Настройка узла Применение таксономии
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Окно настроек узла Применение таксономии обычно включает три вкладки: Настройки, Независимые колонки и Общие. Если узел Применение таксономии соединен с другим источником данных, который отличается от того, что использует узел Таксономия или Автоматическая таксономия, для настройки также будет доступна вкладка Распределение целевых колонок.
Опции вкладки Настройки
Количество доступных опций на данной вкладке зависит от способа применения таксономии, выбранного в соответствующем меню:
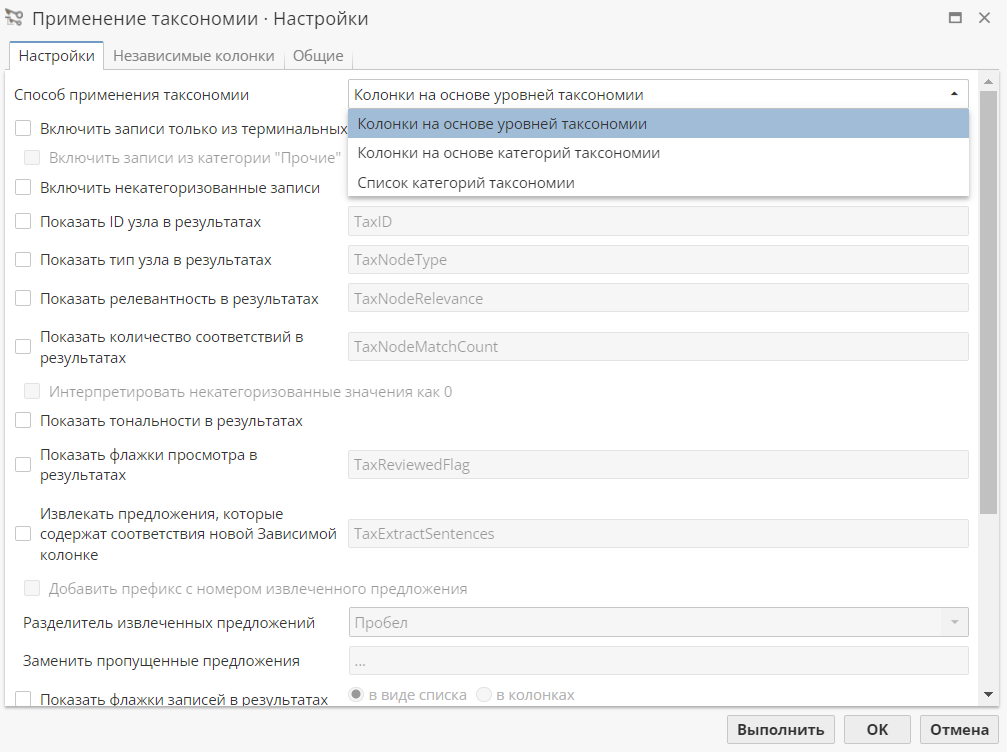
Способ применения таксономии контролирует процесс и конечный вид выходной таблицы данных:
-
Колонки на основе уровней таксономии – узел создает колонку для каждого уровня таксономии. Данный режим, как правило, используется для таксономий, основанных на одной целевой колонке, и когда вы хотите, чтобы каждая исходная запись попала только в одну наиболее подходящую категорию. Другим примером могут выступать таксономии, где конкретному текстовому значению каждой записи соответствует только одна категория;
-
Колонки на основе категорий таксономии – узел создает булевую колонку для каждой категории таксономии с указанием включения конкретной записи в данную категорию. Данный режим полезен тогда, когда одна запись соответствуют сразу нескольким категориям, и вы хотите исключить повторение в таблице. Результирующая таблица данных хорошо подходит для использования в качестве исходных данных для таких аналитических алгоритмов, как, например, Анализ связей (применяется для поиска связей между различными категориями);
-
Список категорий таксономии – узел создает для каждой записи одну текстовую колонку с именами категорий таксономии (обозначая полный путь), которые отделены друг от друга разделителем. Выберите данный режим, если хотите использовать результирующую таблицу только в качестве конечного отчета, поскольку текстовая колонка со списком значений – не самый лучший объект для проведения последующей обработки.
