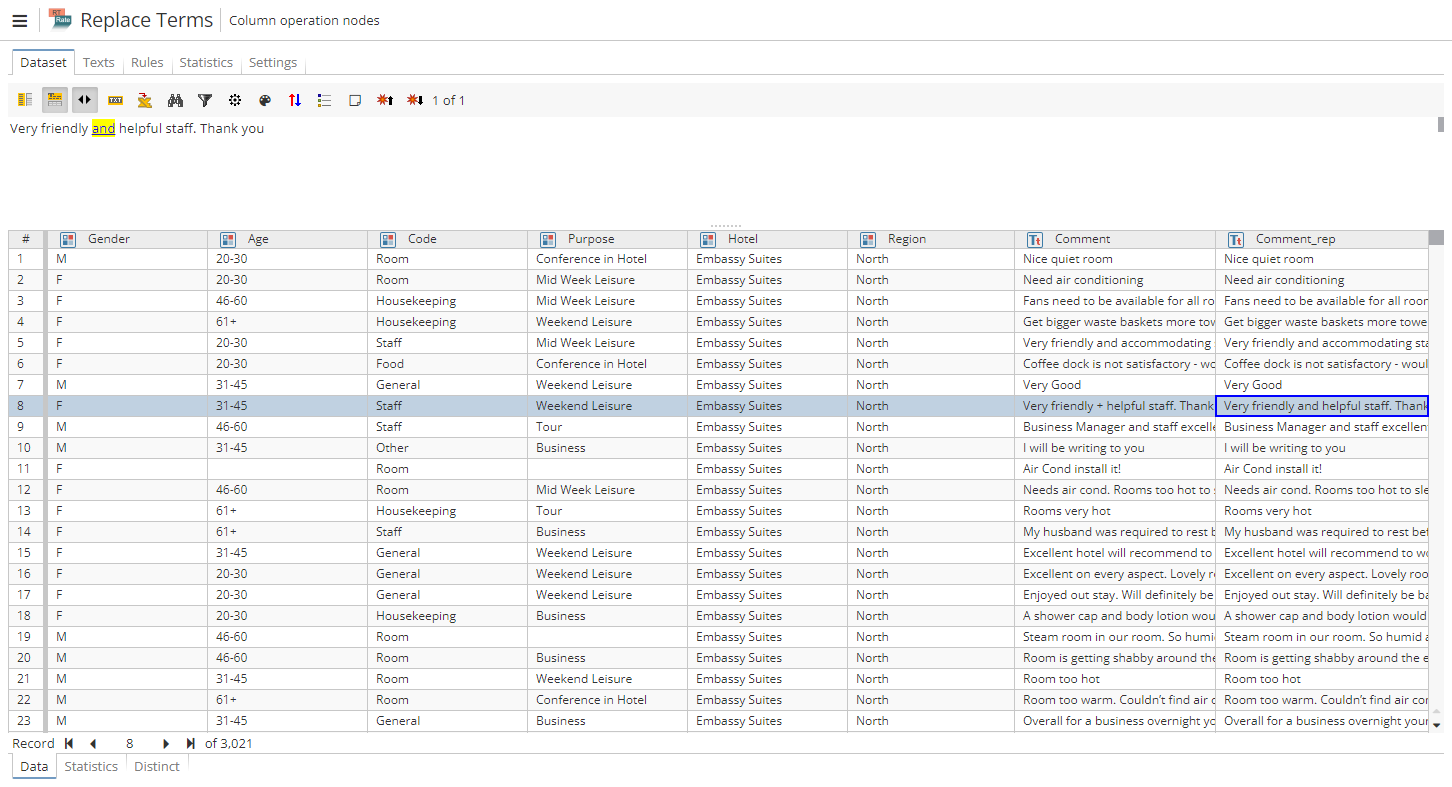
Таблица выходных данных выглядит почти так же, как и исходная таблица, но теперь она содержит дополнительную колонку с именем Comment_rep, которая содержит результаты замен, выполненных во время выполнения узла.
