Шаг 8: Кластеризация автомобилей
Кластеризация позволяет выявлять ключевые переменные и сегменты данных. Это полезный инструмент предварительной обработки данных, который позволяет изучить кластеры переменных с целью выявления в них скрытых тенденций и шаблонов. Каждому кластеру на выходе присваивается уникальное имя (ID), что дает возможность обработки полученных кластеров последующими узлами. Поскольку кластеризация не требует глубокого знания анализируемых данных, она обычно выполняется на раннем этапе анализа с целью получения общего представления о ключевых переменных и группах записей. Кластеризацию можно рассматривать как один из способов сокращения данных, что достигается за счет сокращения количества атрибутов для анализа таблицы данных. Кластеризация позволяет выявить посторонние значения в таблицах данных путем обнаружения значений, которые не принадлежат обнаруженным кластерам. В данном примере кластеризацию можно использовать для объединения похожих автомобилей в группы и для определения того, какие атрибуты используются для сравнения автомобилей друг с другом, а также для выявления пороговых или конкретных значений данных атрибутов, которые используются для сравнения.
Кластеризация считается формой обучения данных без учителя. Кластеризация отличается от классификации тем, что алгоритму классификации известны целевые классы и их количество (значения моделируемой выходной переменной), а алгоритму кластеризации - нет. Кластеризацию также называют анализом, управляемым данными, поскольку результаты алгоритма зависят от структуры самих данных; участие человека в таком анализе минимально.
Цель кластеризации - группировка записей на основе какого-либо сходства. Выходные данные узла кластеризации представляют собой набор групп подобных записей. С другой стороны, кластеризацию можно рассматривать как деление записей на группы, отличные от других групп. В теории глубокого анализа данных кластеризация определяется как процесс деления таблицы данных на значимые подмножества, которые называют классами, категориями или кластерами. Следовательно, кластер - это подмножество записей, между которыми наблюдается некоторое сходство. Сходство записей в пределах одного кластера более очевидно по сравнению с записями других кластеров.
Кластеризация применяется в различных сферах и типах анализа. Человек сталкивается с кластеризацией ежедневно. Так, например, в супермаркете продукты распределены по отделам, что позволяет нам легко ориентироваться по указателям и находить нужные нам товары. Вот некоторые другие примеры кластеризации:
-
Маркетинг - сегментация рынка, моделирование покупательского поведения.
-
Медико-биологические науки - именование новых видов путем выявления их сходства с существующими; классификация заболеваний на основе сходства симптомов, осложнений или способа лечения.
-
Страхование - выявление сегментов рынка страхования; обнаружение посторонних значений, что позволяет выявлять незаконные страховые требования.
-
Данные переписи населения - выявление демографических кластеров (распределение населения по доходу, семейному положению, количеству детей, возрасту и др.).
-
Отслеживание и анализ статистики посещаемости сайтов, анализ путей, проходимых по сайту посетителями.
-
Автомобили - распределение автомобилей по группам в зависимости от их мощности, расхода топлива с целью помочь покупателю принять выгодное решение о покупке, производителю - улучшить качество и дизайн продукции.
-
Выявление тенденций - выявление общности, ассоциаций и др.
-
Анализ пространственных данных - иногда в составе геоинформационной системы (ГИС), выявление сходных зон на карте по слоям (дороги, трубопровод, население, высота над уровнем моря и др.).
-
Обработка изображений - их группировка по различным характеристикам.
Практический эксперимент
Понять принцип кластеризации можно с помощью практического эксперимента, который вы можете выполнить самостоятельно, не прибегая к использованию программного оборудования. Алгоритмы кластеризации действуют подобно нашей логике. Возьмем для примера какой-либо набор предметов, скажем, содержимое вашей кладовки, или предметы на письменном столе. Разложите все предметы на полу. Затем подумайте, как их лучше разделить на группы. После того, как вы сделаете это, верните все на свои места, разложив предметы, следуя своей логике. Теперь попробуйте ответить на следующие вопросы:
-
Сколько групп предметов вам необходимо для того, чтобы все предметы принадлежали какой-либо группе, или все предметы в одной группе были максимально похожи друг на друга и отличались от предметов другой группы? Одна из трудностей, с которой сталкивается любой алгоритм кластеризации, - определить нужное количество кластеров.
