Создание, соединение и настройка узла Агрегирование
Узел Агрегирование требует наличия одного родительского узла, генерирующего таблицу данных, например, это может быть узел-источник данных, операция со строками или колонками. Результат работы узла – новая таблица данных, следовательно, на выходе узел может быть соединен с любым узлом, принимающим таблицу данных на входе.
Один из узлов, который обычно следует за узлом Агрегирование на скрипте, – узел Модификация колонок, который используется для переименования сгенерированных колонок и их упорядочения.
Нажмите правой кнопкой мыши на узел Агрегирование и выберите Настройки, чтобы открыть окно настроек узла. Оно содержит следующие вкладки:
-
Колонки – вкладка позволяет выбрать ключ агрегирования и колонки для агрегирования;
-
Агрегации – позволяет выполнить настройки отдельных агрегаций;
-
Общие – позволяет задать имя и ввести описание узла.
Настройка узла начинается со вкладки Колонки, и обычно выполняется слева направо. Однако пользователь может в любой момент вернуться на вкладку Колонки, изменить настройки, а затем перенастроить вкладку Агрегации. Следующие разделы содержат более подробную информацию о том, как выполнить настройку каждой вкладки.
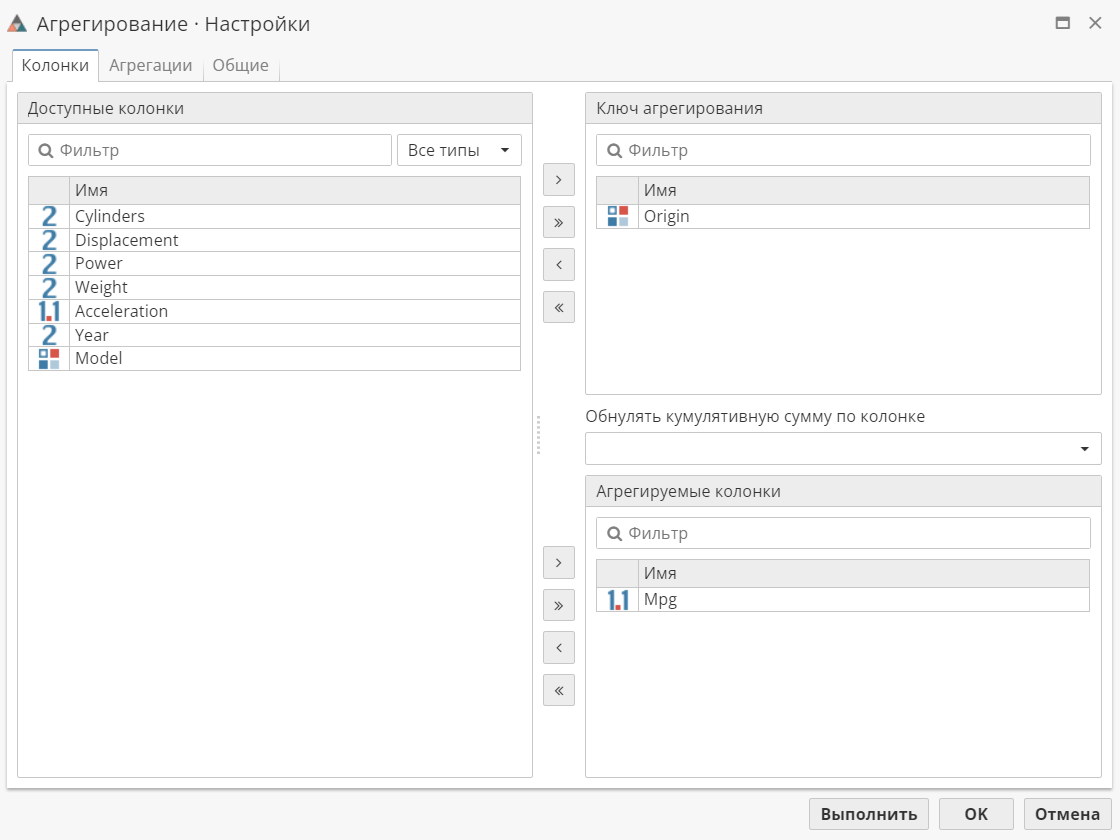
На вкладке Колонки отображены три списка колонок: Доступные колонки, Ключ агрегирования и Агрегируемые колонки. Здесь можно определить ключ агрегирования и список колонок для агрегации. Ниже представлен пример настройки узла Агрегирование с выбранными колонками.
