Настройки подключения к данным и API
Настройки подключения к данным можно использовать для конфигурации источников импорта данных на сервер PolyAnalyst и настроек экспорта данных с сервера.
В сущности мы можем разделить настройки подключения к данным на несколько категорий:
Подробное описание настроек подключения к данным см. ниже.
По умолчанию при импорте данных в проект PolyAnalyst, например, через узел Файлы CSV вам будет доступна папка с тренировочными наборами данных, Диск PolyAnalyst и файлы вашего ПК (при условии, если сервер PolyAnalyst установлен на том же компьютере, что и клиент).
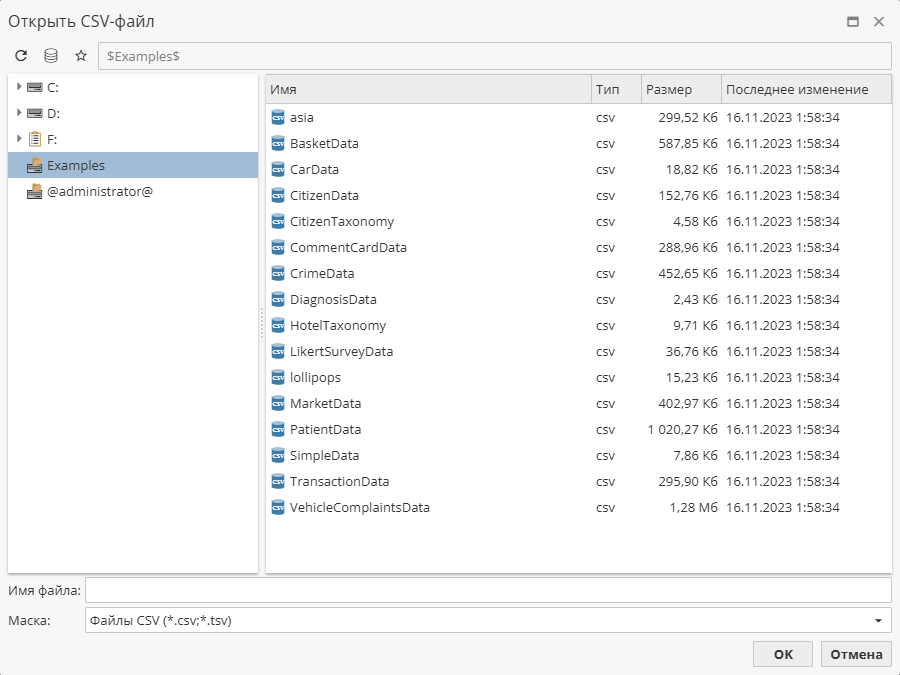
Настройки подключения к данным позволят вам задать различные источники импорта данных.
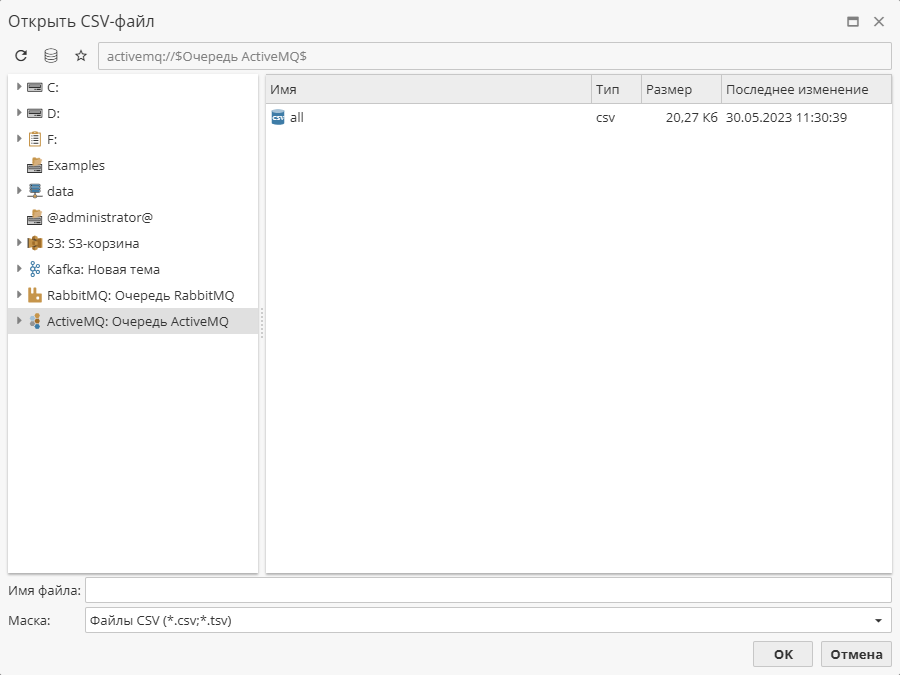
Обычный пользователь также может задать настройки подключения к данным. Это делается через окно конфигурации узлов импорта. Для этого нажмите кнопку Источник подключения к данным.