-
Какие характеристики предметов вы учитывали при сравнении? Были ли это сами продукты, форма коробки, ее размер, этикетка, частота использования, хрупкость или что-то другое? Другая сложность в работе алгоритма кластеризации - правильный выбор параметров сравнения.
-
Придумали ли вы легко запоминаемые названия (метки) для выделенных групп? Алгоритм кластеризации определяет, как пометить кластер.
-
Как вы обобщите назначение кластера? Важно не только то, что два предмета входят в одну группу в связи с тем, что они похожи друг на друга, но и то, насколько они похожи.
-
Как вы определили степень сходства (в математике она обозначается термином расстояние) между ними? Сгруппировали ли вы продукты по содержанию в них сахара и по какому-то другому принципу? Достаточно сложно бывает определить и измерить сходство между точками данных.
-
Есть ли предметы, которые не вписались ни в одну группу? Потребовалось ли вам пересмотреть содержимое групп или объединить их в отдельную группу под названием "Разное"? Это и есть посторонние значения в таблицах данных, которые необходимо выявлять и иногда удалять, чтобы облегчить работу алгоритма, при этом некоторые алгоритмы кластеризации оставляют несколько записей некластеризованными. Такое явление называется покрытием кластера. Надежные алгоритмы кластеризации позволяют достичь высокой степени кластеризации данных. Если алгоритм распределяет по кластерам только 10 элементов из 100, он не очень полезен.
-
Вам было сложно описать некоторые предметы прежде, чем определить их в какую-либо группу? Когда вы брали в руки предмет, было ли иногда сложно понять, что это, например, из-за большого количества различных наклеек на коробке? Алгоритмы кластеризации в отдельных сценариях часто имеют дело с избыточными исходными данными; они должны обладать определенными функциями, позволяющими игнорировать незначительные характеристики данных или представлять их в упрощенном виде.
Это лишь небольшой перечень вопросов, на которые отвечает алгоритм кластеризации при работе с новой таблицей данных. Необходимо помнить о том, что алгоритм кластеризации - наивный математический инструмент. В отличие от него, интуиция человека строится на опыте и фоновых знаниях о предметах, которые мы делим на кластеры. Эти фоновые знания недоступны алгоритму кластеризации, ему приходится обходиться только теми данными, которые он получает на входе, в связи с чем полученные результаты не всегда могут оправдать наши ожидания. Возможно, вам понадобится ввести в исходную таблицу данных дополнительные атрибуты или мета-атрибуты, так или иначе характеризующие те данные, которые вас интересуют. На практике, например, в ходе проведения социологического исследования, возможно, вам сначала придется опробовать его вопросы, и лишь потом приступить к самому исследованию для того, чтобы убедиться в том, что вы приготовили достаточное количество вопросов, которые позволят вам разделить респондентов на кластеры. И наконец, важно помнить следующее. В связи с тем, что алгоритмы кластеризации работают с символами, а не с идеями и понятиями, иногда они выдают такой результат, который требует дополнительной интерпретации с помощью человеческой логики и интуиции.
Кластерный алгоритм максимизации ожидания в системе PolyAnalyst
Существует несколько алгоритмов кластеризации, применяемых в анализе данных, например, метод k-средних, DBSCANS, CLARANS, BIRCH и др. В системе PolyAnalyst применяется специальный эксклюзивный алгоритм кластеризации, называемый Максимизацией ожидания (МО).
Максимизацию ожиданий (МО) можно сравнить с методом k-средних, самым часто используемым алгоритмом. Однако МО можно считать более совершенным инструментом, поскольку алгоритм определяет возможность принадлежности записи к кластеру на основе одного или нескольких вероятностных распределений, в то время как метод k-средних максимизирует различия в средних значениях для непрерывных переменных. Задачей алгоритма является максимизация общей вероятности данных. Алгоритм максимизации ожидания можно применять в отношении категориальных переменных (строк). Метод k-средних тоже можно несколько модифицировать для работы с категориями. С технической точки зрения, МО не сразу распределяет записи по кластерам; сначала алгоритм определяет вероятность того, что запись может принадлежать кластеру. Далее, на основе наибольшей вероятности, запись определяется в наиболее подходящий кластер.
