Настройка узла Уникальные записи
Окно свойств узла Уникальные записи содержит две вкладки:
-
Колонки – здесь задается ключ для сравнения записей;
-
Общие – позволяет задать имя и описание узла. Данная вкладка встречается в нескольких узлах PolyAnalyst.
Задание ключа сравнения
Список слева на вкладке Колонки содержит все доступные колонки из входной таблицы данных, которые можно использовать в качестве ключа. Список справа содержит уже выбранные колонки.
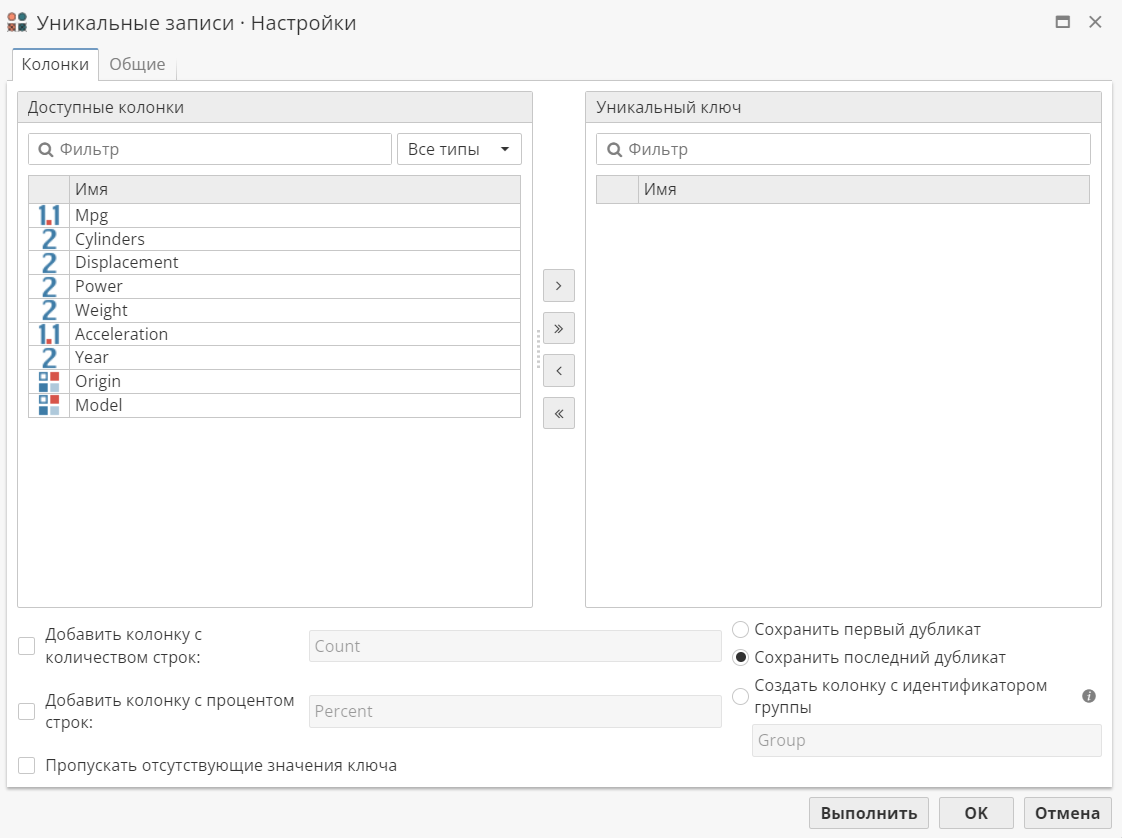
Чтобы выбрать колонку в качестве уникального ключа, переместите ее из списка доступных колонок, выбрав ее и нажав на кнопку >. После этого колонка будет недоступна для повторного выбора.
Если вы имеете дело с большим количеством колонок, используйте поле Фильтр над списком доступных колонок для того, чтобы выполнить поиск по именам колонок. Сортировать колонки можно также по типу данных или по алфавиту, по возрастанию или по убыванию.
Порядок выбранных колонок не влияет на логику работы узла.
Для того, чтобы выполнить узел, необходимо выбрать хотя бы одну колонку в качестве ключа.
Счетчик строк
При желании вы можете добавить к выходной таблице новую колонку, которая будет отображать количество идентичных записей, обнаруженных в исходной таблице, для каждой выходной записи. Например, если две исходные записи содержат один и тот же ключ, только одна из них будет включена в выход узла, и для нее будет указано количество идентичных записей – 2.
Для того, чтобы использовать этот функционал, отметьте галочкой опцию Добавить колонку с количеством строк под списком доступных колонок. По желанию можно задать имя новой колонки (по умолчанию колонке будет присвоено имя Count).
Наряду с количеством строк пользователь может добавить в выходную таблицу узла колонку, в которой будет отображаться процентное отношение идентичных записей, отвечающих условию колонки-ключа. Для этого отметьте галочкой опцию Добавить колонку с процентом строк.
Счетчик групп
Каждый раз, когда узел Уникальные записи находит две записи, соответствующие ключу, эти записи объединяются в группу. Каждая новая группа получает уникальный идентификатор, который по сути является порядковым номером группы. Например, первая группа будет обозначена номером 1, вторая – номером 2 и т.д.
Отметьте галочкой опцию Создать колонку с идентификатором группы, чтобы добавить колонку с идентификатором группы в выходную таблицу.
Пропуск отсутствующих значений ключа
Используйте опцию Пропускать отсутствующие значения ключа, чтобы исключать записи, в которых любая из колонок ключа не содержит значений. Не отмечайте эту опцию, если хотите, чтобы отсутствующие значения рассматривались как уникальные значения.
Например, сравнивая 100 записей с ключом из одной колонки, когда во всех записях в колонке ключа значения отсутствуют, и опция не подключена, узел Уникальные записи будет считать записи повторяющимися, и исключит 99 записей. Если опция подключена, ни одна запись не будет считаться дубликатом другой, но все 100 записей будут исключены, поскольку ни одна не содержит значения ключа. Это практически аналогично использованию узла Фильтрация строк непосредственно перед узлом Уникальные записи. Он фильтрует записи, которые не содержат значений для одной или нескольких колонок ключа.
Выбор одной из похожих записей для включения в выходную таблицу
Узел Уникальные записи обрабатывает записи из входной таблицы последовательно, начиная с первой. Когда обнаруживаются неуникальные (дублирующиеся) записи, узел должен выбрать, какую из нескольких повторяющихся записей включить в выходную таблицу. Выберите опцию Сохранить первый дубликат, если хотите, чтобы узел сохранил первую из дублирующихся записей на выходе. Либо используйте опцию Сохранить последний дубликат, для того, чтобы узел выбрал последнюю из найденных дублирующихся записей.
| Не следует связывать логику аналитического процесса с порядком записей в исходной таблице данных. Часто записи сортируются совершенно не так, как того ожидает пользователь. Если вы хотите иметь гарантию того, что записи будут распределены в нужном порядке, рекомендуется использовать узел Сортировка строк непосредственно перед узлом Уникальные записи, чтобы удалить повторяющиеся записи. На самом деле, необходимость использования узла Сортировка строк отпадает только в двух случаях: во-первых, если порядок записей не имеет значения (не важно, какие из повторяющихся записей будут сохранены), а во-вторых, если вы хотите сэкономить время в условиях реального аналитического проекта. |