При необходимости, обратитесь к разделу Выбор колонок во время настройки узлов, где описаны общие принципы выбора колонок в узлах PolyAnalyst.
Список ключей агрегирования
Ключ агрегирования – колонка (или несколько колонок), которая используется для сравнения записей друг с другом с тем, чтобы определить, должны ли записи быть объединены в группы. Как минимум одна колонка должна быть выбрана в качестве ключа. На представленном выше скриншоте в качестве ключа агрегирования выбрана колонка Origin.
PolyAnalyst позволяет сравнивать идентификаторы текстов, поэтому совершенно одинаковые тексты могут рассматриваться как разные.
Если какая-то колонка выбрана в качестве ключа агрегирования, ее нельзя одновременно включить и в список агрегируемых колонок.
Порядок колонок в ключе агрегирования
Если в качестве ключа агрегирования используется несколько колонок, то порядок колонок в узле Агрегирование значения не имеет. Результат сравнения по двум ключам будет одинаковым, несмотря на порядок. Изменить его можно путем удаления колонок из ключа с последующим их добавлением в нужном порядке. Он выполняет лишь структурирующую функцию, например, если вы хотите представить ключ так, чтобы его было легко понять. При указании колонок в качестве ключа агрегирования не рекомендуется учитывать порядок колонок.
Функциональные зависимости
В процессе настройки ключа агрегирования необходимо учитывать принципы проектирования базы данных; так, например, следует избегать колонок, которые функционально зависимы друг от друга. Функциональная зависимость представляет собой ограничивающее условие для двух атрибутов из двух групп атрибутов. Для любого соотношения колонок, колонка (атрибут) В функционально зависит от колонки А, если величина А однозначно определяет величину В.
В целях оптимизации скорости работы узла Агрегирование при работе с большим корпусом данных рекомендуется использовать ключ с меньшим количеством колонок, который будет работать эффективнее (еще одна причина использования только номера животного). Не следует использовать ключ агрегирования, который состоит из двух колонок, одна из которых функционально зависит от другой. Однако этим правилом можно пренебречь и добавить зависимую, избыточную колонку в ключ агрегирования для того, чтобы зависимость отразилась в выходных данных.
Опция Обнулять кумулятивную сумму по колонке позволяет выбрать колонку из ключа агрегирования, при изменении значения в которой кумулятивная сумма накапливается по выбранному атрибуту и сбрасывается, когда остальная часть ключа меняется. Если ключ не составной, то кумулятивная сумма сбрасываться не будет.
Выбор колонок для агрегирования
Список колонок для агрегирования включает те колонки, к которым будут применены разные способы агрегирования. Несколько способов агрегирования могут применяться к каждой колонке (см. подробнее в разделе о вкладке Агрегации). В примере с животными колонка Pet Age (Возраст животного) должна быть включена в список агрегируемых колонок, поскольку именно для этой колонки мы хотим вычислить среднее значение.
Пользователь может оставить список агрегируемых колонок пустым. При этом необходимость настройки вкладки Агрегации отпадает, но результатом узла все равно будет выходная таблица с уникальным ключом для каждой записи. Следует обратить внимание на то, что если список агрегируемых колонок оставить пустым, то придется подключить опцию Добавить колонку с количеством строк на вкладке Агрегации, поскольку PolyAnalyst требует, чтобы выполнялась хотя бы одна операция агрегирования для подтверждения целесообразности использования узла.
Выбрав колонку для агрегирования, пользователь не может выбрать ее в качестве ключа. Однако данную колонку всегда можно переместить назад в список доступных колонок, с тем, чтобы затем использовать его в качестве ключа. Можно также просто перетащить выбранную колонку в поле ключа агрегирования.
Теоретически, количество колонок для агрегирования одним узлом не ограничено. На практике, однако, при стандартной настройке PolyAnalyst и использовании аппаратного оборудования стандартной комплектации, рекомендуется ограничиваться 20 колонками с применением максимум 2-3 способов агрегирования на одно поле.
Агрегируемые колонки не отражаются в выходных данных
Колонка, прошедшая агрегирование, не будет отражена в результирующей таблице целиком: в ней будет отражена только одна или несколько из ее агрегированных форм. Агрегированные формы колонок настраиваются на вкладке Агрегации. Если вам нужно, чтобы какая-либо колонка была отражена в выходных данных в первоначальной форме, ее нужно включить в состав ключа, а не в список агрегируемых колонок. Для этого придется изменить настройку узла Агрегирование, поскольку его цель изменится. Возможно, в таком случае вам нужно вовсе не агрегирование данных, и узел Уникальные записи больше подойдет для решения вашей задачи.