Кластеризация автомобилей
В данном руководстве используется таблица с данными об автомобилях CarData.csv. Наша цель - выявить группы машин и ключевые характеристики каждой группы, чтобы определить, как были выделены кластеры, с тем чтобы иметь возможность интерпретировать результаты работы узла.
Добавьте узел Максимизация ожидания на скрипт (он расположен в разделе Анализ данных в палитре узлов). Соедините узел Фильтрация колонок, который вы создали ранее, с новым узлом Максимизация ожидания, и откройте окно настроек нового узла. Теперь ваш скрипт выглядит примерно так:
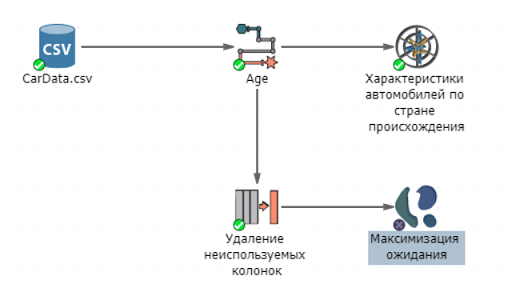
В данном руководстве мы намерены учитывать значения всех колонок, кроме Model. Алгоритмы кластеризации работают эффективнее после удаления аномальных записей. К аномальным записям могут относиться ошибки, допущенные при сборе и записи данных, неточности в измерениях и др. Имеется целый ряд причин, по которым данные могут быть непригодны для использования, однако они не являются предметом анализа в данном руководстве.
Первый шаг - настройка колонок. Переместите все доступные колонки в список выбранных колонок.
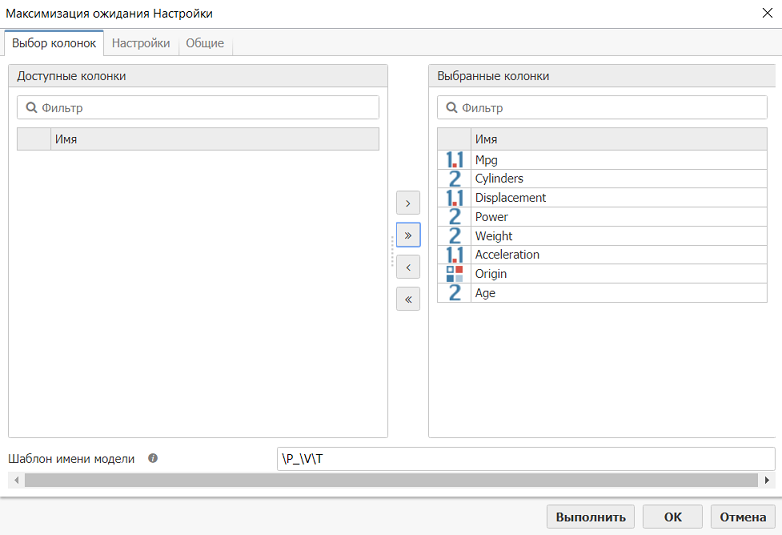
На вкладке Настройки задайте количество кластеров - 3. Это число выбрано условно. На практике нужно очень четко продумать количество кластеров на выходе. Возможно, вам придется не один раз запускать алгоритм, задавая новое количество кластеров. Если неверно задать количество кластеров, можно получить искаженные данные. Иначе говоря, неправильно выбранное количество кластеров может помешать пользователям максимально эффективно проанализировать данные.
Вот простейший пример с пакетом красных и черных шариков. Очевидно, что эти шарики можно разделить на две группы - черные и красные. Мы могли бы определить размер шариков (радиус), гладкость поверхности или качество, матовость, вес и другие характеристики. Но предположим, что цвет - единственный определяющий атрибут. Если бы вы захотели получить три кластера на выходе, алгоритм попытался бы их выявить, даже несмотря на то, что их только два; результат был бы бесполезен. Так обычно и происходит с реальными таблицами данных, тем более что вам неизвестно, что вы имеете только два цвета; вы также не знаете, какие характеристики нужно использовать для сравнения.
