Настройка узла Обогащение данных
Выполняя настройку узла Обогащение данных, пользователь, по сути, задает условия поиска похожих строк во входной таблице и выполнения операций слияния и обогащения. Окно настроек узла Обогащение данных содержит 3 вкладки: Поиск строк-дубликатов, Слияние и обогащение и Общие.
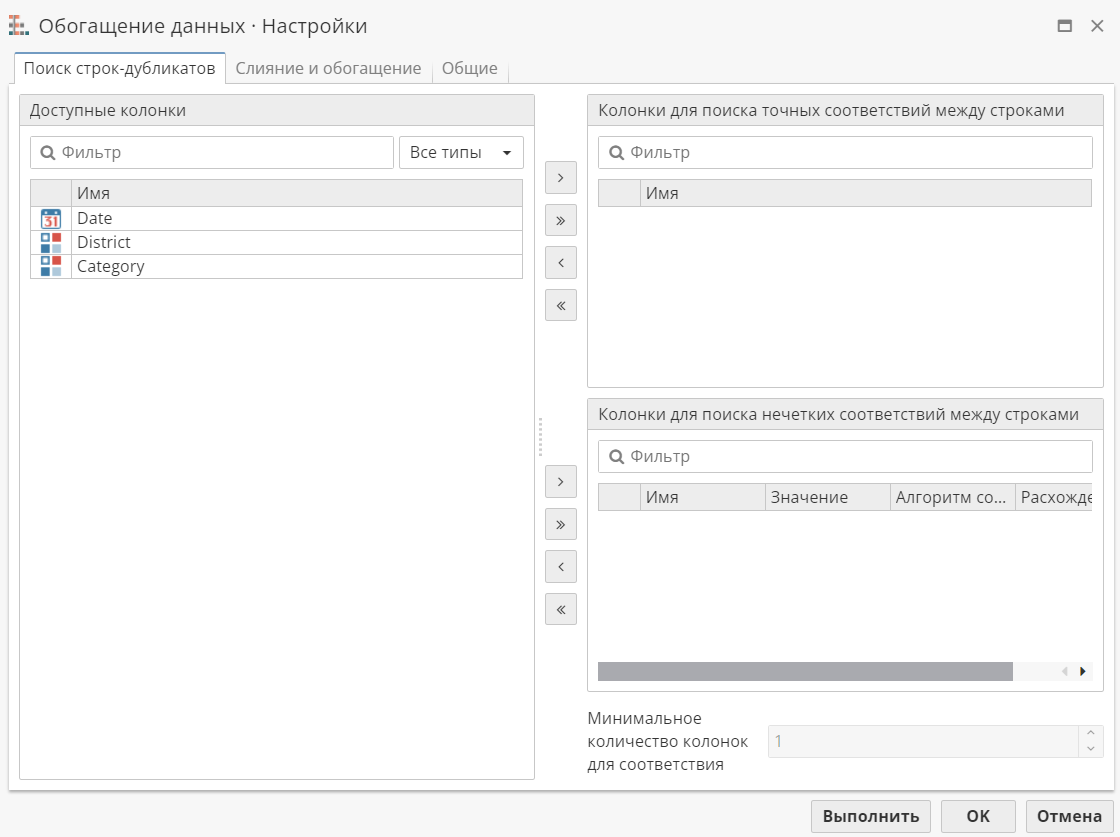
Настройка вкладки Поиск строк-дубликатов
На вкладке Поиск строк-дубликатов имеются три поля. Поле слева содержит список доступных колонок из входной таблицы данных. В верхнее поле справа – Колонки для поиска точных соответствий между строками – можно переместить колонки, по значениям которых определяются точные соответствия между строками. Нижнее поле справа – Колонки для поиска нечетких соответствий между строками – позволяет пользователю настроить процесс поиска нечетких соответствий между строковыми значениями.
Используйте стрелки >, >>, < и << для того, чтобы переместить колонки из списка доступных колонок в верхний и нижний списки справа, и, если понадобится, вернуть выбранные колонки в исходный список.
При настройке поиска нечетких соответствий пользователи могут указать значение (тип данных выбранной колонки), выбрать Алгоритм сопоставления и допустимую степень расхождения для выбранных колонок с помощью одноименных полей.
Выпадающее меню Значение позволяет указать тип данных, который используется для поиска нечетких соответствий.
