Шаг 9: Построение модели топливной экономичности с помощью линейной регрессии
Теперь, когда мы провели подготовительную работу и уже имеем общее представление о таблице данных, мы можем перейти к решению более сложной и конкретной задачи. Например, мы можем выполнить регрессионный анализ данных, который иногда называют прогностическим моделированием. Регрессионный анализ позволяет выявлять взаимосвязь целевой (зависимой) переменной и одной или нескольких независимых переменных. В данном случае мы будем использовать колонку Mpg (Миль на галлон топлива) в качестве целевой переменной, т.к. мы хотим понять факторы, повышающие топливную экономичность автомобиля.
Колонка Mpg подходит для регрессионного анализа, т.к. она содержит непрерывную переменную. Если бы целевая колонка была дихотомической или номинативной (то есть содержала бы категориальные данные (имена), например, страна-производитель), то можно было бы использовать логистическую регрессию или другой алгоритм классификации. Таким образом, прежде, чем приступить к анализу, вы должны определить, является ли ваша целевая колонка дискретной или непрерывной, т.к. от этого зависит, какой алгоритм вы будете использовать.
В системе PolyAnalyst существует несколько алгоритмов регрессионного анализа, например, Линейная регрессия и Многовариантные адаптивные регрессионные сплайны, или MARS. Линейная регрессия – быстрая линейная модель, которая легко поддается интерпретации. Преимущество узла MARS состоит в том, что он позволяет создавать сложные нелинейные модели, однако они могут плохо себя вести при выходе за диапазон данных, использованных при обучении: в связи с тем, что при построении модели создаются кривые высокого порядка, результат модели может быть непредсказуемым.
Мы можем испытать каждый из этих алгоритмов, чтобы выявить, какие факторы влияют на топливную экономичность каждого автомобиля. Полученная модель позволит нам разработать модель нового автомобиля с повышенной топливной экономичностью двигателя.
Начнем с Линейной регрессии, т.к. этот алгоритм несколько проще узла MARS. Линейная регрессия - довольно популярный алгоритм, который с небольшими вариациями доступен практически во всех пакетах статистического ПО. Сложность подобного анализа заключается в том, что мы имеем дело с несколькими независимыми переменными. Ввиду того, что человеческий глаз в состоянии различить максимум 3 измерения на изображении, нам сложно мысленно начертить прямую линию ближе к самому большому количеству точек в n-мерном пространстве. Мы могли бы просмотреть каждый слой этого пространства по отдельности, одно измерение за один раз, по сравнению с единственной переменной Mpg, но это не так просто, т.к. при этом мы чрезмерно упростим истинную природу зависимости Mpg от других факторов. В рамках одного анализа мы измеряем зависимость Mpg от набора значений, а не от одного значения.
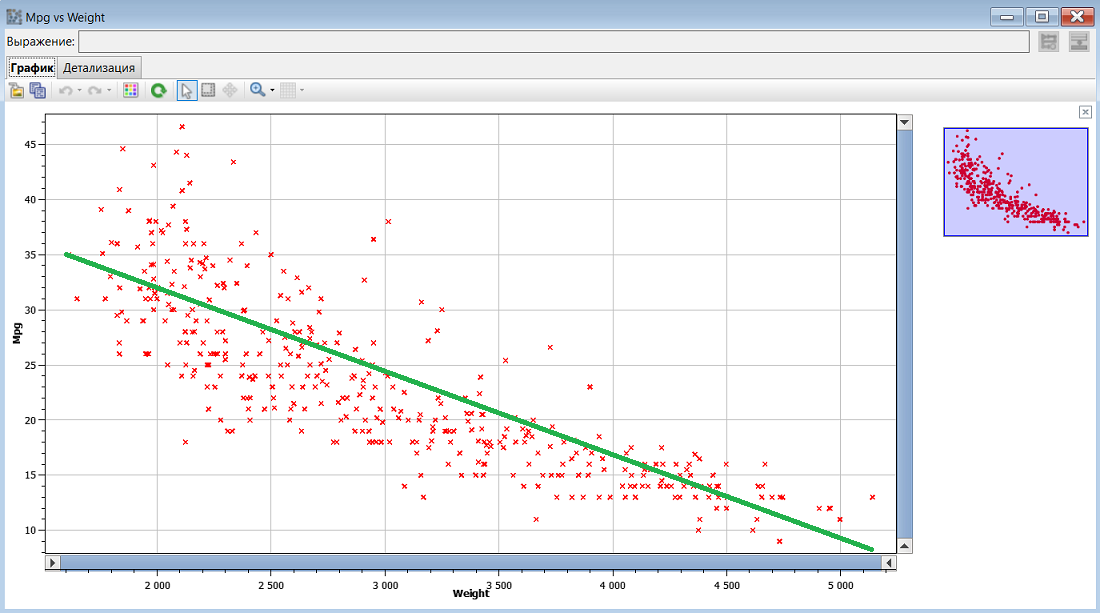
Проще говоря, алгоритм линейной регрессии пытается нарисовать прямую линию в этом n-мерном пространстве. Давайте представим, что мы работаем только с весом автомобиля и Mpg. Создайте узел Диаграмма рассеяния для колонок Weight и Mpg. Расположите данные о расходе топлива на оси Y, а вес - на оси Х (в статистике принято располагать зависимую переменную на оси Y). Выполните узел и посмотрите на получившийся график рассеяния (это двумерный график рассеяния, т.к. мы работаем с двумя измерениями). Попробуйте мысленно представить, как лучше провести ПРЯМУЮ, которая бы была ближе к наибольшему количеству точек на графике. На рисунке ниже показана прямая, которую мы начертили при помощи графического редактора на скриншоте графика.