Выберите "свободный" режим алгоритма. Алгоритм кластеризации системы PolyAnalyst может работать в "свободном" или "жестком" режиме (без потери информации). В "свободном" режиме он выявляет широкие кластеры с большим разбросом значений, в "жестком" - более плотные кластеры. При выборе "свободного" режима алгоритм работает медленнее, но полученные кластеры легче поддаются интерпретации. По умолчанию используется жесткий режим кластеризации "без потери информации".
На вкладке Общие укажите имя узла - "3 свободных кластера".
Выполните узел. Поскольку записей и колонок немного, алгоритм быстро завершит свою работу. Алгоритм кластеризации системы PolyAnalyst предназначен для обработки большого количества записей. Для завершения работы алгоритма на практике может уйти от нескольких минут до нескольких часов, в зависимости от числа строк и колонок в исходной таблице.
Откройте окно просмотра результатов узла Максимизация ожидания (выберите опцию Показать в контекстном меню узла). Перейдите на вкладку Кластеризация. Вы увидите 3 кластера и их размер (количество записей в каждом) в таблице в верхнем левом углу. Справа - детали текущего кластера (по умолчанию - первого), внизу - записи, входящие в выбранный (первый) кластер.
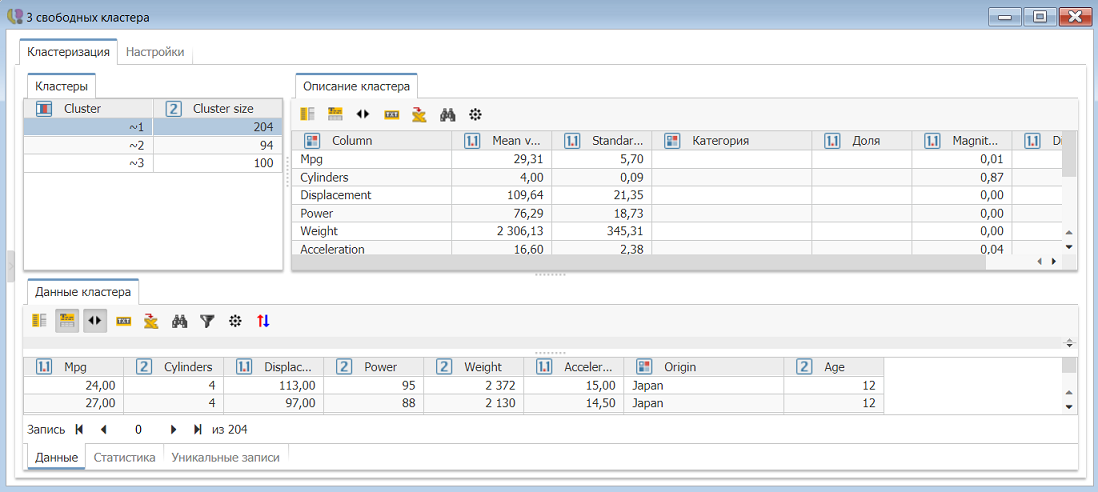
В верхней таблице слева указан размер трех кластеров - 98, 204 и 96 записей, соответственно. Справа отображаются все свойства выбранного кластера. Среднее значение Mpg составляет 20,34. Если вы временно переключитесь на второй кластер, среднее значение Mpg в нем будет выше (29,29). В третьем оно составит 14,53, что значительно меньше, чем в первых двух кластерах. Это среднее значение можно считать центром выбранного кластера, если оценивать кластеры только по значению Mpg. Стандартное отклонение среднего значения Mpg позволяет нам определить дисперсию и диапазон. Колонка Magnitude показывает вес значений Mpg при выявлении 3 кластеров, и содержит значения 0,05, 0 и 0,03. Это позволяет сделать вывод о том, что значения Mpg не сыграли большой роли для определения принадлежности записи к тому или иному кластеру. Колонка Distinction позволяет оценить, насколько полно атрибут описывает выбранный кластер по сравнению с другими кластерами, и для Mpg составляет 0,37, 0,27 и 0,36. Ни одно из этих значений не близко к 1. Однако по сравнению с другими значениями, этот показатель Mpg является более ярко выраженным отличительным признаком первого кластера, менее значимым для третьего, и практически не является отличительным признаком второго кластера.
