Настройка узла Распознавание речи
Окно настроек узла Распознавание речи содержит три вкладки: Выбок колонок, Настройки и Общие.
Опции вкладки Выбор колонок
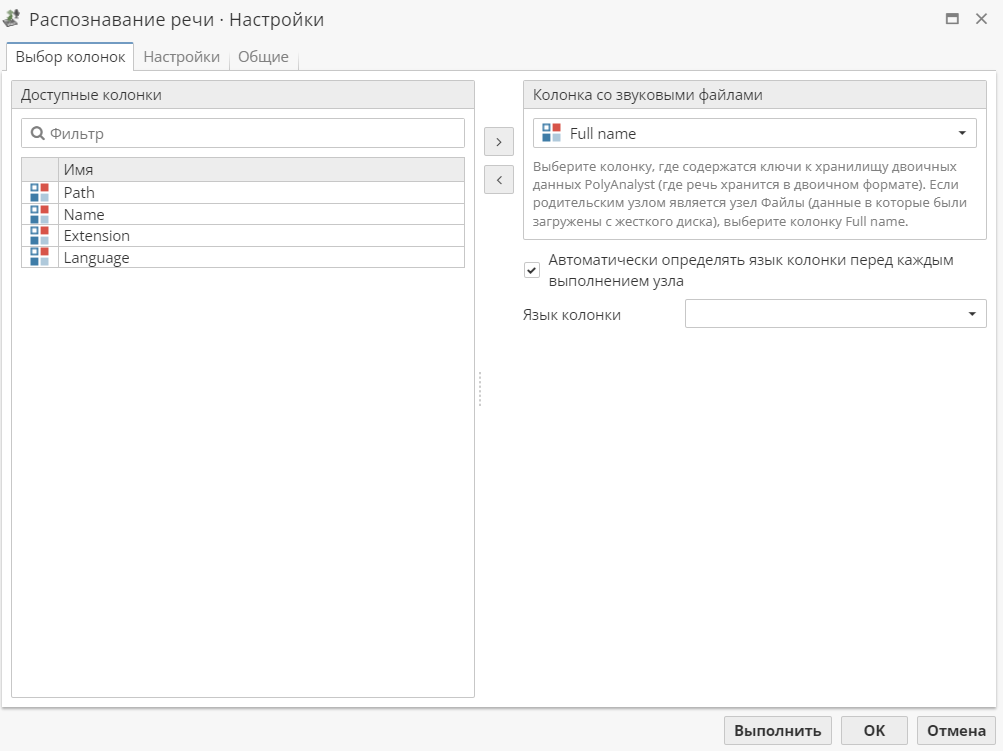
На первой вкладке выберите колонку, в которой содержатся ключи к бинарным данным. Для этого:
-
Выберите колонку в списке Доступные колонки и нажмите на кнопку с изображением стрелки, или
-
Нажмите дважды на имя колонки в списке Доступные колонки, или
-
Используйте выпадающее меню в разделе Колонка со звуковыми файлами.
| Если в качестве родительского узла выступает узел Файлы, необходимые ключи обычно хранятся в колонке Full name. Эта колонка выбираются автоматически в качестве Колонки со звуковыми файлами на вкладке Выбор колонок, что позволяет сразу выполнить узел, не открывая его настройки. |
По умолчанию включена опция Автоматически определять язык колонки перед каждым выполнением узла, которая позволяет узлу при анализе аудиозаписи автоматически подбирать соответствующий язык для каждого аудиофайла. Также пользователь может вручную указать язык, на котором записана аудиозапись в поле Язык колонки.