Колонки, не подлежащие агрегированию
Иногда пользователям удается сохранить колонку в выходных данных, несмотря на то, что она не является частью ключа. Сначала они выбирают колонку, затем выбирают способ агрегирования Мода. Хотя колонка при этом будет иметь другое имя на выходе (оригинальное имя + суффикс _mode, или приставка _mode плюс имя), все ее значения останутся прежними для каждого отдельного значения ключа, а затем колонка появится на выходе фактически без изменений. Такое действие лучше, чем включение колонки в список агрегирования, если мы имеем дело с функциональной зависимостью или неэффективным сравнением типов данных; но в целом это – возможный, но не рекомендуемый алгоритм действий при настройке узла Агрегирование в анализе данных, поскольку колонка изначально не будет обладать свойствами, подлежащими агрегированию.
Настройка функций агрегации
Вкладка Агрегации – вторая вкладка в окне Настройки узла Агрегирование. Эта вкладка используется для настройки методов агрегирования, необходимых для получения агрегированных значений. Таблица на этой вкладке содержит все колонки, указанные в списке колонок агрегирования на первой вкладке (колонки из списка Агрегируемые колонки). Колонки, которые будут агрегированы, приводятся в отдельных строках вместе с опциями и дополнительной информацией. Ниже приводится пример настройки данной вкладки.
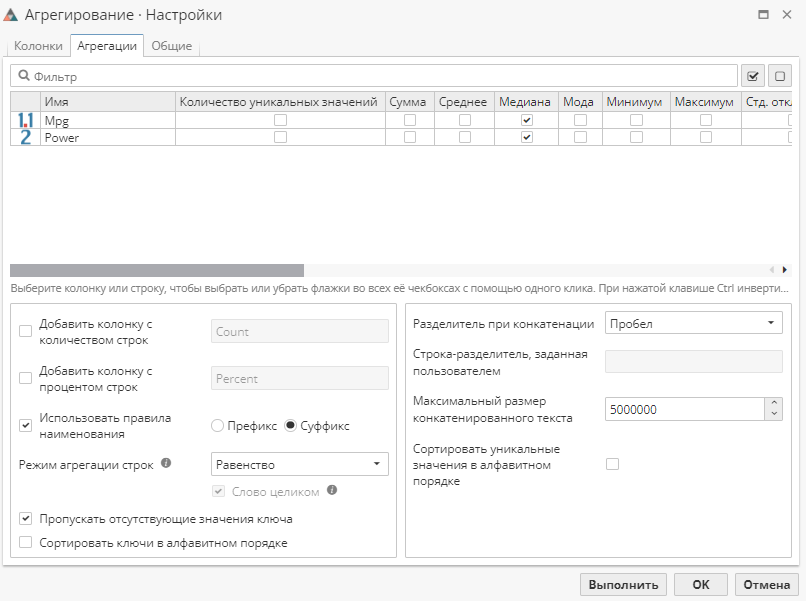
Первые две колонки таблицы отображают тип и имя исходных колонок. Они являются только ссылками на колонки исходной таблицы. В зависимости от типа колонки (обозначается соответствующей иконкой) будет доступен тот или иной набор опций, или функций агрегации (в последующих колонках таблицы).
К каждой колонке, указанной в списке агрегируемых колонок, может быть применено несколько функций агрегации. Результаты выбранных функций агрегации будут сохранены в новых колонках выходной таблицы данных узла.
Два флажка в правом верхнем углу вкладки используются для удобства и позволяют выбрать или отменить выбор всех возможных функций агрегирования. Например, вы можете с помощью одного клика отменить выбор всех включенных функций агрегирования, сбросив таким образом все предыдущие настройки, если хотите настроить вкладку заново.
| Если возникла необходимость применить разные функции агрегирования к одной и той же таблице, скопируйте узел и отключите все опции в скопированном узле. |
Выберите колонку или строку, чтобы выбрать или убрать флажки во всех ее чекбоксах с помощью одного клика. При нажатой клавише Ctrl инвертируется выбор чекбоксов для выбранной колонки или строки.