В первом кластере Origin имеет наибольшую значимость 0,54, и второе по величине значение отличия - 0,37, а это дает 83%-ю вероятность того, что автомобиль был произведен в США. 83% записей из первого кластера описывают автомобили, произведенные в Америке. В результате мы делаем вывод о том, что страна происхождения автомобилей - ключевая характеристика, которая позволяет поделить их на группы, и почему записи попали в первый кластер.
Во втором кластере на каждого производителя приходится примерно равное количество автомобилей (по 1/3 от общего количества), показатели значимости и отличия низкие. Возраст автомобилей во втором кластере имеет наибольшее стандартное отклонение по сравнению с другими кластерами, а его значимость равна 0. Во втором кластере значимость количества цилиндров составляет 0,99, а это значит, что именно количество цилиндров в автомобилях полностью описывает этот второй кластер. Цилиндры также имеют наибольшее отличие (0,99), с большим отрывом за ними следуют смещение (0,63) и вес (0,47). Также обратите внимание на то, что во втором кластере среднее значение Mpg почти в два раза больше, чем в третьем кластере. Как оказалось, все эти автомобили имеют 4-цилиндровые двигатели.
Все автомобили в 3 кластере произведены в США в 1970 г. Если учесть, что в таблице представленны автомобили, произведенные в период с 1970 г. по 1982 г., то в этом кластере оказались самые старые американские автомобили. По сравнению с другими кластерами, они имеют больший средний вес, наименьший пробег на галлон бензина, наибольшее количество цилиндров, и наибольшее ускорение (минимальное количество секунд, необходимое для разгона до 100 миль в час).
Итак, на основе этих наблюдений мы можем сделать некоторые общие выводы об исходных данных:
-
Первый кластер, в основном, содержит американские автомобили с усредненными техническими характеристиками.
-
Второй кластер содержит 4-цилиндровые автомобили эконом-класса с наиболее высокими показателями топливной экономичности; 65% этих автомобилей произведены в Японии и в Европе.
-
Третий кластер представлен старыми американскими автомобилями, так называемыми маслкарами (muscle car), с высокой удельной мощностью (модели Torino, Galaxie, Rebel, Fury и Challenge), оснащенными многоцилиндровыми двигателями, имеющими максимальное ускорение, но наименее эффективно расходующими топливо.
Интерпретация результатов кластеризации позволила нам прийти к более глубокому пониманию исходных данных.
Визуализация кластеров
На данном этапе данные можно разделить на 3 таблицы, и рассматривать каждую из них отдельно, исследуя скрытые тенденции в каждой из них. Можно создать графики, показывающие изменения Mpg и других переменных в каждом из 3 кластеров.
Полученные ранее кластеры мы переименовали в General, Economy и Muscle. Для этого мы использовали узел Производные колонки, который проверял значение в колонке Cluster Id и отображал имя кластера на основе ID в новой колонке. SRL-выражение для узла Производные колонки может быть создано на основе функций when или if:
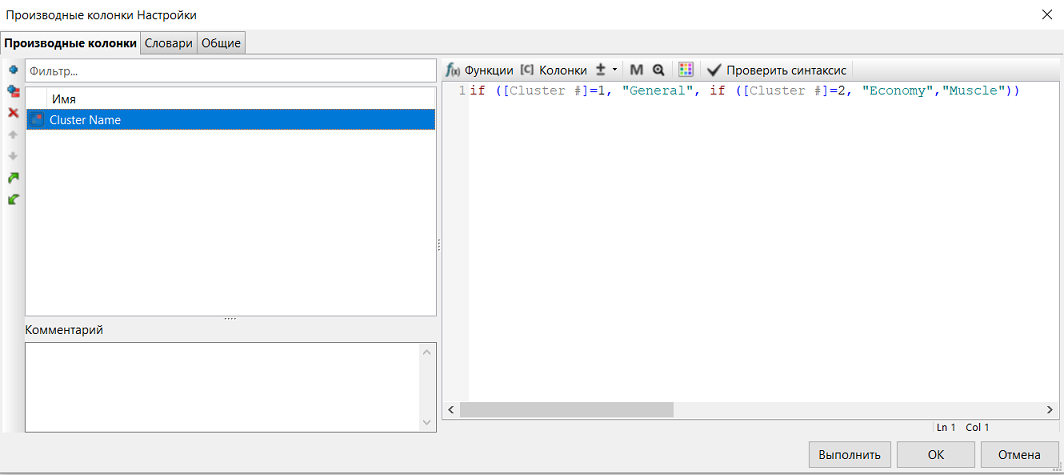
Данное выражение означает, что если ID кластера равен 1, ему присваивается имя "General", если ID кластера равен 2, ему присваивается имя "Economy", если не выполняется ни одно из двух условий, кластеру присваивается имя "Muscle".
