Практическое руководство по агрегированию данных
В настоящем руководстве рассматривается пример использования узла Агрегирование. Для изучения данного раздела вам нужно знать, как создавать проекты, добавлять, соединять и выполнять узлы, а также использовать узел Файлы CSV. Если вы не знакомы с указанными понятиями, рекомендуем сначала изучить соответствующие разделы документации и практическое руководство Введение в анализ данных.
Узел Агрегирование относится к категории узлов для операций с таблицами. Он генерирует новую агрегированную таблицу на основе исходной таблицы с учетом некоторых настроек. Например, предположим, что у вас имеется таблица с данными по домашним питомцам. Предположим, что из данной таблицы вам нужно получить таблицу данных, в которой указывается средний возраст каждого типа домашних животных. Среднее значение представляет собой одно из агрегируемых значений.
Кличка питомца |
Тип питомца |
Возраст питомца |
Пушок |
Кот |
10 |
Рыжик |
Собака |
5 |
Барсик |
Кот |
2 |
Александр |
Слон |
15 |
Так как мы хотим получить средний возраст каждого типа питомца, выходная таблица должна содержать одну строку для каждого типа питомца. Поэтому колонка Тип питомца должна представлять ключ агрегирования, или колонку, по которой выполняется агрегирование. Колонка Возраст питомца – значение, которое мы будем агрегировать по типу питомца. Выходными данными узла агрегирования в этом случае будет новая таблица с колонками Тип питомца и Средний возраст, в которой каждая строка будет представлять собой тип питомца и его средний возраст.
Тип питомца |
Средний возраст |
Кот |
6 |
Собака |
10 |
Слон |
15 |
В приведенной выше таблице средний возраст для питомца Кот – 6 лет, т.к. в исходной таблице было две записи с питомцами типа Кот, первому было 10 лет, второму – 2 года. Средний возраст собак – 10 лет, поскольку имеется только 1 запись со значением 10 (10 делим на 1, количество записей с данным типом питомцев, получаем 10).
Данный сценарий достаточно прост; узел Агрегирование позволяет выполнять более сложную обработку данных. Во многих аналитических проектах "ключ", который уникально определяет запись, может состоять не из одной, а из нескольких колонок. Узел Агрегирование позволяет создавать сложные ключи (состоящие из нескольких колонок). В некоторых случаях вам может понадобиться несколько агрегированных значений (например, средний возраст и рост каждого питомца) и несколько агрегаций каждого значения (минимальный, средний и максимальный возраст для каждого типа питомца). Узел позволяет решать все эти задачи.
Обратите внимание, что не все колонки исходной таблицы появляются в выходной таблице. В приведенном примере в выходной колонке отсутствует колонка Имя питомца. Возможно, сначала это трудно понять, но при "сокращении" таблицы в агрегированную форму в нее будут включены не все колонки, поскольку каждая колонка в выходной таблице должна быть либо частью ключа агрегирования, либо результатом функции агрегирования (в нашем случае, ключ – тип питомца, функция – средний возраст по каждому типу питомца). Невозможно определить сумму или среднее значение клички питомца, поэтому данную колонку нельзя включить в выходную таблицу.
Пользователям, знакомым с командой SQL SELECT GROUP BY, легко будет понять и принцип работы узла Агрегирование. Результат, описанный выше, можно получить в SQL с помощью оператора SELECT, например: SELECT "Pet Type", AVG("Pet Age") as "Average Age" FROM Pets GROUP BY "Pet Type" ORDER BY "Pet Type". В этом отношении узел Агрегирование представляет собой графический интерфейс для ввода выражения SQL GROUP BY. Одним из преимуществ узла Агрегирование является то, что пользователи, которые не знают SQL, могут использовать тот же функционал с помощью простого инструмента.
В качестве другого примера рассмотрим следующий случай. Нам нужно объединить демографические данные клиентов или пациентов и транзакции по продажам или страхованию и получить общее количество прибыли по каждому клиенту. В этом случае мы будем использовать узел Агрегирование, чтобы агрегировать данные по страховым искам по идентификатору клиента, чтобы получить общую сумму по счету или общую сумму прибыли по каждому клиенту. Затем мы можем объединить агрегированные данные с данными профиля, используя узел Объединение.