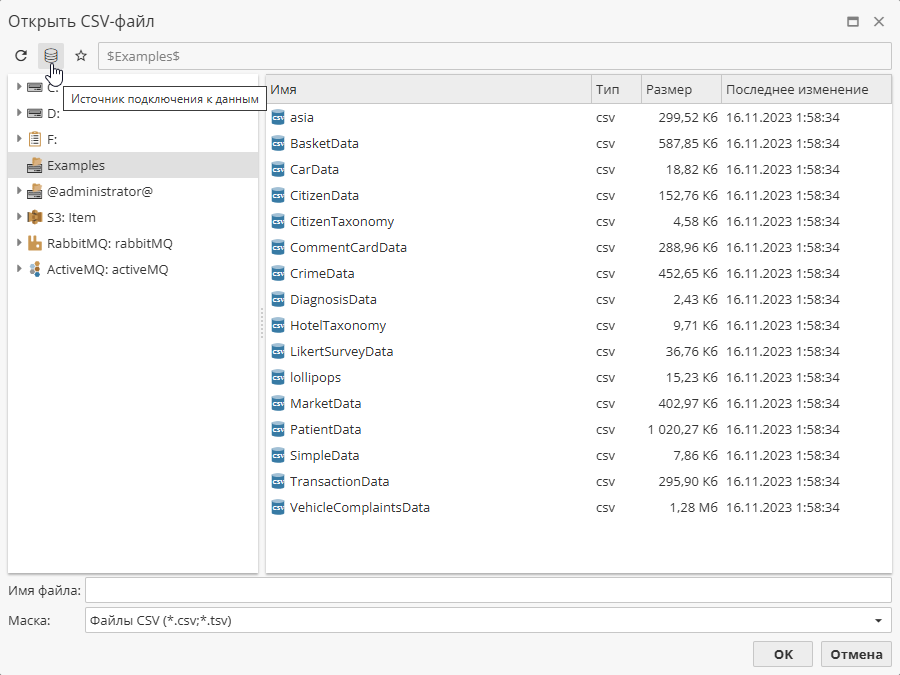
Настройки подключения к данным также можно использовать при экспорте данных, например, при подключении узла Экспорт в файл.