На следующем рисунке представлена линия, которая проведена с учетом принципа "максимальной близости к наибольшему количеству точек". Здесь мы высчитываем расстояние от точки касания на линии до каждой точки. Эти расстояния называются остатками или ошибками. На рисунке ниже вы видите несколько примеров таких остатков. На самом деле, до каждой из этих точек можно провести линию.
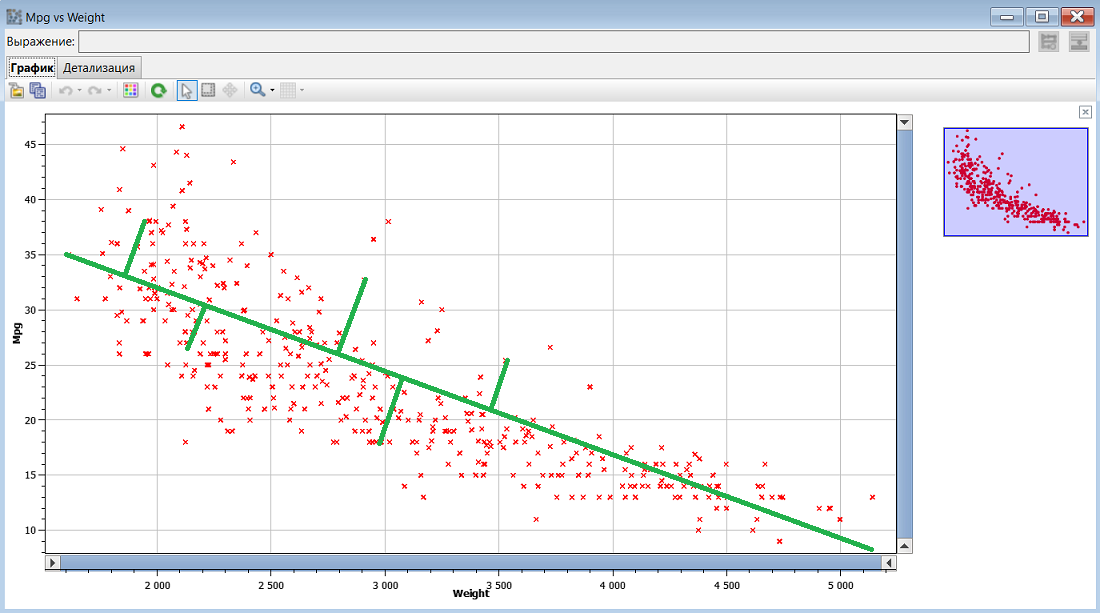
Отдельные расстояния возводятся в квадрат, чтобы удалить отрицательные значения, а затем высчитывается общее возведенное в квадрат расстояние. Цель линейной регрессии - минимизировать это расстояние (т.е. нарисовать линию как можно ближе к большему количеству точек на диаграмме рассеяния). Именно поэтому простая форма линейной регрессии часто называется Линейной средней квадратической регрессией или Методом наименьших квадратов, поскольку алгоритм пытается создать линию регрессии (зеленая линия на рисунках выше), которая имеет наименьшее общее квадратичное расстояние до всех точек. Чтобы понять, как минимизируется расстояние от линии до точек, попробуйте представить, как оно измениться при изменении наклона или длины линии. График выше имеет только два измерения и отображает лишь один независимый атрибут (вес). Наша таблица с данными об автомобилях содержит несколько независимых переменных, поэтому мы будем использовать разновидность линейной регрессии, которая работает в n-мерном пространстве, для нескольких измерений одновременно. Такую линейную регрессию называют многомерной.