Опция Добавить колонку с количеством строк позволяет создать дополнительную колонку, в которой будет отображаться количество исходных записей, отвечающих условию колонки-ключа. По умолчанию новой колонке будет присвоено имя Count (Количество), но его можно изменить, набрав новое имя в текстовом окне рядом с опцией. В примере с животными (описанном в руководстве), отметив эту опцию, мы получили бы следующую таблицу на выходе:
Вид животного |
Средний возраст |
Количество |
Кошка |
6 |
2 |
Собака |
10 |
1 |
Слон |
15 |
1 |
Новая колонка Count будет содержать целые числа. Из данного примера видно, что в исходных данных было 2 записи, объединенных согласно ключу "кошка".
В связи с тем, что иногда приходится иметь дело с большим количеством колонок на выходе, PolyAnalyst использует автоматическую систему именования новых колонок. Позже эти имена могут быть изменены. В нижнем левом углу вкладки Агрегации выберите способ именования новых колонок (с помощью суффиксов или приставок). По умолчанию используется суффиксация, т.е. названия новых колонок содержат оригинальное имя колонки, за которым следует название способа агрегирования.
Например, если для исходной колонки Age выбрать способ агрегирования по среднему значению (Mean) и суффиксацию в качестве способа именования новых колонок, новая колонка будет называться Age_Mean. Если выбрать префиксацию, колонка будет называться Mean_Age.
Наряду с количеством строк пользователь может добавить в выходную таблицу узла колонку, в которой будет отображаться процентное отношение исходных записей, отвечающих условию колонки-ключа. Для этого отметьте галочкой опцию Добавить колонку с процентом строк.
В выпадающем меню выберите Режим агрегации строк для группировки строк по различным критериям их сходства:
-
Равенство - в этом режиме агрегируются строки, которые полностью совпадают. То есть, если две или более строки идентичны, они объединяются в одну.
-
Подстрока - этот режим подразумевает агрегацию строк, если одна из них является подстрокой другой. То есть, если в одной строке можно найти другую строку, то они будут сгруппированы вместе.
-
Префикс - в данном режиме строки агрегируются, если одна из них является префиксом (начальным отрезком) другой. Таким образом, если одна строка начинается с другой строки, они будут объединены.
-
Суффикс - данный режим предполагает, что строки агрегируются, если одна из них является суффиксом (конечным отрезком) другой. То есть, если одна строка заканчивается на другую строку, они будут объединены.
Если необходимо, чтобы подстрока совпадала с границами слов, то воспользуйтесь опцией Слово целиком. Опция включена по умолчанию и доступна для режимов: Подстрока, Префикс и Суффикс.
|
Агрегация строк имеет несколько ключевых особенностей:
|
Опция Пропускать отсутствующие значения ключа включена по умолчанию. Она дает узлу команду не отображать в выходных данных ключи агрегирования с отсутствующими значениями. Составные ключи с нулевыми значениями также не отображаются в выходной таблице. Если отключить данную опцию, строки с отсутствующими значениями будут сгруппированы на выходе в отдельную строку с нулевым ключом.
Справа расположено несколько опций настройки конкатенации. В частности, можно выбрать Разделитель при конкатенации (запятая, пробел, точка с запятой и др.), установить Максимальный размер конкатенированного текста, а так же включить опцию Сортировать уникальные значения в алфавитном порядке (если опция выключена, то уникальные значения сортируются в порядке встречаемости). Данные опции понадобятся пользователям только в случае использования таких методов агрегирования, как Конкатенация и Конкатенация уникальных значений (см. описание ниже).
Способы агрегирования
Способ агрегирования применяется к группе исходных значений и позволяет получить одно значение на выходе. Эти способы также можно назвать функциями агрегации. Доступны следующие функции агрегации:
-
Количество уникальных значений – количество уникальных значений в колонке.
-
Сумма – арифметическая сумма всех значений в колонке.
-
Среднее – среднее арифметическое всех значений в числовой колонке (отношение суммы к количеству значений).
-
Медиана – центральное значение в списке значений колонки, расположенных по возрастанию.
-
Мода – наиболее частое значение колонки.
-
Минимум – минимальное значение колонки.
-
Максимум – максимальное значение колонки.
-
Стандартное отклонение – стандартное отклонение колонки.
-
Количество значений – количество непустых (или неотсутствующих, ненулевых) значений.
-
Диапазон – интервал между максимальным и минимальным значениями колонки.
-
Объединение (ИЛИ) – для булевых колонок, рассчитывает булевое объединение всех значений.
-
Пересечение (И)– для булевых колонок, рассчитывает булевое пересечение всех значений.
