Настройка узла Извлечение ключевых слов
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Окно настроек узла Извлечение ключевых слов имеет следующие вкладки: Колонки, Настройки, Словари и Общие.
На вкладке Колонки укажите исходные текстовые колонки, которые хотите проанализировать. Вкладка Настройки используется для обозначения условий исследования, например, ограничение типов искомых слов. На вкладке Словари выберите словари, которые будут использоваться для анализа. Вкладка Общие в основном используется для изменения имени и описания узла. Как правило, настройка узла выполняется слева направо, начиная с первой вкладки.
Выбор исходной колонки
На первой вкладке выберите одну или несколько колонок в списке Доступные колонки слева, затем либо нажмите на соответствующую кнопку в виде стрелки, либо перетащите выделенные колонки в поле Выбранные текстовые колонки справа:
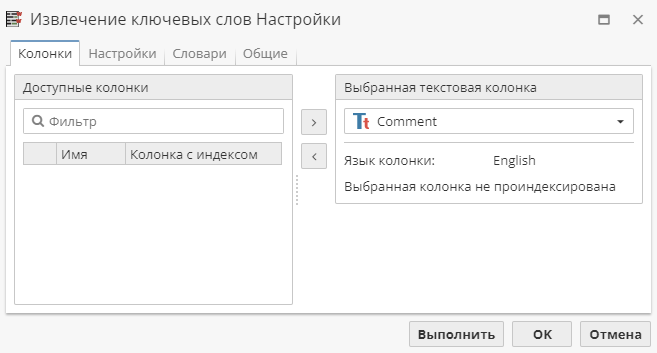
Данное поле является обязательным для выполнения узла. Подробная информация о выборе колонок доступна в соответствующем разделе.
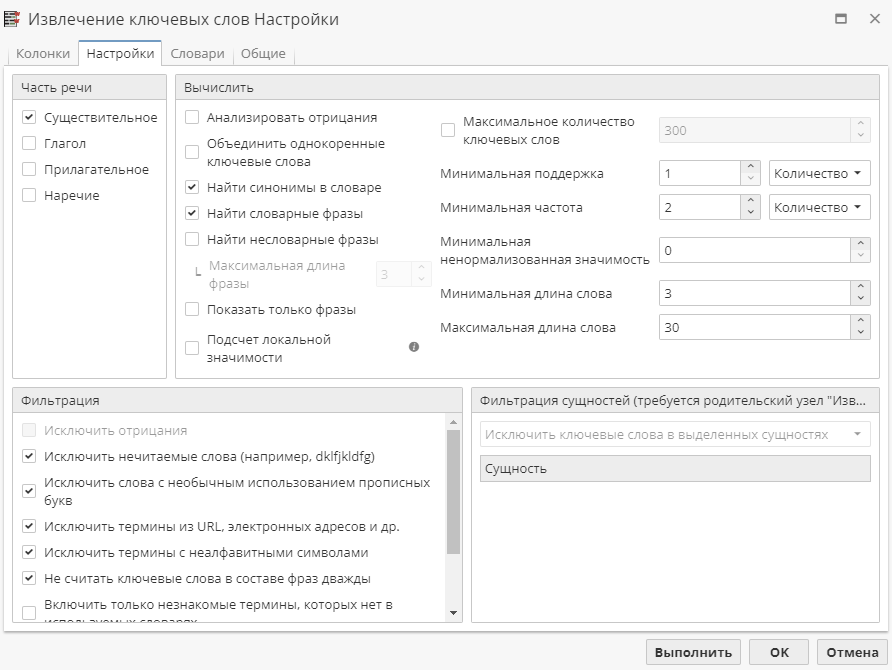
Основные параметры работы узла задаются на вкладке Настройки. Она разделена на четыре раздела:
Выбор частей речи
В ходе выполнения узел Извлечение ключевых слов определяет часть речи каждого слова. Слово может относится к нескольким частям речи в зависимости от контекста.
В разделе Часть речи выберите те части речи, которые вы хотите увидеть в результатах, отметив галочкой соответствующие флажки.
Анализ отрицаний
Узел Извлечение ключевых слов может искать отрицательные фразы, например, did not like X, и отображать их в отчете как отдельные ключевые фразы, что может быть полезно, например, когда вы хотите разграничить использование слов like и did not like.