Обратите внимание на то, что связь между значениями колонок Mpg и Weight является по сути нелинейной. Это говорит о том, что линейная регрессия не является идеальным инструментом моделирования такой связи, она применяется в отношении линейных связей (т.е. алгоритм предназначен для рисования ТОЛЬКО прямых линий, а не кривых). В данном случае кривая линия подойдет больше.
Добавьте на скрипт новый узел Линейная регрессия и соедините его с узлом Фильтрация колонок (мы назвали этот узел "Удаление неиспользуемых колонок"). Ваш скрипт может выглядеть следующим образом. Узел Диаграмма рассеяния, который вы также видите на рисунке, был использован для создания некоторых графиков для примеров, описанных ранее. Он нам больше не понадобится.
Помните, что расположение узлов на скрипте никак не влияет на логику аналитического процесса. Оно зависит лишь от предпочтений пользователя. Ваш скрипт вовсе не должен выглядеть в точности так, как представленный выше скрипт. Узлы могут быть расположены абсолютно по-другому, результат от этого не изменится. Обычно узлы на скрипте располагаются слева направо, наподобие слов в предложении: это позволяет наглядно представить порядок выполняемых операций.
Откройте настройки узла Линейная регрессия. Выберите Mpg в качестве целевой колонки. Чтобы сделать это, выберите Mpg в списке доступных колонок, расположенном в левой части диалогового окна (щелкните левой кнопкой мыши по колонке, чтобы выбрать ее), затем нажмите кнопку >, расположенную слева. После нажатия на эту кнопку, колонка будет перемещена из списка в поле Целевые колонки.
Вы уже знаете, что существуют лишь несколько ключевых атрибутов, которые необходимо учитывать при моделировании Mpg. Однако мы будем использовать все имеющиеся в таблице атрибуты в качестве независимых колонок, и позволим алгоритму линейной регрессии выбрать, какие колонки включить в нашу модель. Алгоритм линейной регрессии в PolyAnalyst может сделать такой выбор самостоятельно. Чтобы выбрать оставшиеся в таблице атрибуты в качестве независимых колонок, нажмите на кнопку >> в центре диалогового окна, которая перемещает все колонки из списка доступных колонок в список независимых. Ваше диалоговое окно будет выглядеть примерно так:
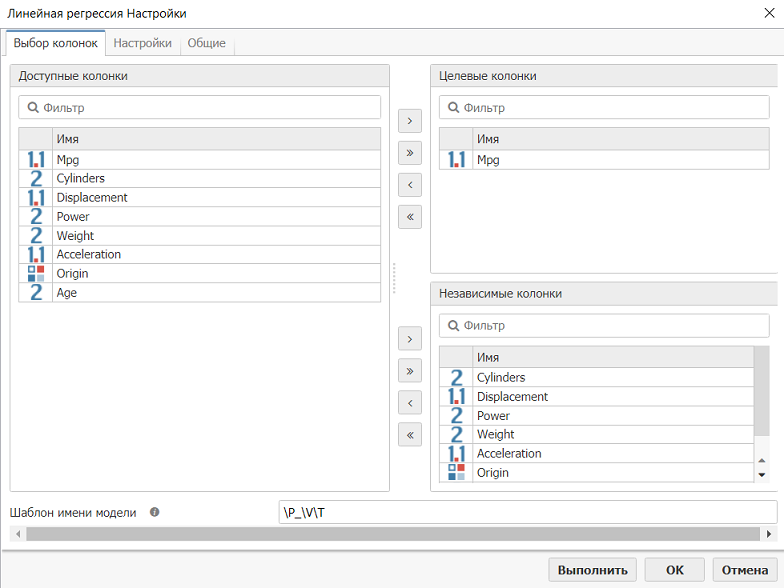
Вкладка выбора колонок узла Линейная регрессия несколько отличается от других узлов тем, что при перемещении колонок из списка доступных атрибутов в список целевых или независимых колонок, выбранные колонки по-прежнему отображаются в списке слева. Пусть вас не смущает то, что после выбора колонки Mpg в качестве целевого атрибута, она по-прежнему будет отображаться в списке доступных, и при нажатии на кнопку >> вместе с другими будет перемещена в список независимых колонок: при считывании списка независимых колонок узел ее просто игнорирует, поскольку она была ранее выбрана в качестве целевой колонки.
