Настройка узла Фильтрация данных
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Настройка вкладки Выбор колонок
Исходные колонки настраиваются на вкладке Выбор колонок. Узел Фильтрация данных принимает на входе любое количество исходных атрибутов с данными любого типа. Выберите одну или несколько колонок из списка Доступные колонки и переместите их в список Выбранные колонки. Чтобы выполнить узел, необходимо выбрать хотя бы одну колонку. Дополнительная информация по настройке этой вкладки изложена в вводном разделе по выбору колонок при настройке узлов.
Настройка вкладки Настройки
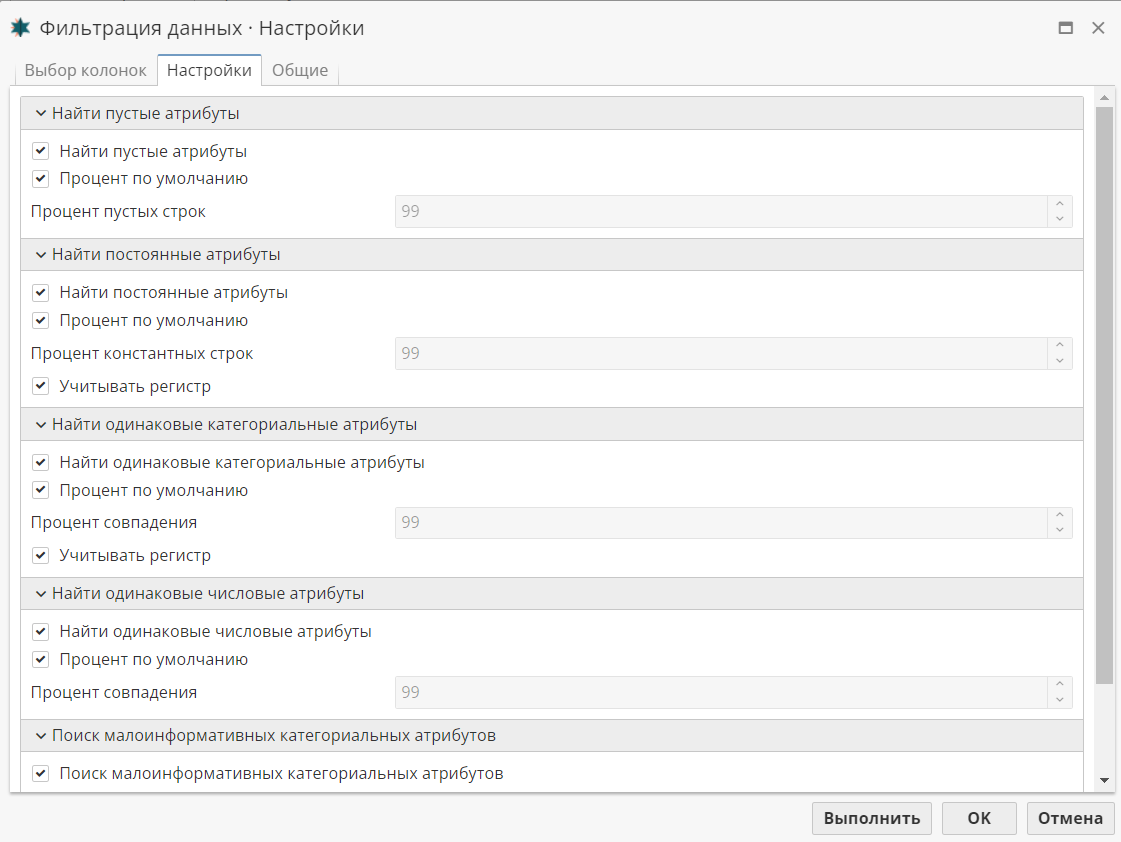
На вкладке Настройки перечислены различные типы поиска, которые должны быть выполнены узлом Фильтрация данных. Как правило, все опции по умолчанию включены, то есть предполагается выполнение всех типов поиска. Вы можете отключить конкретные поисковые опции, чтобы узел выполнял ограниченный поиск. Некоторые опции также включают дополнительные параметры на основе процентного соотношения строк (например, колонка считается пустой, если 99% ее значений отсутствуют). Вы можете изменить это процентное соотношение с целью оптимизации результатов, либо использовать настройки по умолчанию.
Обычно производительность данного узла увеличивается после отключения отдельных опций поиска. Однако следует отметить, что по сравнению со многими другими узлами в PolyAnalyst, данный узел и без того отличается достаточно высокой производительностью. Решение о том, какие типы поиска выполнять, рекомендуется принимать на основе того, какой результат вы надеетесь получить, а не руководствоваться в этом вопросе стремлением повысить производительность узла.
Чтобы найти и удалить пустые колонки, включите опцию Найти пустые атрибуты. Как правило, пустые колонки никак не помогают в анализе данных и их можно удалить. Колонка считается пустой, если количество строк с отсутствующими значениями превышает установленный порог. Чтобы изменить порог, отключите опцию Процент по умолчанию и введите новое значение.
Чтобы найти и удалить колонки с константными (постоянными) значениями, включите опцию Найти постоянные атрибуты. Постоянные атрибуты — это те колонки, которые в каждой записи (или почти в каждой записи) содержат одно и то же значение. Как правило, постоянные значения не представляют какой-либо ценности в ходе анализа данных, поэтому их можно удалить. Колонка считается константной, если наиболее часто повторяющееся значение в колонке, в процентном выражении от общего числа исходных записей, больше указанного порогового значения.
Чтобы найти и удалить идентичные категориальные (то есть строковые и булевые) атрибуты, включите опцию Найти одинаковые категориальные атрибуты. Любые два атрибута среди всех исходных колонок считаются одинаковыми, если большой процент их значений совпадает. Узел определяет, сколько раз в каждой из двух сравниваемых колонок встречаются одинаковые значения. Другими словами, колонки с одним и тем же значением в 100% записей полностью дублируют друг друга и являются избыточными. Следовательно, целесообразно исключить такие "дублирующиеся" колонки из таблицы прежде, чем продолжать анализ данных. Совпадение категориальных колонок проверяется с точностью до переименования, то есть, к примеру, если имеем колонки A = (a, a, b), B = (c, c, d), C = (x, y, z), то совпадение между A и B будет 100%, а между A и C — 66%.
Чтобы найти и удалить идентичные числовые (то есть целые и с плавающей точкой) атрибуты, включите опцию Найти одинаковые числовые атрибуты. Совпадение двух числовых колонок проверяется по их среднеквадратичному отклонению друг от друга после центрирования и нормировки каждой колонки.
Можно также выполнить поиск малоинформативных категориальных атрибутов, включив опцию Поиск малоинформативных категориальных атрибутов. Категориальный атрибут считается малоинформативным, если почти каждая строка исходной таблицы содержит уникальное значение. Обычно инструменты статистического моделирования извлекают пользу из избыточных данных и присутствия повторяющихся значений в записях, поскольку это способствует выявлению шаблонов и трендов в данных. Колонки, которые почти не содержат повторов, не подходят для анализа данных, поскольку никакой алгоритм не сумеет выявить тренды в таких данных. Коэффициент уникальности равен отношению количества строк с уникальными значениями к числу записей. Если это число больше, чем указанное пороговое значение в процентах, то колонка считается малоинформативной. Чтобы отредактировать пороговое значение, отключите опцию Процент уникальных строк.
В настройках многих алгоритмов есть флаг Учитывать регистр. Он определяет, учитывать ли регистр символов в строковых колонках при ответе на вопрос, равны ли между собой два значения.