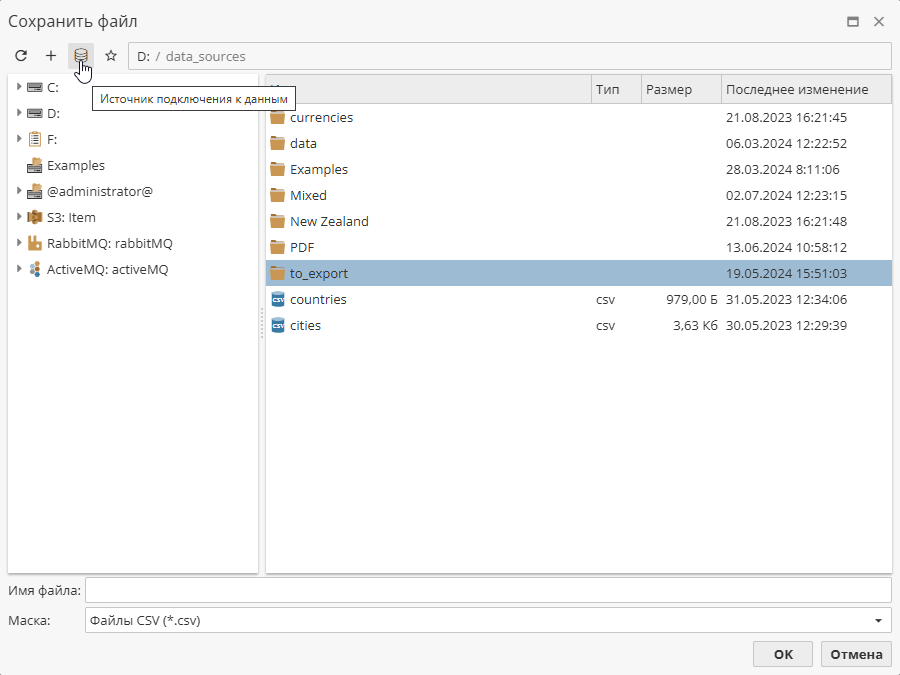
Отметьте соответствующий чекбокс, чтобы разрешить экспорт данных.
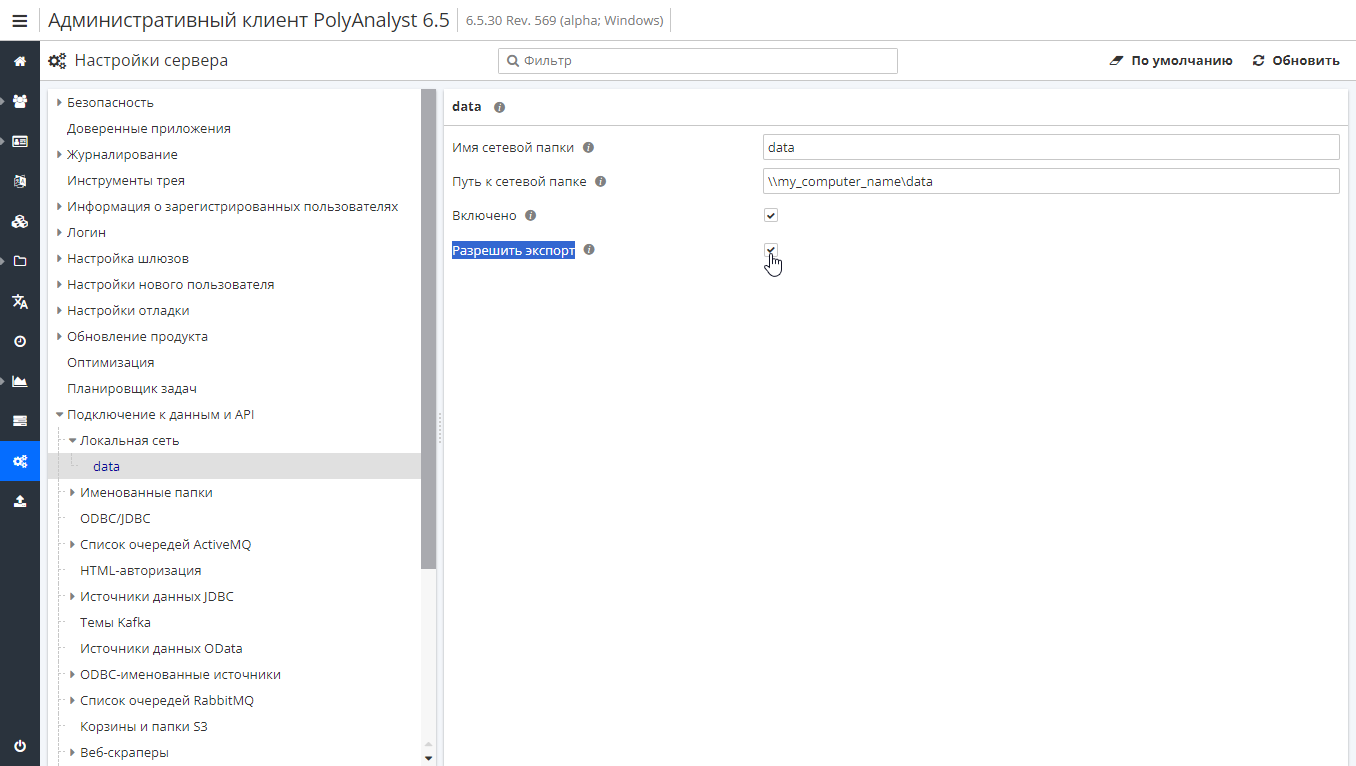
Подробнее о настройках подключения к данным см. в соответствующих разделах:
Сетевые подключения и именованные папки