Если ваше диалоговое окно не отображает доступных колонок, это связано с тем, что PolyAnalyst не смог извлечь эту информацию из предшествующего узла. Это может произойти по ряду причин, но чаще всего - потому, что родительский узел был неправильно настроен или еще не выполнен. Вам необходимо сначала закрыть диалоговое окно, настроить предшествующий узел и выполнить его. Затем вернитесь к окну настроек узла Линейная регрессия. Список доступных колонок должен отображать все колонки исходной таблицы данных. Список может быть пустым также и потому, что вы забыли соединить узлы, поэтому PolyAnalyst не знает, какие колонки отображать в этом списке. Для того, чтобы настроить узел Линейная регрессия, необходимо прежде соединить его с другим узлом, который генерирует таблицу данных.
Если вы допустили ошибку при указании ролей колонок, вы можете использовать кнопки отмены действий < или <<, чтобы переместить колонки из списка независимых колонок в список доступных. Текстовое поле Фильтр в верхней левой части окна позволяет выполнять поиск нужной колонки в списке доступных колонок, что весьма удобно при работе с таблицами, содержащими сотни колонок. Списки доступных и независимых колонок могут быть отсортированы по типу или названию колонки в возрастающем или убывающем порядке. Для этого необходимо щелкнуть по заголовкам колонок "Тип" или "Название" над каждым списком. Вы также можете использовать клавиши CTRL и SHIFT, чтобы выбрать несколько колонок.
Откройте вкладку Настройки, которая позволяет настроить параметры работы алгоритма. Работа с данной вкладкой подробно описана в разделе Настройка узла Линейная регрессия. В рамках данного руководства ограничимся краткой информацией.
F-отношение есть отношение "сигнал-шум" для каждого терма в регрессии. Если данный коэффициент для отдельного терма ниже указанного нами порога, этот терм исключается из модели. Вы можете в порядке эксперимента установить значение F-отношения, равное 5 (вместо 3 по умолчанию), и посмотреть, как при этом изменится модель. Увеличение этого порога увеличивает ограничения для термов (атрибутов/колонок/измерений), которые не позволяют им войти в модель. Полученная модель будет основана только на наиболее важных термах. Обратите внимание на то, что для того, чтобы поле Минимальное F-отношение стало редактируемым, необходимо отключить опцию Использовать скорректированный критерий Фишера.
Мы не будем изменять настройки, заданные по умолчанию:
На вкладке Общие введите имя узла "Линейная регрессия Mpg".
Выполните узел. Во время выполнения узла в нижней части окна отобразится индикатор выполнения задачи по обучению модели линейной регрессии. По завершении задачи откройте окно просмотра результатов узла. Оно содержит несколько вкладок, каждая из которых отображает информацию о модели и самом узле. Первая вкладка Модель содержит модель линейной регрессии, как показано на рисунке ниже.
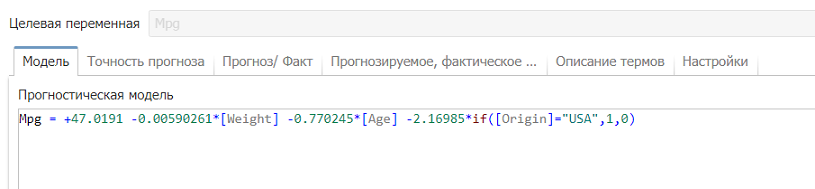
Модель - это линейная формула, которая позволяет приблизительно определить искомую зависимость (в данном случае - зависимость Mpg автомобиля от таких его характеристик, как вес, мощность, ускорение, страна-производитель, возраст и др.). Отрицательные знаки в формуле показывают, что при увеличении независимых атрибутов значение Mpg уменьшается. Положительные коэффициенты, наоборот, указывают на повышение Mpg. На предыдущем скриншоте видно, что для записей, где колонка Origin содержит значение USA (оператор IF позволяет получить значение 1), единица умножается на коэффициент -2,16985. Это значит, что у автомобилей, произведенных в США, значение Mpg сокращается приблизительно на 2,2.