Чтобы найти отрицания, отметьте галочкой опцию Анализировать отрицания в разделе Вычислить. При этом в разделе Фильтрация для настройки станет доступна опция Исключить отрицания. Включите ее, чтобы исключить фразы с отрицаниями из отчета узла.
Анализ отрицаний может значительно увеличить время работы узла Извлечение ключевых слов. В целях увеличения производительности узла рекомендуется отключать данную опцию.
Объединение однокоренных слов
Отметьте галочкой опцию Объединить однокоренные ключевые слова для того, чтобы слова с одинаковым корнем объединялись.
Например, если опция Объединить однокоренные ключевые слова отключена, то отчет будет выглядеть следующим образом:
Если опция Объединить однокоренные ключевые слова включена, то результаты отчета будут другими:
Таким образом, слова friend и friendliness объединяются и дают одно ключевое слово в отчете.
Поиск синонимов
Чтобы узел Извлечение ключевых слов выполнял поиск синонимов слов и фраз в используемых словарях, отметьте галочкой опцию Найти синонимы в словаре. Слова будут сгруппированы по главному слову или фразе каждой группы синонимов. Поиск выполняется по одному или нескольким словарям синонимов. Если вы хотите добавить пользовательские словари, вы можете использовать имеющийся редактор словарей (см. раздел по редактированию словарей). Обратите внимание на то, что после редактирования словаря необходимо перевыполнить узел для вступления изменений в силу.
Поиск фраз
Чтобы узел Извлечение ключевых слов определил, являются ли цепочки слов в ваших данных устойчивыми словосочетаниями, зарегистрированными в используемых словарях фраз, в разделе Вычислить отметьте галочкой опцию Найти словарные фразы. Как и в случае с синонимами, пользователи могут редактировать собственные словари фраз (путем добавления, удаления или изменения существующих фраз), после чего необходимо перевыполнить узел, чтобы эти изменения вступили в силу.
Включите опцию Найти несловарные фразы, чтобы узел Извлечение ключевых слов обнаружил потенциальные устойчивые словосочетания, которые не зафиксированы в используемом фразовом словаре. Данный алгоритм – собственная разработка компании Мегапьютер. Алгоритм ищет слова, которые часто используются вместе, и сравнивает их с ситуациями, в которых слова не появляются вместе, после чего принимается статистическое решение о том, что некоторые совместно используемые слова, возможно, являются частью фразы при превышении определенного порога.
Следует отметить, что алгоритм нахождения фраз может обнаруживать фразы, включающие до 10 слов. Это достаточно трудоемкий процесс, который может значительно снизить производительность узла. По умолчанию алгоритм ограничивается исследованием цепочек до трех слов, пока вы не измените настройки. Вы можете задать максимальное количество слов, используя опцию Максимальная длина фразы. Это число должно быть целым в интервале от 2 до 10 (включительно). Уменьшение этого числа с 3 до 2 значительно увеличит производительность узла, но алгоритм не сможет находить фразы, состоящие из трех слов. Однако следует отметить, что более длинные фразы в ваших данных, скорее всего, встречаются реже. Можно попробовать выполнить узел несколько раз, используя разные значения длины фразы, или поэкспериментировать с копиями узла, используя разные настройки.
Если вы не хотите исследовать фразы, то рекомендуется отключить данные опции для значительного повышения производительности узла Извлечение ключевых слов.
Если вы хотите исследовать фразы, а не отдельные слова, отметьте галочкой опцию Показать только фразы в нижней части раздела Вычислить.
Расчет локальной значимости
По умолчанию узел Извлечение ключевых слов определяет только общую значимость ключевых слов для всего набора данных. Отметьте галочкой опцию Подсчет локальной значимости для включения в отчет дополнительных статистических данных. Подробное описание значимости доступно в соответствующем разделе.
Включение данной опции может повлиять на общее время выполнения узла.
Фильтрация слов и фраз по частоте и другим метрикам
Вы можете исключить некоторые слова и фразы из результатов с помощью опций, расположенных в правой части раздела Вычислить.