Опции вкладки Настройки
На вкладке Настройки имеется несколько опций настроек узла:
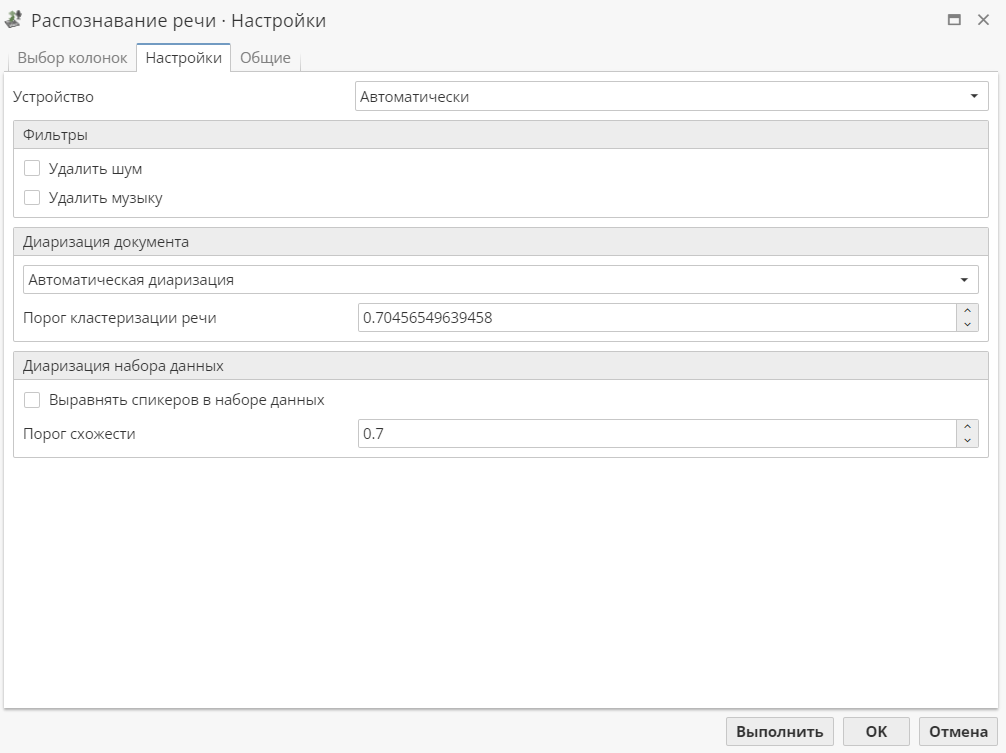
Устройство - позволяет выбрать тип устройства, которое будет использоваться при распознавании речи:
-
Автоматически - в качестве ресурса используется внешний сервис, если он доступен. В противном случае используется локальный компьютер, на котором запущен сервер PolyAnalyst.
-
Кластер (ГП) - в качестве ресурса используется внешний сервис. Для того чтобы узел работал в этом режиме, откройте Административный клиент, выберите Настройки сервера, найдите раздел Внешние хосты, затем при помощи кнопки Добавить (кнопка в виде знака "плюс" на боковой панели инструментов) создайте и настройте кластер.
-
Локально (ЦП) - в качестве ресурса используется локальный компьютер, на котором запущен сервер PolyAnalyst.
Для повышения качества распознавания речи в разделе Фильтры выберите соответствующий фильтр обработки данных:
-
Удалить шум - фильтр предназначен для удаления или снижения фоновых шумов, которые могут затруднять восприятие речи. Применение фильтра повышает точность распознавания, делая речь более четкой и менее подверженной воздействию фоновых звуков.
-
Удалить музыку - данный фильтр помогает определить и удалить музыкальные фрагменты в аудиозаписи, которые могут мешать распознаванию речевого контента. Удаление музыки из аудиоданных существенно улучшает качество распознавания речи, особенно в ситуациях, когда речь и музыка накладываются друг на друга.
Раздел Диаризация документа предназначен для идентификации различных участников (говорящих) в аудиозаписи, что особенно важно при обработке записей, где несколько участников. В выпадающем меню выберите необходимый режим диаризации:
-
Отключить диаризацию - процесс распознавания речи не определяет отдельных участников, вся информация обрабатывается как единое целое.
-
Автоматическая диаризация - режим автоматически определяет, когда начинается и заканчивается речь каждого участника, основываясь на анализе звука. Задайте для этого режима Порог кластеризации речи - уровень чувствительности алгоритма к определению начала и конца речи различных участников.
-
Ручная диаризация - в этом режиме пользователь может самостоятельно сегментировать запись, например, когда автоматическая диаризация дает недостаточно точные результаты или в случае сложных диалогов. Пользователь имеет контроль над процессом и может исправлять ошибки. Для этого в соответствующих полях укажите минимальное количество участников, ожидаемое количество участников, максимальное количество участников.
Раздел Диаризация набора данных позволяет работать с большими объемами аудиофайлов, в которых необходимо определить, кто говорит в каждой части аудиозаписи.
-
Выравнять спикеров в наборе данных опция помогает стандартизировать диаризацию для всех записей в наборе данных, обеспечивая согласованность идентификации участников, что может быть применено для устранения различий в распознавании между разными записями.
-
Порог схожести - данный параметр определяет, насколько похожими должны быть характеристики звука, чтобы отнести две записи к одному и тому же участнику. Настройте этот порог, чтобы контролировать, насколько строго алгоритм будет воспринимать разные записи одного и того же говорящего.