Когда мы говорим о подключениях по сети, мы обычно подразумеваем использование локальной сети и именованных папок.
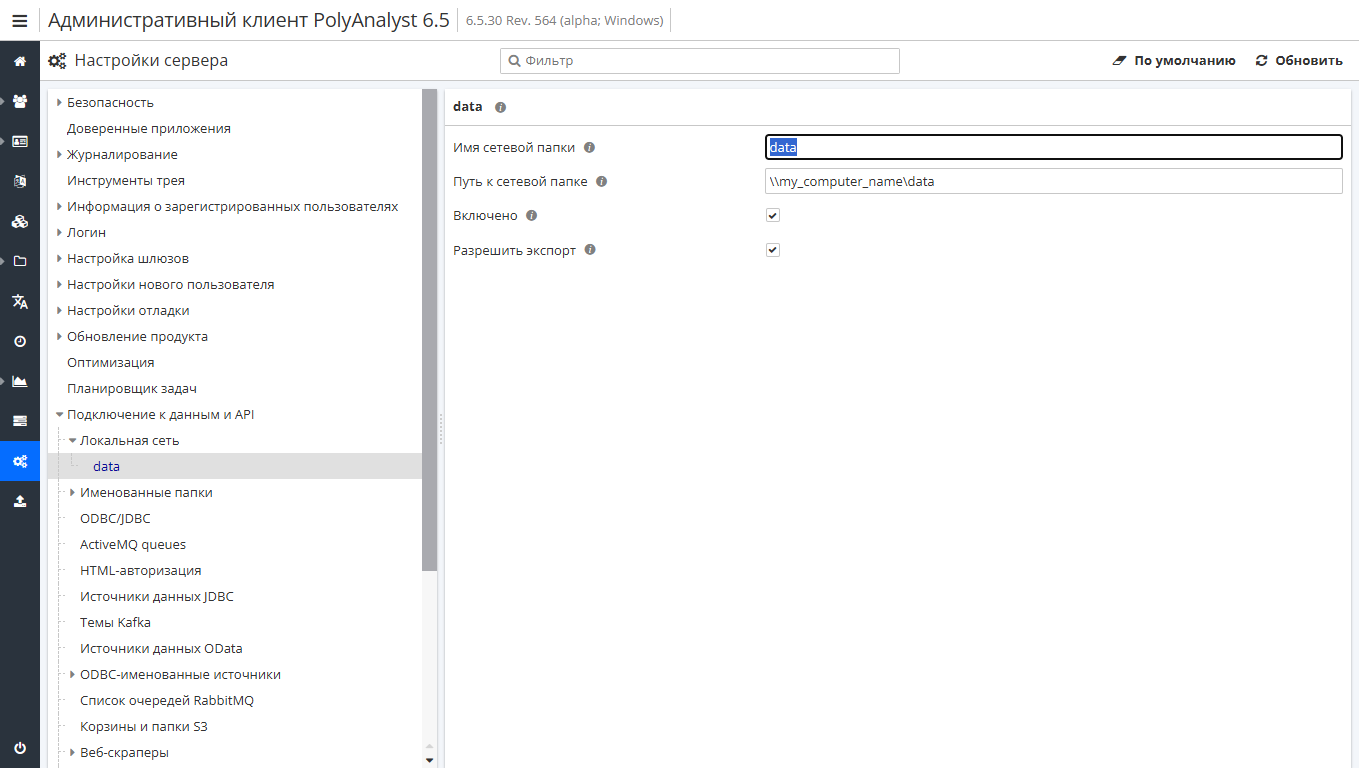
Так, например, вы можете подключиться к папке, к которой был предоставлен общий доступ в вашей сети.