Для каждого слова PolyAnalyst рассчитывает число записей, содержащих это слово. По умолчанию верхнего предела для этого показателя нет. Однако иногда слово, которое появляется в большинстве записей в данных, дает не так много сведений, например, предложение об авторских правах, которое появляется на каждой странице веб-сайта, или слова вроде "С уважением" в таблице с электронными письмами. Количество записей, содержащих слово, называется поддержкой слова.
Для ограничения максимальной поддержки отметьте галочкой опцию Максимальное количество ключевых слов и введите числовое значение в поле справа. По умолчанию оно равно 300 (применяется только после включения опции с помощью соответствующего флажка).
Минимальная поддержка – это минимальное количество записей, содержащих слово. По умолчанию это значение равно 1. Если слово не появляется в ваших данных хотя бы в одной записи, то оно не будет включено в отчет узла. Увеличение этого числа сократит количество найденных слов и исключит те редкие слова, которые появляются только в нескольких записях. Вы можете также указать это значение в процентах, выбрав соответствующую единицу измерения в выпадающем меню справа. В этом случае нужно использовать значение от 1 до 100. PolyAnalyst определит общее количество записей в исходной таблице данных, после чего применит заданное вами процентное значение для формирования порога фильтрации слов.
Вы также можете установить фильтрацию ключевых слов по частоте. По умолчанию Минимальная частота равна 2. Это значит, что слово должно появиться в ваших данных как минимум два раза, чтобы войти в отчет. Чтобы отобразить все слова независимо от частоты их использования, используйте значение 1. Увеличьте значение, чтобы сократить число редко используемых терминов в отчете. Частоту терминов вы также можете указать в процентах (где в качестве числителя будет выступать частота слова, а в качестве знаменателя – общее количество слов в таблице данных, включая повторения).
Еще одним способом выступает фильтрация слов по значимости. Значимость – внутренняя метрика PolyAnalyst, означающая важность слова. Увеличьте значимость, чтобы отфильтровать менее значимые слова. По умолчанию значение равно 0, что означает, что изначально мера значимости позволяет включить в отчет все слова. Для получения дополнительной информации свяжитесь со службой технической поддержки компании Мегапьютер. Значимость каждого слова или фразы появится в таблице слов и фраз в отчете.
Наконец, вы можете задать Минимальную длину слова, чтобы ограничить слова в результатах по количеству символов в них. По умолчанию значение равно 3, т.е. в отчет будут включены только те слова, которые состоят из 3 или более символов. Уменьшите это значение до 1, чтобы включить такие слова, как, например, артикль "a". Увеличьте это значение, чтобы сосредоточиться на длинных словах. Таким же образом вы можете задать Максимальную длину слов (по умолчанию значение равно 30).
Фильтрация нечитаемых слов
В разделе Фильтрация включите опцию Исключить нечитаемые слова, чтобы исключить из отчета слова или фразы, которые PolyAnalyst посчитает "мусором". Решение о том, являются ли термины "сорными", принимает автоматический алгоритм, который работает по аналогии с узлом Проверка орфографии при выявлении неправильно написанных терминов. Примерами сорных терминов являются: vroblf, htsad, lpzsml, и др.
Алгоритм проверяет каждое слово на наличие максимально допустимых в конкретном языке групп гласных и согласных букв. Алгоритм ищет известные триграммы из согласных. Если триграмма превышает заданный порог, то слово помечается как "сорное".
Данный алгоритм не имеет настраиваемых параметров. Если вы хотите иметь больше возможностей работы со словами анализируемого текста, попробуйте использовать узел Проверка орфографии для выявления орфографических ошибок, а затем использовать узел Замена терминов для изменения или удаления данных слов.
Исключение слов некорректного регистра
Чтобы отфильтровать слова, содержащие необычно или неуместно использованные символы верхнего регистра, включите опцию Исключить термины с необычным использованием прописных букв.
Обратите внимание на то, что символы следующих языков трактуются как символы в нижнем регистре: арабский, китайский, японский, корейский и тайский.
Исключение терминов из URL, электронных писем и др.
Если опция Исключить термины из URL, электронных адресов и др. включена, эвристический алгоритм пытается распознать "необычные" фрагменты текста, которые входят в состав таких сущностей, как имена файлов, URL-адреса, адреса электронной почты, или просто странные сочетания символов, например, /PRNewswire-FirstCall/). Это позволяет исключить такие текстовые фрагменты из отчета узла.