Узел OLAP-таблица
Несмотря на то, что выходные данные узла Агрегирование включают обобщенные измерения данных, подобная форма представления агрегированных данных не всегда является самой удобной. Истинная цель узла Агрегирование – генерирование таблицы для последующих узлов обработки данных. Если цель анализа состоит в получении таблицы, которая будет использоваться для отчетности и просмотра, а не для дальнейшей обработки, лучше использовать другой узел, например, OLAP-таблица или Многомерная матрица. Эти узлы выполняют такие же операции, но выдают агрегированные результаты в интерактивной и более эстетичной форме.
Вкладка Уникальные записи
Если пользователям нужно увидеть список уникальных значений одной колонки, всегда можно выполнить агрегирование по этой колонке и просмотреть частоту каждого уникального значения. Однако гораздо проще в таком случае использовать вкладку Уникальные записи в выходной таблице предшествующего узла вместо того, чтобы использовать узел Агрегирование, поскольку выходные данные практически идентичные, и работа уже выполнена. Однако при работе с миллионами записей вкладка Уникальные записи может загружаться достаточно долго и требовать большого объема оперативной памяти. В этом случае узел Агрегирование является более масштабируемым и подходящим инструментом для просмотра такой информации. Недостатком в этом случае является наличие одного дополнительного узла на скрипте, который выполняет одну узкоспециальную операцию. Если узел не предназначен для повторного использования, то лучше всего использовать вкладку Уникальные записи.
Узел Уникальные записи