Вкладка Точность прогноза отображает некоторые характеристики модели, которые позволяют нам судить о ее точности. R-квадрат равен 1. Это сумма возведенных в квадрат расстояний (о ней говорилось выше). Чем ближе значение R-квадрата к 1, тем меньше ошибка и тем точнее модель. Значение R-квадрата нашей модели равно 0,82, что является показателем достаточно высокой точности модели. Мы также можем проверить точность, сравнив прогнозируемое значение Mpg с известным значением Mpg из исходной таблицы на вкладке Прогноз/Факт. На этой вкладке, чем ближе находятся точки к идеальной диагональной линии от нижнего левого до верхнего правого угла графика, тем точнее модель. Чем больше разброс точек данных на графике от этой линии, тем ниже точность модели. Вкладка Прогноз, факт и номер записи позволяет соотнести прогнозируемые, реальные значения Mpg и номера записей.
Вкладка Описание термов содержит информацию о различных независимых переменных, отобранных алгоритмом для конечной модели.
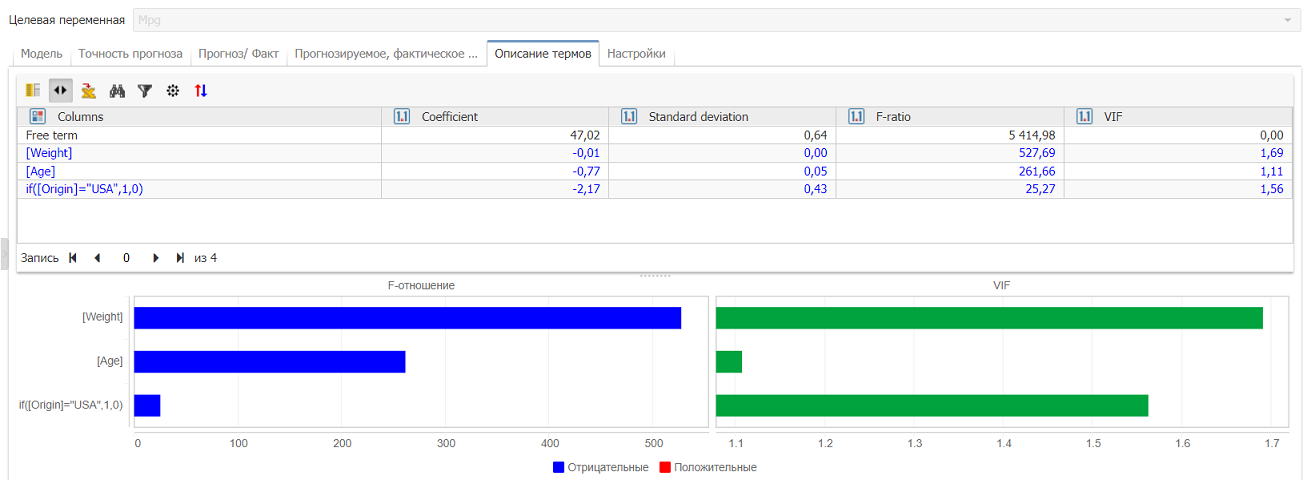
Обратите внимание, что не все независимые переменные вошли в модель. Например, наша модель не учитывает влияние количества цилиндров. В таблице термов в верхней части вкладки также указана информация о коэффициентах изменения целевой переменной в зависимости от отдельных параметров, F-отношение и стандартное отклонение для каждого терма.
Под таблицей вес (или значимость) термов обозначен с помощью цветных горизонтальных столбиков. Синий цвет означает, что при увеличении значения термов значения в целевой колонке сокращаются. Красный цвет обозначает увеличение значений в целевой колонке в зависимости от терма. Например, судя по описанию термов на рисунке выше, можно сказать, что атрибуты Weight и Age имеют отрицательные коэффициенты. Это значит, что чем тяжелее и старше автомобиль, тем ниже его топливная экономичность. Атрибут Weight также имеет отрицательный коэффициент, что означает, что при увеличении веса, Mpg также сокращается. Кроме того, алгоритм линейной регрессии обнаружил другую важную закономерность: автомобили, произведенные в США (записи, в которых колонка Origin содержит значение USA), неэффективно расходуют топливо. Поэтому терм Origin также обозначен синим цветом.
Вся эта информация позволяет нам сделать вывод о том, что для того, чтобы повысить топливную экономичность новых машин, необходимо обеспечить их легковесность. Кроме того, они должны по возможности копировать технические характеристики европейских и японских машин.
Поздравляем! Вы завершили изучение данного руководства. Теперь вы умеете добавлять, перемещать, соединять, настраивать, выполнять узлы и просматривать их результаты. Также, надеемся, что вы теперь имеете общее представление о том, как использовать PolyAnalyst для обработки и глубокого анализа данных. Не забудьте сохранить ваш проект для того, чтобы к нему можно было вернуться.