Обратите внимание на то, что в данном контексте термин "сущности" не связан с элементами, изучаемыми узлом Извлечение сущностей.
Исключение терминов с неалфавитными символами
Чтобы исключить такие слова, как, например, Mega123, включите опцию Исключить термины с неалфавитными символами.
Обратите внимание на то, что для азиатских языков (например, арабского, китайского, японского, корейского и тайского) данная опция исключает неиероглифические символы.
Подсчет ключевых слов в фразах
При включенной опции Не считать ключевые слова в составе фраз дважды ключевые слова, которые являются частью фраз, не будут учитываться отдельно.
Ограничение результатов известными/неизвестными словарными терминами
Включите опцию Включать только знакомые термины, которые имеются в используемых словарях, чтобы те слова, которые не присутствуют хотя бы в одном из рабочих словарей класса WordList, исключались. Данная опция полезна в том случае, когда вы хотите исследовать статистику точного ряда терминов, настроенного заранее. При включении вспомогательной опции Имеются во всех используемых словарях WordClass в отчет будут включены только те ключевые слова, которые числятся в словарях группы WordClasses.
В качестве альтернативы вы можете отметить галочкой опцию Включать только незнакомые термины, которых нет в используемых словарях, чтобы добавить в отчет только новые термины.
Фильтрация результатов по сущностям
Если узлу Извлечение ключевых слов предшествует узел Извлечение сущностей, который извлек сущности из той же текстовой колонки, вы можете фильтровать результаты узла Извлечение ключевых слов по сущностям. Данная опция будет неактивна, если извлечение сущностей не было выполнено перед извлечением ключевых слов.
Выберите в выпадающем меню один из двух режимов фильтрации:
-
Исключить ключевые слова в выделенных сущностях;
-
Включить ключевые слова только в выделенных сущностях.
Для каждого из режимов вы можете выбрать типы сущностей для фильтрации слов. Сущности, не отмеченные галочкой, будут проигнорированы при фильтрации.
Например, если вы хотите изучить статистику использования имен людей в тексте, вы можете настроить узел Извлечение сущностей, извлечь с его помощью сущности класса People, добавить узел Извлечение ключевых слов, выбрать режим Включить ключевые слова только в выделенных сущностях в выпадающем меню, отметить галочкой флажок для сущностей класса People и выполнить узел Извлечение ключевых слов. Результат узла в таком случае будет содержать только те ключевые слова, которые входят в сущности класса People, извлеченные предшествующим узлом.
Фильтрация стоп-слов
Для отфильтровывания стоп-слов отметьте галочкой один или несколько словарей стоп-слов (StopLists) на вкладке Словари. Чтобы не фильтровать стоп-слова, оставьте соответствующие флажки словарей пустыми. При необходимости вы можете отредактировать соответствующий словарь.
Исключение стоп-слов помогает сократить количество обнаруженных терминов, поскольку иногда список может быть чересчур большим.
| При редактировании словаря стоп-слов (или любого другого используемого узлом словаря) уже после выполнения узла Извлечение ключевых слов, вам придется перевыполнить узел для применения внесенных изменений. |
Настройка связанных словарей
Настройка словарей осуществляется на одноименной вкладке, которая имеется в окне настроек большинства узлов текстового анализа:
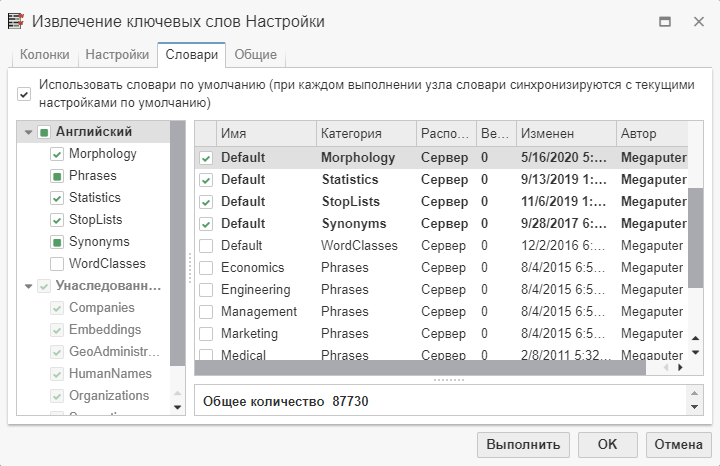
По умолчанию PolyAnalyst предварительно выбирает несколько словарей. Вы можете изменить словари, которые будут использоваться в анализе. Это может значительно повлиять на результаты узла.