-
Конкатенация – соединяет строковые значения в том порядке, в котором обрабатывались строки исходной таблицы.
-
Первое значение – первое значение в колонке при конкретном значении ключа.
-
Последнее значение – последнее значение в колонке при конкретном значении ключа.
-
Кумулятивная сумма – сумма с накоплением: к предыдущему значению прибавляется текущая ячейка и так далее.
-
Конкатенация уникальных значений – аналогична режиму Конкатенация, но в список конкатенируемых значений попадают только уникальные строки из указанной колонки.
Каждую опцию можно выбрать, поставив галочку в соответствующей ячейке, для того, чтобы добавить колонку с новым значением в выходную таблицу данных. В таблице с животными мы подключим опцию Среднее для переменной Age, для того, чтобы появилась новая колонка с указанием среднего возраста. Следует обратить внимание на то, что доступность той или иной функции агрегации зависит от типа данных в колонке. Так, например, к строковым данным применимы такие опции, как количество уникальных значений, конкатенация и мода, поэтому только эти опции будут доступны для колонок данного типа. Поскольку невозможно рассчитать среднее значение для строковой колонки, эта опция будет блокирована, флажка в колонке Среднее не будет.
Результатом агрегирования всегда является новая колонка с соответствующим именем и типом данных в выходной таблице. Например, в результате вычисления среднего значения мы получим числовую колонку на выходе. При вычислении моды для строковых данных, на выходе мы получим колонку со строковыми данными. Результатом вычисления количества уникальных значений будет колонка с целыми числами, результат булевого объединения – булевая колонка. Выходные данные конкатенации – текст. Тип выходных данных для каждой функции агрегирования описан ниже.
Количество уникальных значений
Функция Количество уникальных значений позволяет определить количество уникальных значений по заданному ключу агрегирования.
Например, в таблице с животными, у нас было два значения в колонке Age – 10 и 2 – для кошки. Количество уникальных значений для этой колонки – 2 (поскольку мы имеем два различных значения). Класс нулевых значений не входит в это количество (если бы в исходных данных были пустые строки, они были бы проигнорированы при использовании данного способа агрегирования).
Тип выходных данных при использовании этого способа агрегирования – целые числа. Слово NDiffValues будет присоединяться к имени оригинальной колонки в пре- или постпозиции.
Данная опция блокируется для текстового типа данных, поскольку текст каждой исходной записи уникален.
Сумма
Данная функция выводит среднее арифметическое для ряда чисел. Она доступна только при работе с числовыми или целочисленными значениями. Тип выходных данных – число. Нулевые исходные значения рассматриваются как 0, это означает, что они не влияют на результат. К наименованию колонки добавляется слово Sum. Исходные величины могут быть и отрицательными, они все равно суммируются, в результате чего может получиться отрицательная сумма.
Среднее
Среднее значение – это сумма значений, разделенная на количество слагаемых. Данная опция доступна только при работе с целочисленными и численными типами данных. Результатом является числовая колонка. Нулевые исходные величины рассматриваются как 0.
Медиана
Медиана представляет собой центральное значение из списка, упорядоченного по возрастанию (или, если список является равномерным, а значения представляют собой числовые данные, то медиана расположена между двумя числами в середине). Данная опция доступна только для чисел, целых чисел и дат. Результатом является числовая колонка.
Мода
Высчитывается наиболее вероятное значение колонки. Если одно или несколько значений являются одновременно наиболее вероятными, одно из них выбирается в случайном порядке (обычно это первое по порядку значение). Данная опция недоступна для текстового типа данных. На выходе можно получить строковые или числовые данные, в зависимости от исходной колонки. При данном способе агрегирования нулевые исходные величины пропускаются (даже если большинство величин являются нулевыми, мода будет вычислена из существующих значений).
Минимум
Рассчитывает минимальное значение. Опция доступна только для чисел и дат. Нулевые значения пропускаются. Тип данных на выходе определяется типом исходных данных.
Максимум
Рассчитывает максимальное значение. Опция доступна только для данных типа число, целое число и дата. Нулевые значения пропускаются. Тип данных на выходе определяется типом исходных данных.
Диапазон
Высчитывается интервал между максимальным и минимальным значениями. Опция доступна только для данных типа число, целое число и дата. Нулевые значения пропускаются. Тип данных на выходе определяется типом исходных данных.
При работе с датами выходные данные будут содержать разницу в количестве дней, при указании времени – промежуток времени с разницей в секундах.