В то время, как узел Агрегирование может использоваться для удаления повторяющихся записей из таблицы (при этом нужно использовать все колонки в качестве ключа агрегирования), более подходящим инструментом для такого случая является узел Уникальные записи. Оба узла генерируют похожие таблицы, но основное отличие состоит в том, что узел Уникальные записи включит в выходную таблицу все исходные колонки, а при агрегировании в выходную таблицу войдут колонки ключа и колонки с агрегированными значениями. При этом узел Уникальные записи отбирает для выходной таблицы только часть исходных данных согласно заданному ключу, что предполагает потерю данных. Выбор между узлами зависит от типа выходных данных, которые вы хотите получить, в частности, необходимо понимать, понадобятся ли вам в дальнейшем колонки, которые невозможно агрегировать.
В некоторых случаях похожий функционал предлагают узлы Структурная организация и Развертка транзакций, в которых записи группируются в соответствии с ключом. Однако цель данных узлов состоит в частичном транспонировании данных для дальнейшей обработки.
Для того, чтобы понять, как работает узел Агрегирование, выполните следующее:
Шаг 2: Загрузите данные
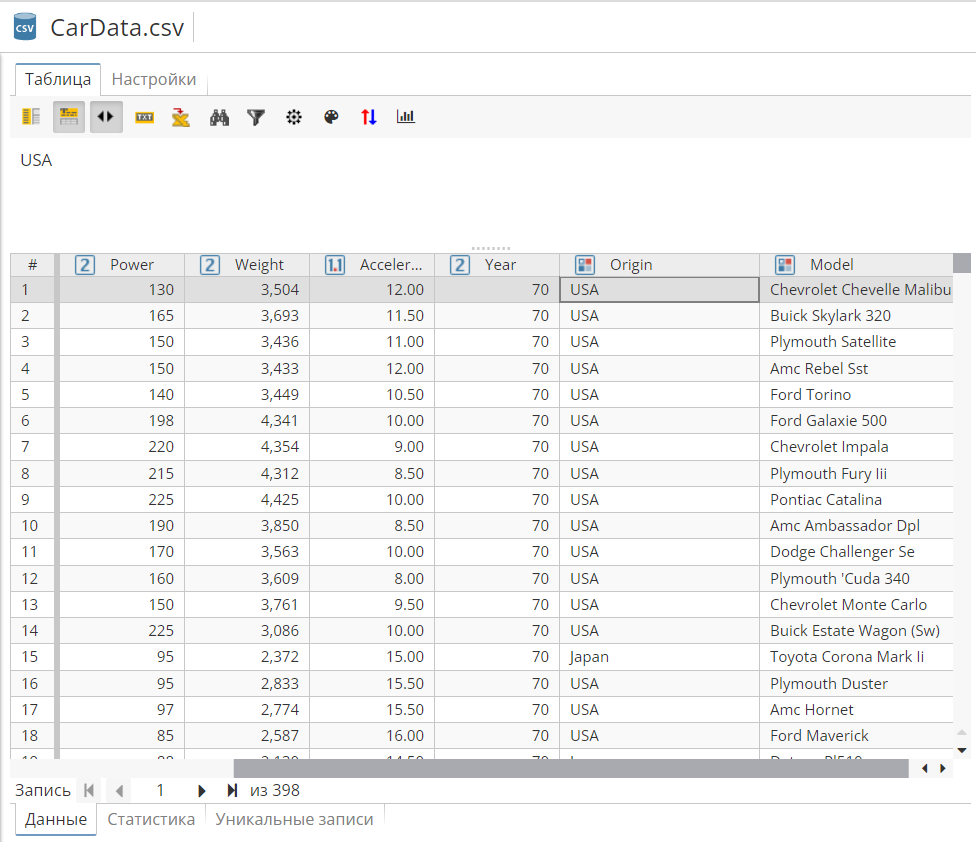
Добавьте узел Файлы CSV на скрипт. Настройте его на загрузку файла CarData.csv, расположенного в папке Examples. Убедитесь, что данные в колонках Origin (Страна-производитель) и Model (Модель) являются строковыми. Выполните узел. В окне просмотра вы должны увидеть следующее:
Шаг 3: Добавьте узел Агрегирование и соедините с предыдущим узлом