Можно указать сразу несколько словарей. Для выбора словаря отметьте галочкой флажок рядом с именем нужного словаря.
Вот несколько важных правил, о которых следует помнить:
-
Выбор фразового словаря, отличного от того, что используется по умолчанию, повлияет на результаты поиска фраз.
-
Выбор других словарей сущностей влияет на то, какие сущности будут отображены в отчете узла.
-
Выбор другого словаря стоп-слов влияет на то, какие термины будут исключены из отчета узла.
-
Если выбраны сразу нескольких словарей стоп-слов, то слово, которое имеется в каком-либо из них, будет удалено из отчета узла.
Вы также можете отключить все статистические словари во время настройки узла; статистика в этом случае будет получена на основе самих данных, т.е. значимость ключевых слов будет определяться на основе анализируемых текстов – слова будут считаться значимыми в том случае, если они имеют неравномерное распределение по всему набору данных, или, другими словами, присутствуют только в части текстов.
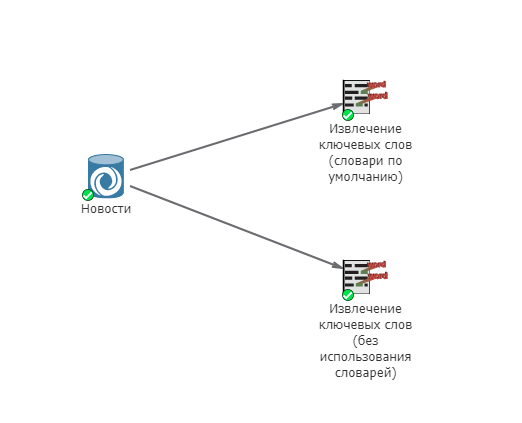
Проиллюстрируем данное утверждение. В качестве исходных данных используем новостные тексты. Импортируем данные через узел JSON и соединим их с двумя узлами Извлечение ключевых слов, как показано на скриншоте ниже:
Сравним результаты выполнения: слева представлены результаты выполнения узла Использование ключевых слов с настройками по умолчанию (с использованием словарей), справа – с отключенными словарями.
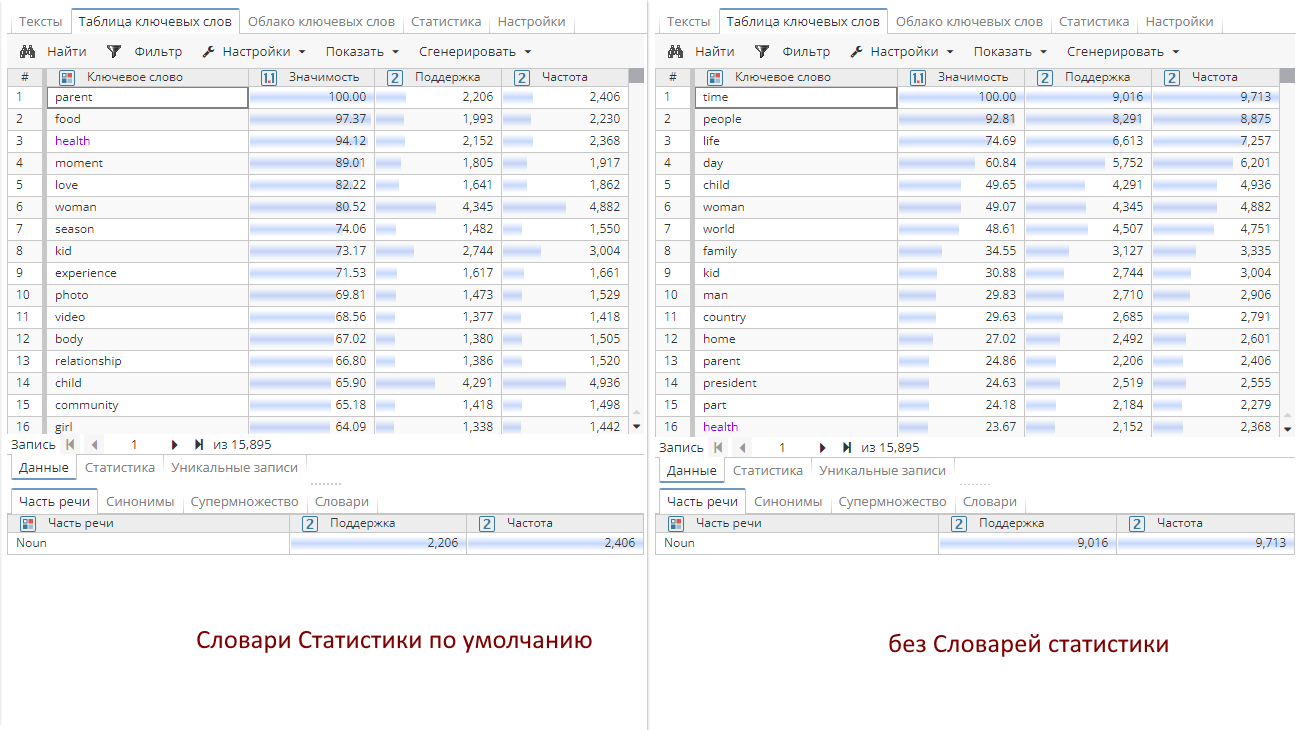
Полезность отключения словарей вызывает сомнения, поскольку интереснее узнать, насколько конкретная таблица отличается от нормы в целом, а не то, насколько конкретный подмассив записей отличается от нормы собственной таблицы.
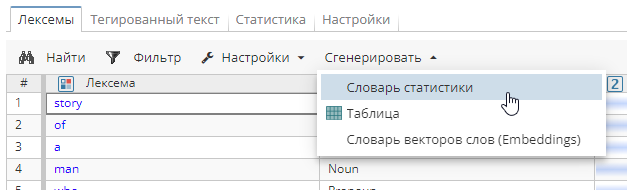
Создание собственного словаря статистики
Вы также можете создать собственный словарь статистики через узел Индекс. Для этого откройте окно отображения узла и выберите опцию Сгенерировать. В выпадающем меню выберите вариант Словарь статистики и дождитесь создания словаря.
В качестве еще одного примера возьмем два набора данных, а именно 50000 различных рецензий по фильмам, скачанных с сайта IMDb – крупнейшей базы данных о кинематографе. Данные разбиты на две одинаковые части: по 25000 записей. Одну часть записей мы будем использовать для создания словаря, другую – используем для извлечения ключевых слов.
Укажем в качестве словаря сгенерированный словарь. Сравним результаты узлов: слева представлены результаты выполнения узла Извлечение ключевых слов с настройками по умолчанию (с использованием словаря статистики по умолчанию), справа – с использованием сгенерированного словаря.