Поле Совпадающие категории таксономии доступно только в режиме Список категорий таксономии и используется для указания имени результирующей колонки.
Опция Включать только записи из терминальных узлов доступна в режиме Колонки на основе уровней таксономии. Термин узлы в данном разделе означает категории таксономии (не следует путать с узлами системы PolyAnalyst, которые добавляются на скрипте).
Термин терминальный относится к категориям таксономии самого нижнего уровня. Как уже говорилось ранее, таксономию можно представить в виде дерева, у которого есть корень (корневой узел), ствол (узлы первого уровня), ветви (узлы второго и последующих уровней) и листья (конечные, или терминальные узлы, не имеющие дочерних категорий).
От использования данной опции зависит объем записей, которые попадут в выходные данные узла Применение таксономии. Если эта опция отключена, то входные записи, соответствующие категориям всех уровней, будут появляться в выходных данных несколько раз. Если эта опция включена, то в выходной таблице появятся только соответствия терминальным категориям. Иными словами, исходные записи, соответствующие всем другим категориям, кроме терминальных, исключаются (т.е. "отфильтровываются") из выходных данных.
Включите эту опцию, если вы хотите найти записи, соответствующие терминальным категориям, и отфильтровать те, которые соответствуют другим категориям.
Если при этом существует необходимость включить в результаты узла не только записи из терминальных категорий, но и те записи, которые попадают в категорию Прочие, отметьте галочкой опцию Включить записи из категории "Прочие".
Опция Включить некатегоризованные записи позволяет настроить узел на включение в выходную таблицу записей, которые не входят ни в одну из категорий таксономии. Подобные записи группируются в узел Прочие корневого узла таксономии. Если опция Включить некатегоризованные записи отмечена галочкой, записи общей категории Прочие будут добавлены в выходную таблицу. Обратите внимание на то, что данная опция не распространяется на кластеры Прочие родительских категорий, т.к. для записей этой группы было найдено соответствие вышестоящему уровню таксономии.
Опция Показать ID узла в результатах используется для добавления в отчет колонки с идентификаторами узлов. Данную колонку можно использовать для разграничения категорий таксономии. Если данная опция включена, вы можете задать имя результирующей колонки в соответствующем поле.
Если опция Показать тип узла в результатах включена, то PolyAnalyst создаст новую колонку (имя колонки можно изменить в соответствующем поле) в выходной таблице с кодом режима классификации, который использует категория. Например, если исходная запись соответствует категории, которая настроена на использование режима C – Любое соответствие в таксономии, то значение C появится в новой колонке для данной записи.
Данная опция полезна тогда, когда выходная таблица используется для создания отчета, например, для того, чтобы объяснить, почему конкретная запись соответствует только одной или нескольким категориям. Эта опция применяется также в случае, если вы планируете дальнейшую работу с выходной таблицей. Например, можно использовать узел Фильтрация строк, чтобы удалить из таблицы все записи, в которых новая колонка содержит какое-то конкретное значение.
Когда запись попадает в одну из категорий таксономии, узел определяет релевантность этой записи. Отметьте галочкой опцию Показать релевантность в результатах для добавления в отчет новой колонки (при необходимости, имя можно настроить), которая содержит значение релевантности исходной записи одной или нескольким категориям. Значение релевантности здесь идентично тому, что отображается в колонке Relevance на вкладке Детализация в окне просмотра результатов узла Таксономия или Автоматическая таксономия.
| Данная опция может быть использована только в том случае, когда в настройках родительского узла на вкладке Параметры включена опция Определять релевантность. |
Отметьте галочкой опцию Показать количество соответствий в результатах для того, чтобы узел Применение таксономии сгенерировал колонку с информацией о том, сколько раз в конкретной записи встречаются шаблоны из поискового запроса.