Добавьте узел Агрегирование (в палитре узлов находится в разделе операций с таблицами) и соедините его с узлом Файлы CSV. Скрипт будет выглядеть следующим образом:
Шаг 4: Настройте атрибуты
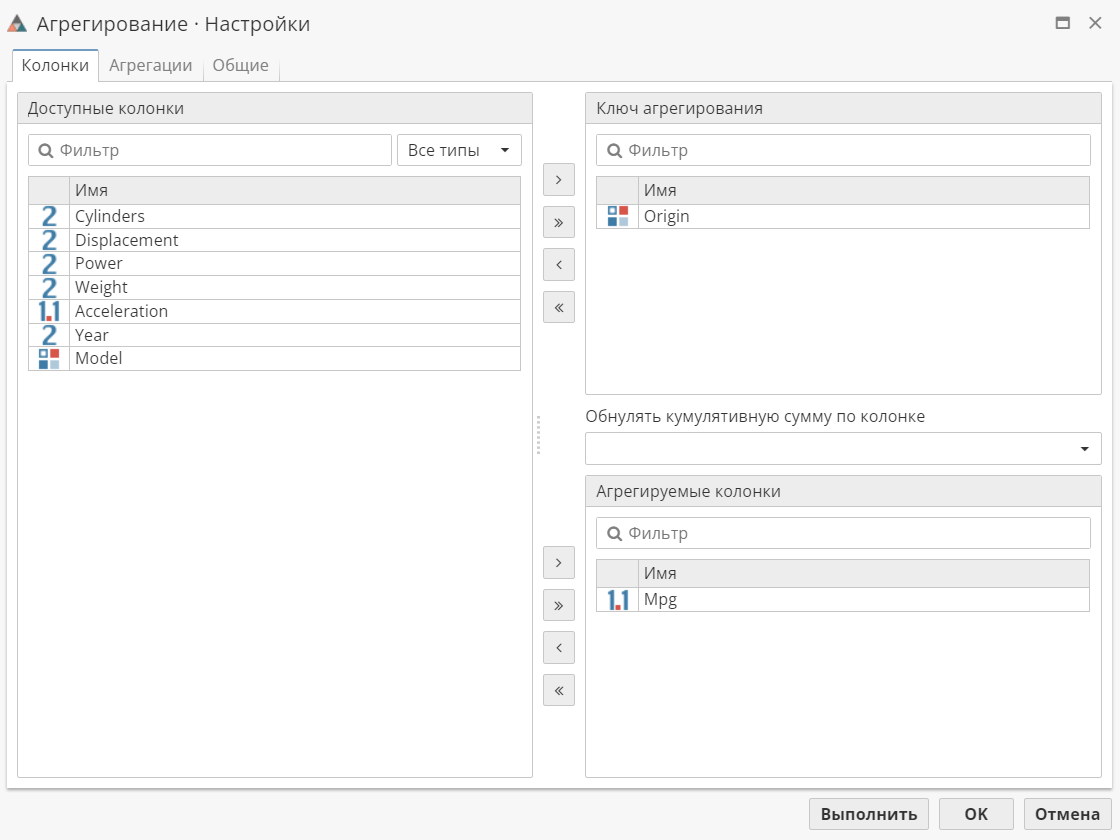
Откройте окно Настройки узла Агрегирование. Предположим, что мы хотим определить среднюю топливную экономичность автомобиля (количество миль на галлон бензина) по стране-производителю. Каждая запись в исходной таблице представляет отдельное наблюдение за автомобилем и содержит ряд его характеристик. Для каждого производителя мы можем рассчитать среднюю топливную экономичность. Для этого на вкладке Колонки выберите колонку Origin в качестве ключа агрегирования, а Mpg (расстояние в милях на галлон бензина) в качестве агрегируемой колонки.
Шаг 5: Настройте агрегации
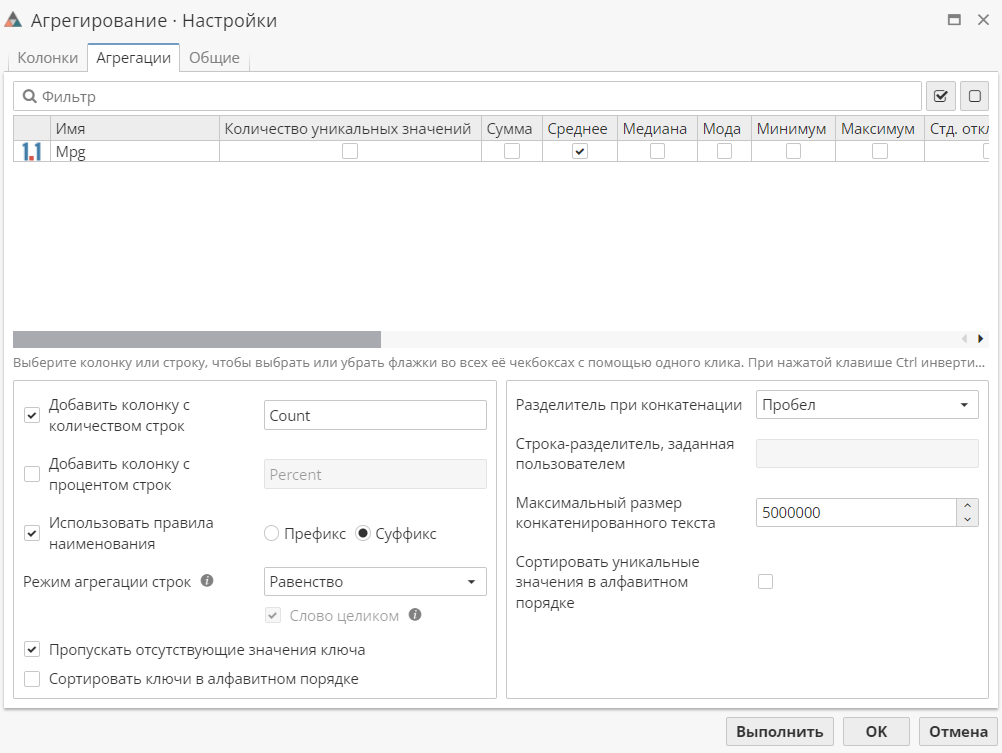
Переключитесь на вторую вкладку и укажите, что мы хотим вычислить среднее значение для Mpg. Отметьте опцию Пропускать отсутствующие значения ключа, если она не включена; поскольку нас не интересуют те автомобили, производитель которых неизвестен. В разделе Использовать правила наименования оставьте суффикс. Для Режима агрегации строк оставьте Равенство. Включите опцию Добавить колонку с количеством строк и оставьте значение Count в качестве имени для новой колонки: так мы увидим, сколько записей было агрегировано для каждого значения страны-производителя. Вкладка должна выглядеть следующим образом:
Шаг 6: Выполните узел и просмотрите результаты
Настройка завершена, нажмите Выполнить. Когда узел будет выполнен, откройте окно просмотра результатов.