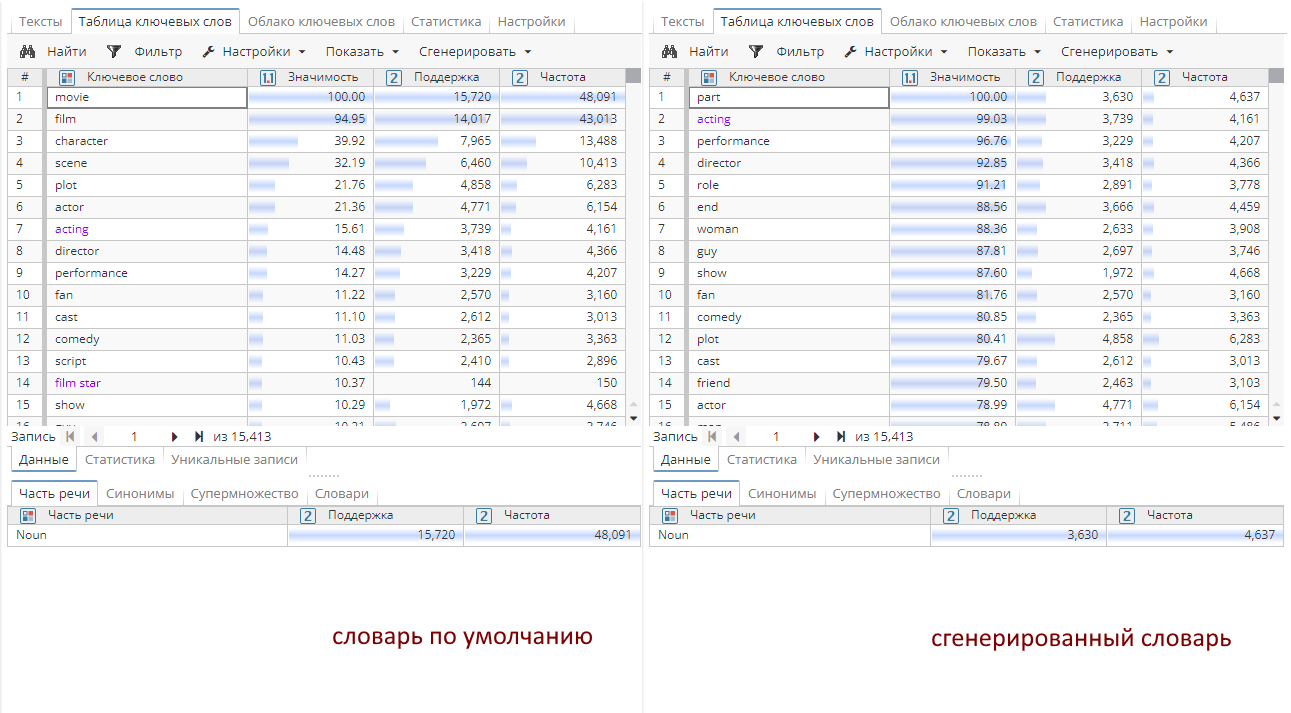
Как вы можете наблюдать на скриншоте выше представленные ключевые слова различаются: так, например, такие слова, как "movie", "film", "character" и т.д. определенно будут ключевыми в контексте тематики анализируемого набора данных (рецензии по фильмам) относительно общего количества слов, представленных в корпусе английского языка.
Ключевые слова, извлеченные из нашего набора данных на основе сгенерированного словаря, будут значимыми только на наборе слов по выбранной тематике: такие слова, как "part", "performace", "director" являются ключевыми только для выбранного контекста без взаимосвязи с языковым корпусом.
Мы также можем использовать сгенерированный словарь в качестве словаря для других подобных наборов данных, например, для еще одного набора рецензии, взятых с другого сайта.
Вы можете посмотреть сгенерированный словарь в Менеджере словарей. Не забудьте поменять язык, нажав на иконку иероглифа для поиска нужного словаря.
Пользовательская настройка статистики ключевых слов
| Данная функциональная возможность не поддерживается в текущей версии PolyAnalyst и описывается здесь исключительно для клиентов, использующих более ранние версии продукта. |
-
Импортируйте текстовые данные, которые необходимо проанализировать, в проект.
-
Добавьте и выполните узел Извлечение ключевых слов, используя стандартные настройки.
-
В окне просмотра результатов узла Извлечение ключевых слов выберите опцию Статистика в меню Сгенерировать в верхней части вкладки Таблица ключевых слов.
-
Дождитесь, пока PolyAnalyst создаст новый статистический словарь.
-
При необходимости можно открыть каталог словарей и убедиться, что новый статистический словарь появился в списке. Чтобы увидеть доступные словари, выберите Управление словарями… в меню Файл Аналитического клиента PolyAnalyst (для нативного клиента). Новый словарь появится в категории Statistics.
-
Создайте новый узел Извлечение ключевых слов. Настройте узел так, чтобы он использовал пользовательский словарь статистики вместо словаря по умолчанию, установленного PolyAnalyst.
Убедитесь в том, что используемые для обучения данные были предварительно "очищены", т.е. содержат минимальное количество каких-либо орфографических ошибок или текстовых неточностей. В противном случае созданный статистический словарь будет бесполезным, а узел Извлечение ключевых слов не даст нужных результатов.