Вспомогательная опция Интерпретировать некатегоризованные значения как 0 доступна только в режиме Колонки на основе категорий таксономии. При ее включении записи без соответствий получают значение 0. В противном случае соответствующие ячейки будут пустыми.
| Данная опция может быть использована только в том случае, когда в настройках родительского узла на вкладке Параметры включена опция Определять количество соответствий. |
Опция Показать тональности в результатах доступна только в режиме Колонки на основе уровней таксономии и при включении генерирует четыре дополнительные колонки с метриками тональности (Positive, Negative, Neutral и Integral), в которых отображена степень положительной, отрицательной, нейтральной и общей тональности каждого текстового значения, соответствующего PDL-запросу конкретной категории таксономии. При необходимости вы можете изменить имена результирующих колонок в соответствующих полях.
Значения данных метрик здесь идентичны тем, что отображаются в одноименных колонках на вкладке Детализация окна просмотра результатов родительского узла с таксономией.
| Данная опция может быть использована только в том случае, когда включена опция Определять тональность на вкладке Параметры в настройках родительского узла Таксономия или Автоматическая таксономия, который, в свою очередь, должен наследовать данные узла Анализ тональности. |
Подробнее об этом – см. соответствующий параграф раздела Просмотр таксономий.
Узел Таксономия можно использовать как корректирующий инструмент благодаря возможности ручной категоризации записей. Такое применение узла подробно описано в соответствующем разделе. Такой подход предполагает валидацию результатов категоризации записей вручную с последующим проставлением отметки о том, что запись была просмотрена пользователем. По умолчанию все записи считаются не прошедшими пользовательскую оценку. Включите опцию Показать флажки просмотра в результатах, если хотите, чтобы в выходную таблицу узла Применение таксономии была добавлена новая колонка с данными булевого типа.
При оценке таксономии каждой записи также можно присвоить одну или несколько пользовательских меток. Включите опцию Показать флажки записей в результатах, чтобы узел Применение таксономии добавил колонку с пользовательскими метками в выходную таблицу. Используйте опцию в виде списка, чтобы добавить список, разделенный запятыми. Используйте опцию в колонках, чтобы создать новую колонку для каждого флажка.
| Опции Показать флажки просмотра в результатах и Показать флажки записей в результатах могут быть использованы только в том случае, когда в настройках родительского узла, генерирующего таксономию, выбрана колонка-ключ. |
Если вы хотите, чтобы узел Применение таксономии добавил в отчет колонку с предложениями, в которых было найдено соответствие, отметьте галочкой опцию Извлекать предложения, которые содержат соответствия новой Зависимой колонке. Для определения позиции извлеченного предложения дополнительно включите опцию Добавить префикс с номером извлеченного предложения. При необходимости выберите способ разделения извлеченных предложений (пробел, новая строка, табуляция) и укажите способ замены пропущенного предложения (по умолчанию троеточие).
При включенной опции Добавить колонку с информацией о положении соответствий PolyAnalyst создаст новую текстовую колонку в выходном массиве данных, которая будет содержать позиции совпадений с шаблоном: Документ;Предложение;Позиция;Длина. Результат опции может быть использован, например, в узле Извлечение терминов с простым регулярным выражением для извлечения документов, предложений, позиций и длин в отдельные колонки.
Опции Разделитель в списке категорий и Разделитель пути к категории доступны только в режиме Список категорий таксономии. Выберите необходимый тип в выпадающем меню, либо введите новое значение в соответствующем поле.
Каждая категория в иерархии таксономии принадлежит определенному уровню. Уровень представляет глубину категории в иерархии. Например, корневая категория имеет глубину 0. Дочерние категории корневой категории находятся на глубине 1 (уровень 1), потомки дочерних категорий – на уровне 2 и так далее.
По умолчанию узел Применение таксономии включает в отчет все соответствия между исходными записями и категориями на любом уровне иерархии.
Опция Начать с уровня используется для определения нового минимального порога с целью отфильтровывания записей, соответствующих категориям более низкого уровня (ближе к корневой категории). Например, при выборе значения 2 из отчета будут исключены записи, соответствующие непосредственным потомкам корневого узла, поскольку эти категории находятся на уровне 1, что меньше, чем 2.