Меню Алгоритм сопоставления предлагает выбор между Расстоянием Левенштейна и Хешированием по сигнатуре. Первый из них – широко применяемая и хорошо описанная метрика, измеряющая разность между двумя последовательностями символов. Хеширование по сигнатуре – относительно новый алгоритм поиска нечетких соответствий, который преобразует строковое значение в каноническую форму следующим образом:
-
все символы приводятся к нижнему регистру и удаляются буквы a, e, i, o, u, y;
-
получившаяся строка упорядочивается по буквам и удаляются дубликаты букв.
Строки считаются равными, если у них одинаковый канонический вид. Обратите внимание на то, что данный алгоритм предназначен только для латинского алфавита.
В поле Расхождение пользователи могут ввести значение от 0 до 1 (по умолчанию используется значение 0,25). Данная настройка управляет тем, насколько сравниваемые записи могут отличаться, чтобы считать их подобными. Чем меньше расхождение, тем больше подобных записей будет сгруппировано вместе.
На этой же вкладке можно установить Минимальное количество колонок для соответствия, которое определяет, сколько соответствующих значений должны иметь записи, чтобы считаться подобными.
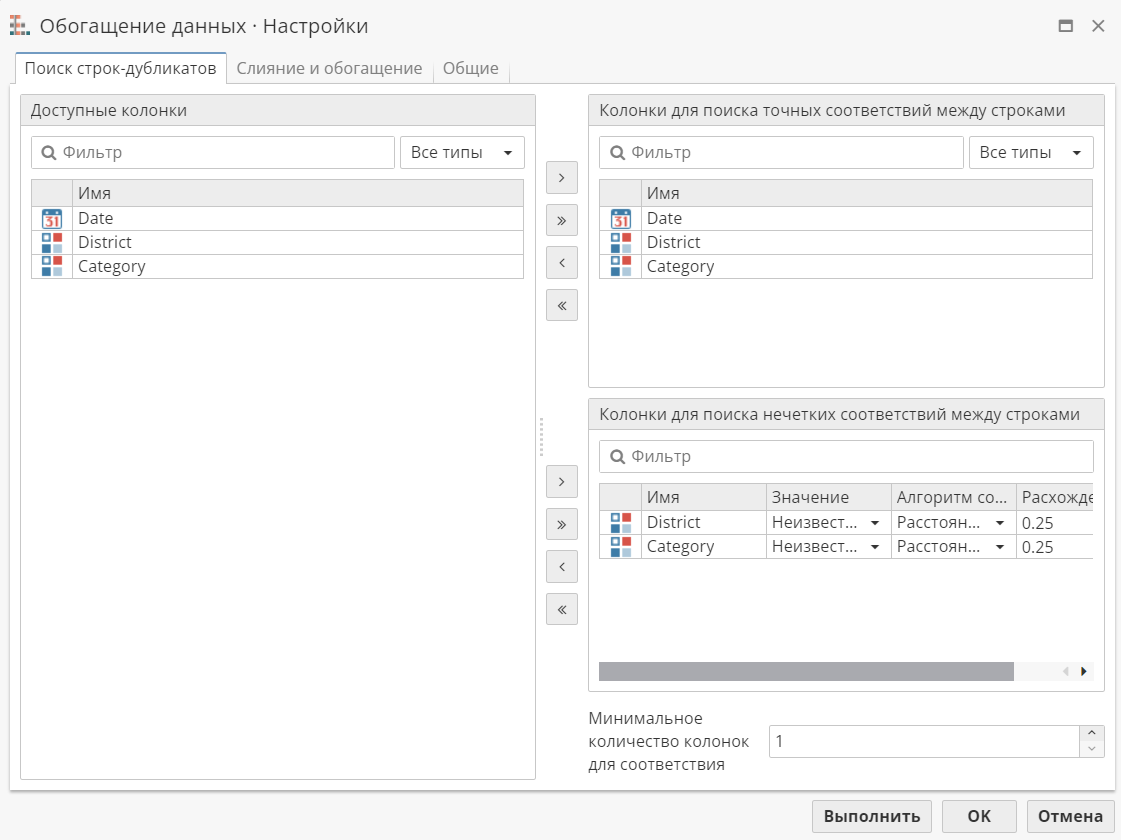
Настройка вкладки Слияние и обогащение
Эта вкладка позволяет указать колонки, значения которых будут сливаться. Процесс слияния-обогащения применяется к группам подобных строк, которые будут обнаружены во время выполнения узла согласно настройке предыдущей вкладки.
| Обратите внимание на то, что колонки для слияния-обогащения не должны совпадать с колонками для поиска точных соответствий. В противном случае PolyAnalyst выдаст сообщение об ошибке, и узел не сможет быть выполнен. |
Настройка вкладки Общие
Вкладка Общие позволяет указать название и описание узла и присутствует в настройках большинства узлов PolyAnalyst.