Если вам пока еще сложно понять логику составления SRL-выражений для узла Производные колонки, вы можете использовать альтернативный способ переименования кластеров с помощью узла Замена категорий. Однако помните, что этому узлу на скрипте в нашем случае должен предшествовать узел Модификация колонок для того, чтобы преобразовать исходную колонку Cluster Id в колонку строкового типа, поскольку узел Производные колонки работает только со строковыми данными:
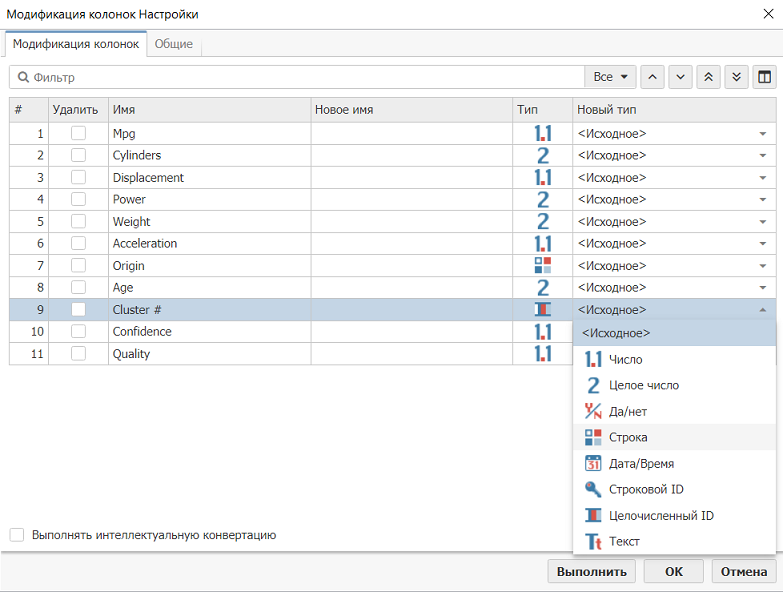
После того, как колонка будет преобразована, соедините узел Модификация колонок с узлом Замена категорий и настройте замены. Для того, чтобы это сделать,
-
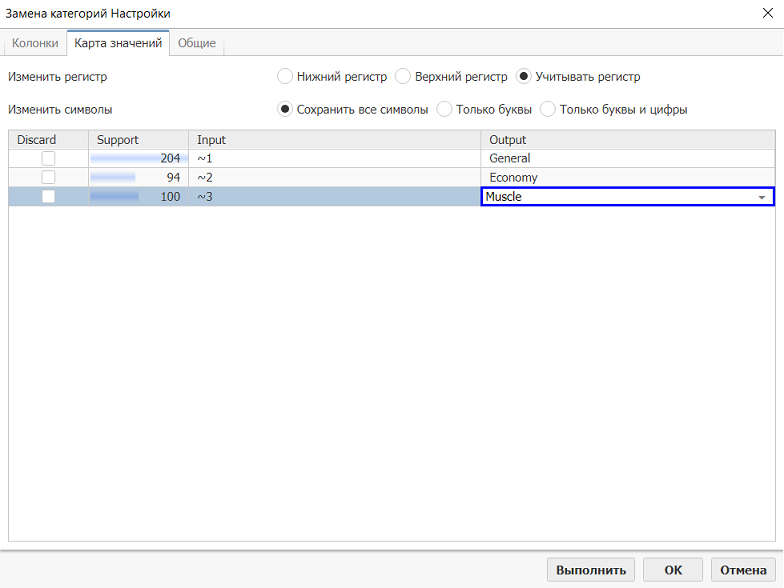
Выберите колонку Cluster Id на первой вкладке окна свойств узла Замена категорий.
-
Введите названия кластеров в соответствующих ячейках в колонке Outputs:
-
Выполните узел.