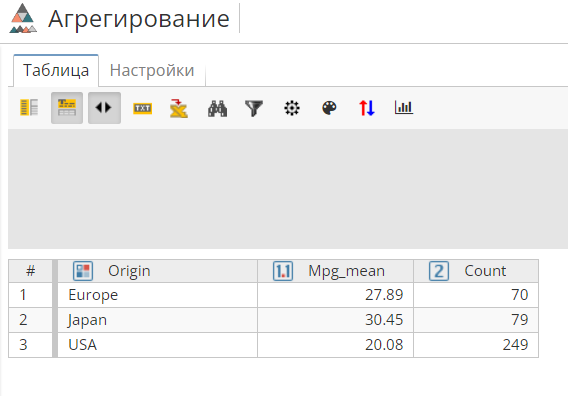
-
В выходных данных имеется 3 строки. Это означает, что значений Страна-производитель всего 3; как видим, это – Европа, Япония и США.
-
Для каждой страны мы видим новую колонку, Mpg_mean (Среднее значение пробега на галлон топлива), которая содержит среднее значение расстояния в милях на галлон бензина для автомобилей с указанным производителем. Взглянув на данные в "агрегированной" форме, мы увидим, что в среднем, расстояние в милях на галлон у японских машин выше, чем у американских.
-
В 3 колонке, Count (Количество), содержится количество записей для каждой страны в исходной таблице. Очевидно, что большая часть проверенных машин была произведена в США. К счастью, количество значений не сильно влияет на среднее значение, следовательно, мы получили полезные данные по топливной экономичности автомобилей для каждой страны-производителя.
-
Теперь мы можем продолжить работу с новой таблицей данных, созданной узлом Агрегирование, так же, как с таблицей, которую мы загрузили из базы данных или файла. Мы можем переименовать колонку Mpg_mean на Average Miles Per Gallon (Среднее расстояние в милях на галлон) в последующем узле Модификация колонок.
-
Мы можем выбрать подходящее имя для того, чтобы обозначить цель узла Агрегирование, или для того, чтобы отразить суть выходных данных. Например, название Average Miles Per Gallon (Среднее расстояние в милях на галлон) четко описывает выходные данные, и, при условии того, что нам известны исходные данные, мы можем сделать вывод о том, как были вычислены выходные данные.
Шаг 7: Поэкспериментируйте с другими настройками
Попробуйте самостоятельно перенастроить узел Агрегирование, чтобы рассчитать минимальное, максимальное значение и стандартное отклонение, а также диапазон отклонений расстояния в милях на галлон бензина. Попробуйте агрегировать колонку Weight (Вес) или какую-либо другую. Попробуйте выполнить конкатенацию моделей автомобилей по стране-производителю. Как видите, принцип работы узла Агрегирование позволяет использовать его для решения многих задач при работе с одной таблицей данных. В данном случае, наша цель – изучить, когда и как использовать узел Агрегирование в анализе данных.
Не забудьте сохранить свой проект, чтобы впоследствии его можно было использовать для справки.