Стандартное отклонение
Высчитывается стандартное отклонение. Опция доступна только для данных типа число, целое число и дата. Нулевые значения пропускаются. Тип данных на выходе определяется типом исходных данных.
При работе с датами выходные данные будут содержать разницу в количестве дней, при указании времени – промежуток времени с разницей в секундах.
Стандартное отклонение обычно определяется как квадратный корень из дисперсии. Стандартное отклонение измеряется в тех же единицах, что и исходные значения.
Количество значений
Функция Количество значений – счетчик непустых значений вне зависимости от уникальности значений. По сути это счетчик записей с ненулевыми значениями в данной колонке. Опция доступна для данных всех типов. Тип данных на выходе – целые числа. Нулевые значения не учитываются (это отражено в названии данного метода).
Объединение (ИЛИ)
Рассчитывается булевое (логическое) объединение всех значений. Доступно только для булевых колонок. Выходные данные имеют булевое выражение со словом ИЛИ (OR) в пре- или постпозиции.
Например, предположим, что исходная таблица (Животные) содержит колонку Vaccinated (Вакцинация). В ней выставлялось бы значение Истина, если бы животному была сделана прививка. Допустим, что нам необходимо ответить на вопрос о том, была ли животному какого-либо вида сделана прививка. Мы могли бы определить общее количество истинных/ложных значений колонки Vaccinated для каждого вида животных для того, чтобы ответить на этот вопрос. Учитывая действие данного способа, результат был бы истинным, если бы любому животному каждого вида была сделана прививка. Результат по виду животных был бы ложным, если бы не одно животное данного вида не было вакцинировано.
Можно также вычислить пересечение – другой тип булевых расчетов, для того, чтобы результат был истинным, необходимо, чтобы все значения были истинными, а не только некоторые из них, как в случае с объединением.
Нулевые значения пропускаются. Если все исходные значения по заданному ключу нулевые, выходное значение – ноль.
В данной документации имеется справочник по SRL, где можно найти руководство по булевой логике, которое поможет лучше понять принцип действия данного способа агрегирования.
Пересечение (И)
Рассчитывается булевое пересечение всех значений. Доступно только для булевых колонок. Выходные данные имеют булевое выражение со словом И (AND) в пре- или постпозиции. Нулевые значения пропускаются. Если все исходные значения по заданному ключу нулевые, выходное значение – ноль. Этот способ похож на предыдущий, но здесь необходимо, чтобы все значения были истинными для того, чтобы результат по заданному ключу был истинным.
Руководство для пользователей содержит справочник по SRL, где имеется руководство по булевой логике, которое поможет лучше понять принцип действия данного способа агрегирования.
Конкатенация
Позволяет получить текстовое значение. Опция доступна при работе со строковыми и текстовыми данными. Порядок значений зависит от порядка ключей агрегирования и порядка ввода (порядок ввода можно изменять, используя предшествующий узел Производные колонки). В связи со сложностями, возникающими в процессе агрегирования значений, нет гарантии того, что исходный порядок значений будет сохранен. Если вы хотите сохранить исходный порядок значений, не рекомендуется использовать данный метод.
При конкатенации значений всегда используется разделитель данных – символ, который находится между соединяемыми значениями. По умолчанию в качестве такого разделителя используется пробел. Пользователь может выбрать разделитель, используя выпадающее меню Разделитель при конкатенации в нижнем поле вкладки Агрегации справа. Кроме того, есть возможность задать разделитель при конкатенации в разделе Настройки узлов по умолчанию для всего проекта или для своего пользовательского профиля (Настройки проекта и Настройки пользователя, соответственно). Разделитель, выбранный в профиле пользователя, будет использоваться по умолчанию во всех новых проектах данного пользователя. Разделитель, выбранный в настройках проекта, будет использоваться по умолчанию во всех новых узлах агрегирования в данном проекте. На существующие узлы изменение настроек пользователя и проекта не повлияет.
В ходе работы узла Агрегирование один и то же разделитель будет применяться для разделения конкатенируемых значений из разных колонок.
Нулевые значения рассматриваются как пустые строки.
Первое значение
Данный способ агрегирования позволяет выявить первое значение в колонке, соответствующее значению ключа. Тип данных на выходе зависит от исходных данных.
Последнее значение
Данный способ агрегирования позволяет выявить последнее значение в колонке, соответствующее значению ключа. Тип данных в выходной колонке зависит от исходных данных.