Вы также можете сделать папку именованной – это значит, что доступ к этой папке будет задаваться через алиас. Например, под именем "my_folder" вы можете указать путь D:\data\my_folder. Сюда относятся локальные как локальные папки, так и удаленные, доступ к которым выполняется по сети (например, \\SomeComputer\folder).
Вы также можете использовать веб-скраперы для загрузки данных в PolyAnalyst.
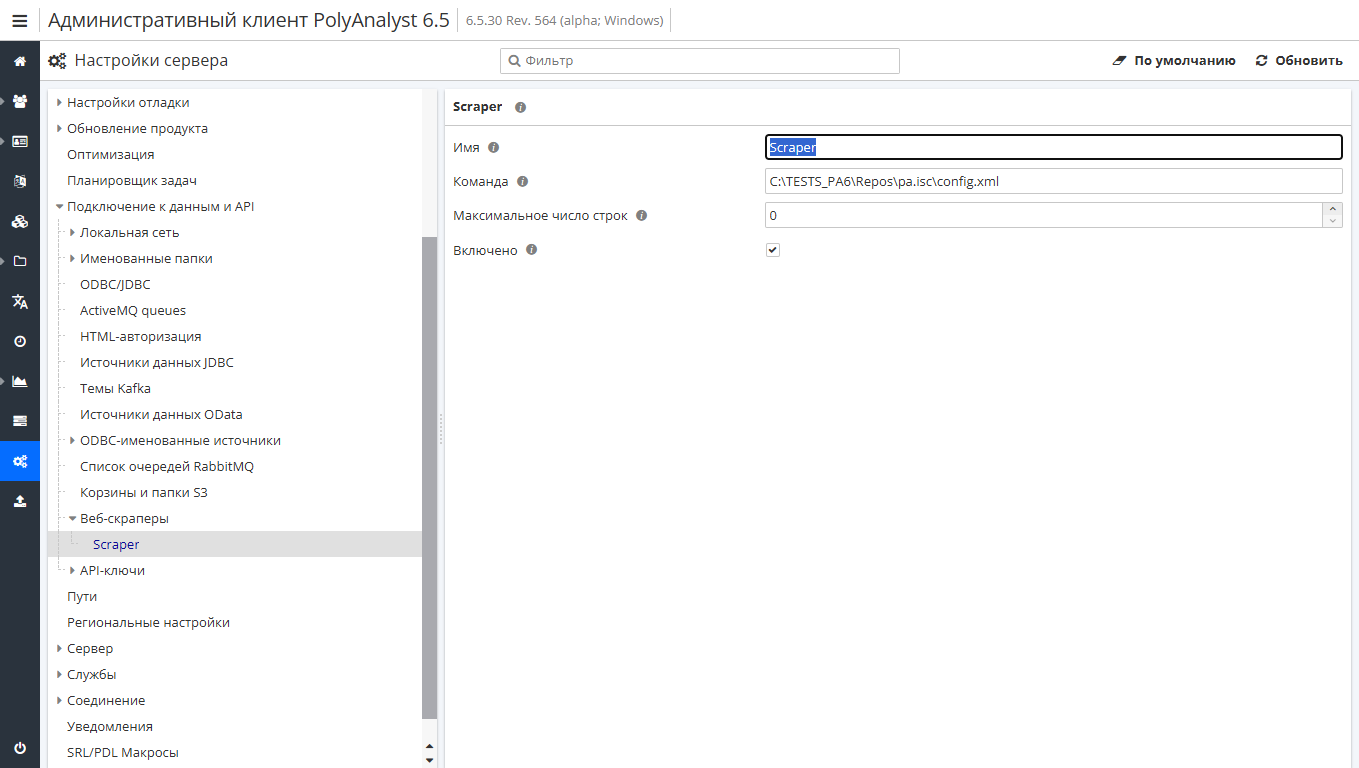
Вы можете написать свой собственный веб-скрапер (например, используя Python) для загрузки данных через узел Интернет.
| Использование пользовательских веб-скраперов должно быть разрешено на вкладке Безопасность в настройках сервера. Для этого отметьте чекбокс Разрешить пользовательские веб-скраперы. |
Иногда при использовании веб-скраперов необходима авторизация на том или ином ресурсе. В качестве одного из видов авторизации вы можете использовать авторизацию через HTML.
| Авторизация через HTML доступна только для веб-скрапера по умолчанию. |