На скрипте узел Замена терминов обычно расположен после узла, импортировавшего данные, и узлов, которые готовят данные. За узлом Замена терминов в цепочке обычно следуют аналитические узлы. На следующем рисунке приведен пример проекта, в котором узел Замена терминов используется для подготовки данных для последующего анализа.
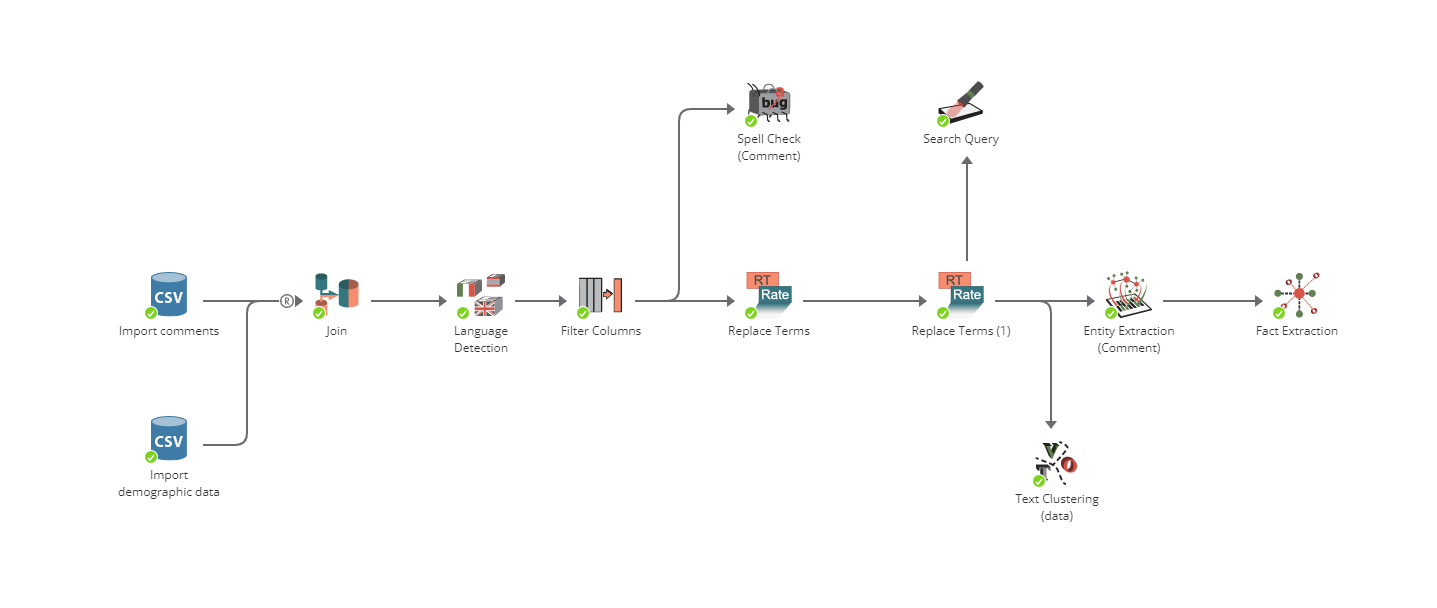
В этом примере первые несколько узлов импортируют данные с комментариями в проект PolyAnalyst. Таблица с комментариями объединяется с таблицей, содержащей демографические данные для того, чтобы впоследствии можно было исследовать возможные корреляции между данными двух таблиц.
Как видно на скриншоте, мы используем два узла Замена терминов. Первый ищет в комментариях упоминания различных сокращений и аббревиатур и заменяет их соответствующими полными формами. Например, узел находит сокращения "IBM" или "I.B.M." и заменяет их на "International Business Machines". Затем измененный текст поступает во второй узел Замена терминов, где исправляются орфографические ошибки.
Наконец, этот измененный текст поступает в несколько узлов текстовой обработки, которые выполняют статистический анализ и создают отчеты, раскрывающие важную информацию, содержащуюся в измененных комментариях.