Опция Количество уровней устанавливает максимальный порог глубины для категорий, которые могут считаться соответствиями при определении того, должна ли запись быть включена в выходную таблицу. Грубо говоря, эта опция противоположна опции Начать с уровня. Однако в данном случае число уровней зависит от начального уровня. Например, если начальный уровень не задан (по умолчанию он равен 0), то число уровней соответствует глубине каждой категории. Например, в иерархии трех уровней число уровней будет составлять 3.
Если данная опция не настроена, то в выходные данные включаются все уровни. Однако если же число уровней задано, то исключаются любые категории, расположенные внутри иерархии на более высоком уровне (глубже и дальше от корневой категории).
Данная опция применяется тогда, когда вас интересуют не столько конкретные подкатегории, сколько промежуточные категории, т.е. ветви дерева таксономии. Опция особенно полезна в том случае, когда более глубокие категории слишком специфические, и группируя эти узлы в более крупные и более абстрактные кластеры, можно достичь более глубокого уровня понятийной абстракции, представленной в выходной таблице.
Настройка вкладки Независимые колонки
Вкладка Независимые колонки используется для выбора тех колонок исходной таблицы, которые необходимо включить в отчет узла Применение таксономии.
Настройка данной вкладки не является обязательной. Рекомендуется включать в отчет узла только те колонки, которые составляют первичный ключ для исходной таблицы.
Настройка вкладки Распределение целевых колонок
Вкладка Распределение целевых колонок – это дополнительная вкладка, которая появляется только в том случае, если узел Применение таксономии и узел Таксономия или Автоматическая таксономия подключены к разным узлам-источникам данных, как в следующем случае:
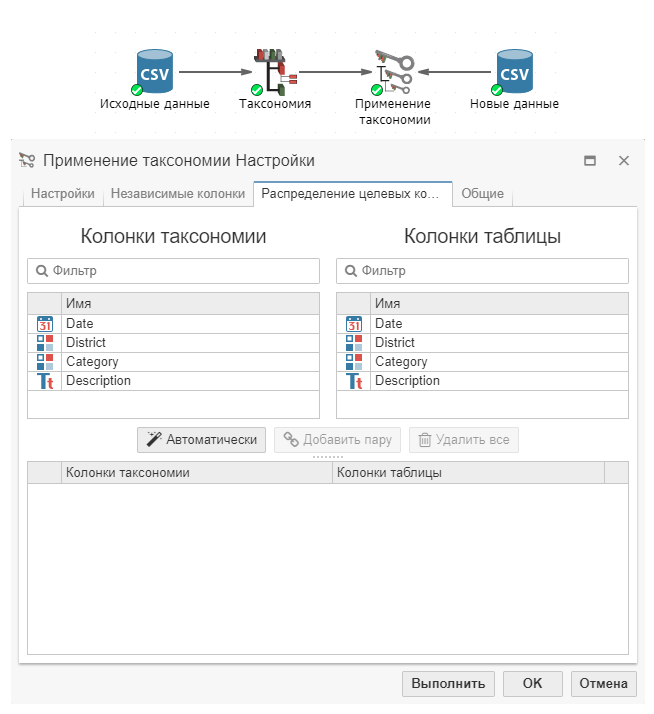
В данном примере узел Применение таксономии имеет два входящих узла. Первый узел – Таксономия, который соединен с узлом Файлы CSV для импорта исходных данных. Второй узел Файлы CSV импортирует новые данные. На вкладке Распределение целевых колонок отображаются две группы колонок из соответствующих узлов-источников данных.
Данная вкладка позволяет выполнить привязку одной или нескольких целевых колонок из таксономии и таблицы. Для создания пар можно использовать автоматический режим объединения, нажав на соответствующую кнопку. Выбранные пары колонок отобразятся в таблице ниже. Пользователь также может задать пары колонок вручную, выбрав названия соответствующих колонок в списке и нажав на кнопку Добавить пару.
Выбранные пары колонок можно удалить как по отдельности (нажав на кнопку  в крайней правой колонке таблицы), так и целой группой (с помощью кнопки Удалить все).
в крайней правой колонке таблицы), так и целой группой (с помощью кнопки Удалить все).