В качестве инструмента подключения к данным также используется API. Одним из протоколов, которые используют API, является протокол OData. Доступ к OData осуществляется через узел одноименный узел.
Настройки подключения к данным через API позволяют задать ключ для следующих сервисов:
-
ChatGPT
-
MegaGPT
-
YandexGPT
-
GigaChat
Подробнее см. в соответствующем разделе.
Подключения к базам данных
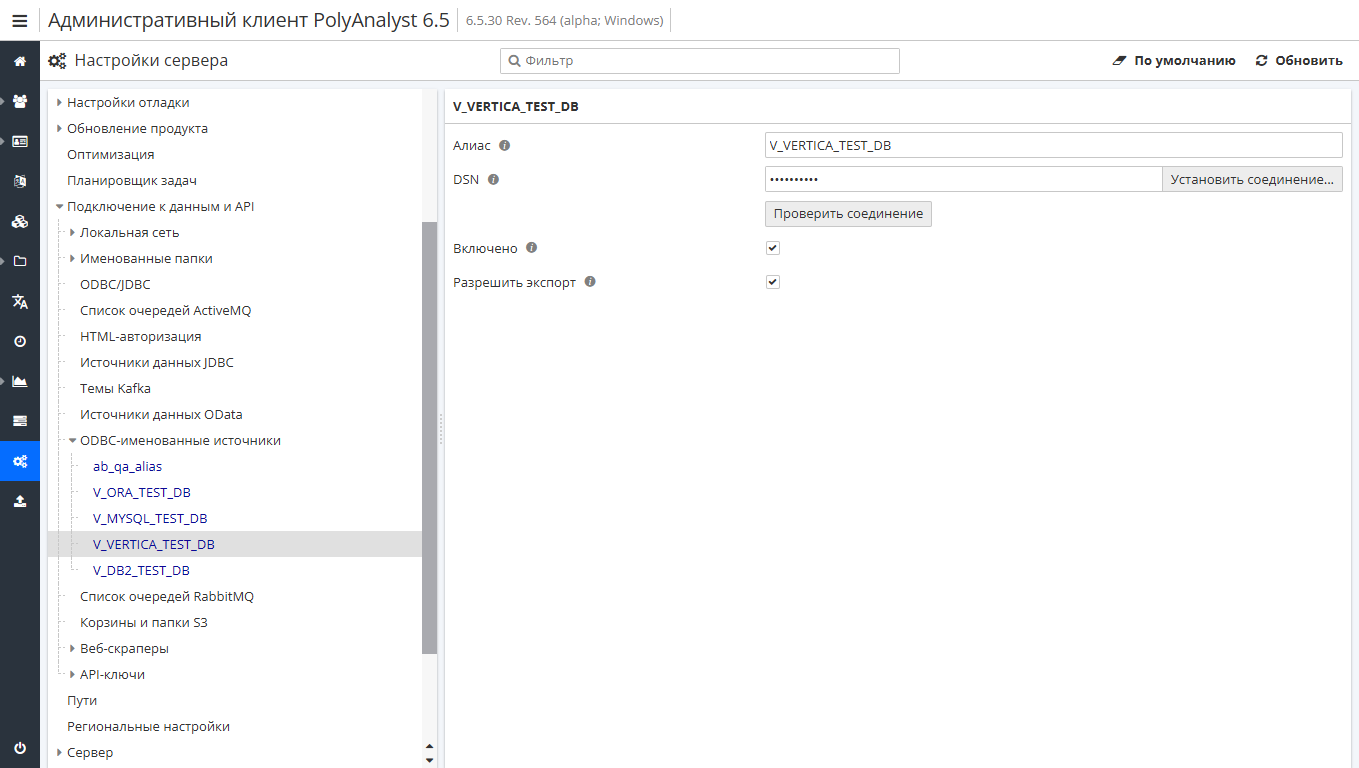
Подключения к базам данных выполняются через ODBC- и JDBC-интерфейсы.
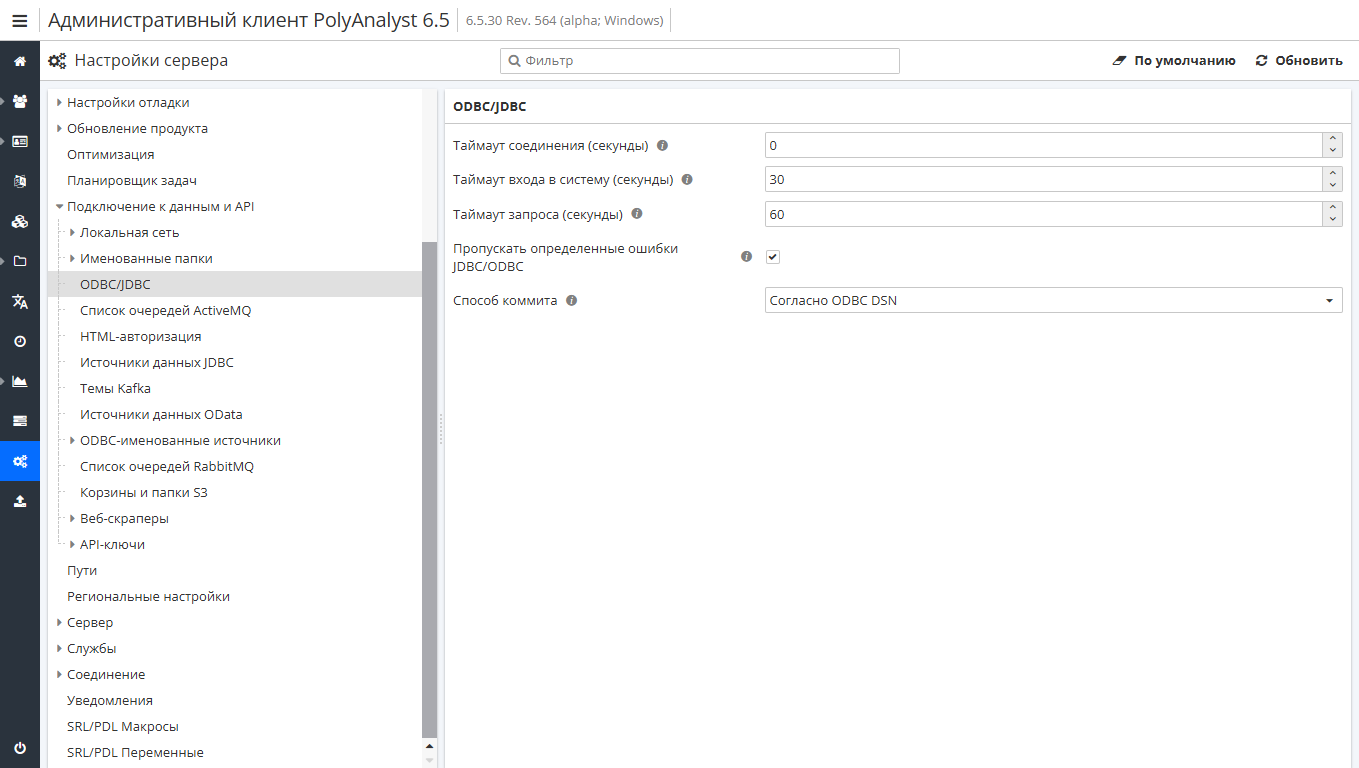
Обратите внимание, что конфигурация ODBC-именованных источников и Источников данных JDBC задается по отдельности.
Отдельно стоит сказать про сервис S3.
Сервис S3 (Simple Storage Service), разработанный Amazon, хранит данные в так называемых корзинах – в специальных хранилищах различных форматов данных. Основное преимущество протокола S3 заключается в том, что данные хранятся в "плоском" формате – каждый объект имеет свой уникальный идентификатор, а все объекты, которые находятся в корзине, рассматриваются как равные друг другу. Это позволяет легко получить доступ к файлу без указания точного пути.