Узел создаст новую колонку (по умолчанию она будет называться Cluster Id_rep) с указанными вами именами кластеров.
После того, как были переименованы кластеры, мы создали узел Диаграмма рассеяния, соединили его с узлом Производные колонки и разположили значения Mpg, Power и Acceleration вдоль осей X, Y и Z соответственно:
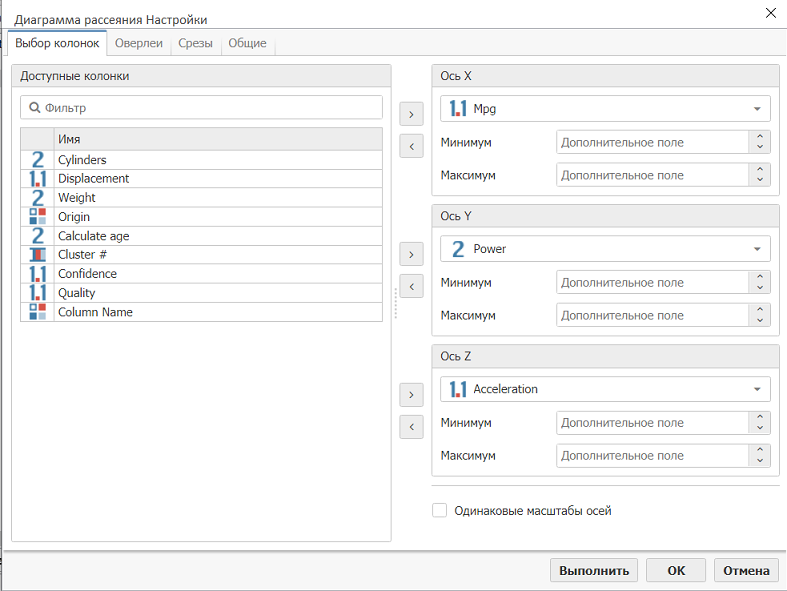
На следующей вкладке узла Диаграмма рассеяния мы выбрали колонку Cluster Name в качестве оверлея цвета, а колонку Origin - в качестве оверлея формы:
Более подробно настройка узла Диаграмма рассеяния описана в разделе, посвященном донному узлу.
Вам необязательно повторять эти действия и воспроизводить график, представленный ниже. Мы приводим его в данном руководстве только для того, чтобы показать пользователям возможности визуализации таблицы данных, записи которой были разбиты на кластеры.
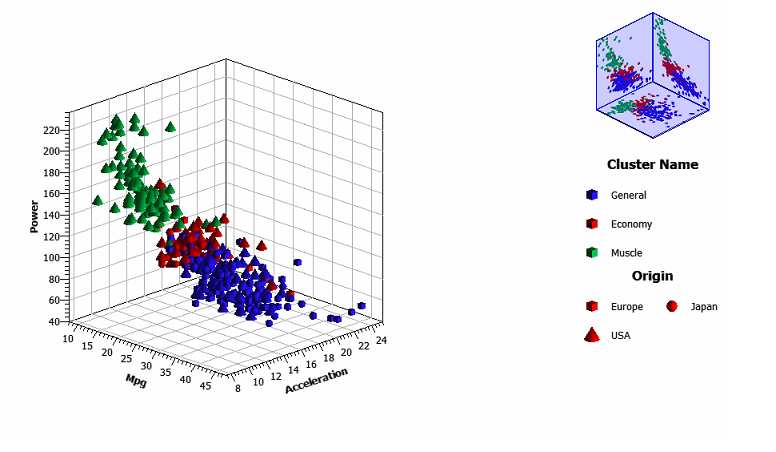
Вы можете выполнить детализацию отдельных точек графика, чтобы понять, почему они являются исключениями. У пользователя есть возможность с помощью специальных инструментов PolyAnalyst и SRL-выражений выделить эти точки данных в отдельную таблицу для дальнейшего анализа, или отфильтровать их и скрыть в последующих узлах. Можно использовать колонку с ID или именами кластеров в качестве целевого атрибута в модели дерева решений.
Результаты кластеризации дают нам достаточное начальное представление о классах автомобилей, с которыми мы работаем, а также о том, какие атрибуты позволяют отличить автомобили друг от друга, например, страна-производитель автомобилей, их возраст и количество цилиндров.