Брокеры сообщений
Третья категория, брокеры сообщений, представляет собой удобный инструмент для отправки/получения данных с сервера PolyAnalyst или на него.
Брокер сообщений представляет собой программное обеспечение, которое, в общих словах, принимает данные, хранит их и затем передает дальше. Например, такими данными могут быть файлы формата CSV.
Работа брокера сообщений обычно состоит из 3 этапов:
-
получение информации от продюсера данных (от англ. produce – производить);
-
хранение данных (сам брокер сообщений);
-
передача данных потребителю.
Сначала данные забираются у продюсера, затем сервис, обычно называемый брокером, передает эти данные одному или нескольким потребителям. Таким потребителем может быть как другой сервис, так и конечный пользователь. После того, как данные будут переданы потребителю, они удаляются из хранилища брокера (однако такое поведение зависит от конкретной реализации брокера сообщений).
В настоящее время в PolyAnalyst поддерживаются следующие брокеры сообщений:
Сервис Apache Kafka хранит данные в топиках, т.е. в некой последовательности объектов, которые используются в качестве хранилищ. При получении данные не удаляются из топика, а сохраняются для других потребителей.
Сервис RabbitMQ использует понятие очереди для хранения данных. Как только пользователь получает данные, они удаляются из хранилища. Основная идея RabbitMQ заключается в использовании обменника (Exchange) – промежуточного шага между продюсером и очередью. Продюсеров и очередей может быть несколько (как и несколько потребителей), но используется только один обменник.
Сервис ActiveMQ схож с RabbitMQ, но отличается от него по возможностям масштабирования: ActiveMQ использует вертикальный, горизонтальный и разделяющий типы масштабирования, в то время как RabbitMQ использует вертикальный и горизонтальный типы. Первый тип предполагает масштабирование количества подключений к брокеру, в то время как второй тип ориентируется на количество самих брокеров.
Каждый брокер сообщений настраивается схожим образом, хотя конфигурация конкретного брокера зависит от его реализации.