Достоверность правил и разрешение конфликтов
Если несколько правил находят пересекающиеся результаты, XPDL разрешает конфликты в соответствии со следующими правилами:
1) Если один результат полностью содержится в другом, возвращается только самый полный из них.
Пример
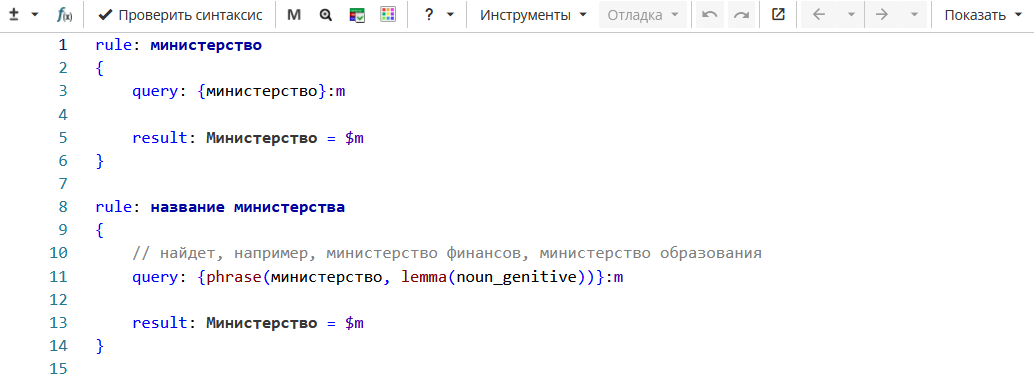
На Изображении 1 первое правило находит слова «министерство», а второе - названия министерств, состоящие из слова «министерство», за которым следует существительное в родительном падеже (например, «министерство промышленности»).
Фрагмент правила
rule: министерство
{
query: {министерство}:m
result: Министерство = $m
}
rule: название_министерства
{
// найдет, например, министерство финансов, министерство образования
query: {phrase(министерство, lemma (noun_genitive))}:m
result: Министерство = $m
}В тексте

первое правило находит результат «министерства», а второе правило - результат «Министерства просвещения». Результат «министерства» отбрасывается, потому что полностью входит в более длинный результат «Министерства просвещения». Как показано на Изображении 2, правила возвращают только результат «Министерства просвещения».

2) Если несколько правил извлекают частично пересекающиеся результаты, сохраняются оба результата.
Пример
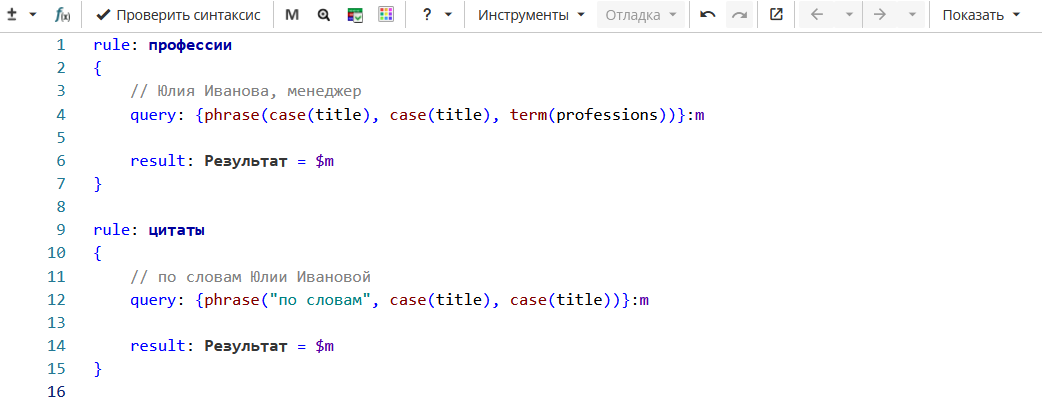
На Изображении 3 приведены правила для поиска имен людей по контексту. Правило «профессии» находит два слова с большой буквы, после которых следует название профессии из класса слов «professions» (например, «Владислав Антонов, аналитик»). Правило «цитаты» находит два слова с большой буквы после выражения «по словам» (например, «по словам Владислава Антонова»).
Фрагмент правила
rule: профессии
{
// Юлия Иванова, менеджер
query: {phrase(case(title), case(title), term(professions))}:m
result: Результат = $m
}
rule: цитаты
{
// по словам Юлии Ивановой
query: {phrase("по словам", case(title), case(title))}:m
result: Результат = $m
}В тексте:

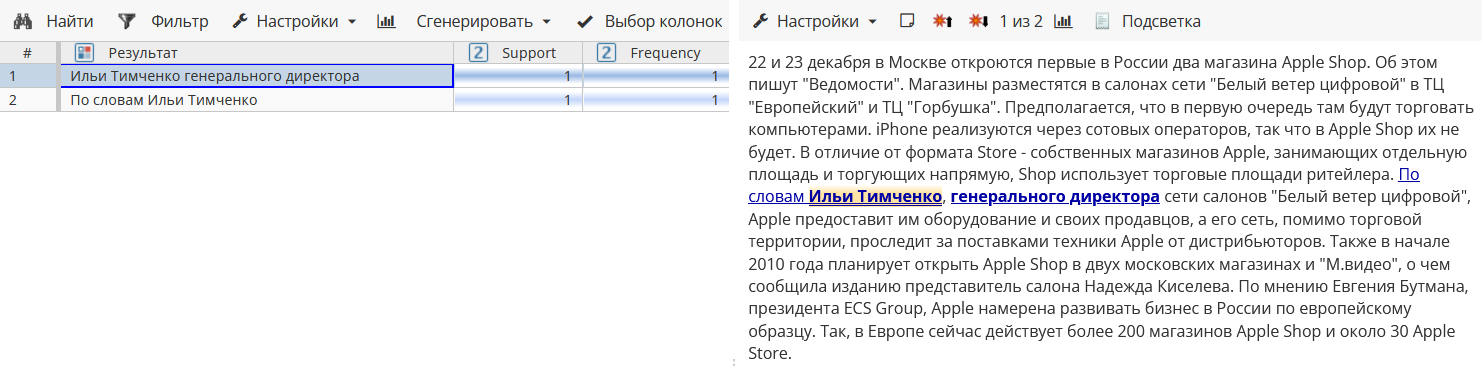
первое правило находит результат «Ильи Тимченко, генерального директора», который частично пересекается с найденным вторым правилом результатом «по словам Ильи Тимченко». Как видно на Изображении 4, правила возвращают оба результата.
3) Если несколько правил извлекают одну и ту же фразу, правило с наибольшим значением достоверности (confidence) является предпочтительным. Раздел confidence не является обязательным.
Синтаксис
Значение достоверности используется для установления приоритетности правил в случае, когда несколько правил извлекают одну и ту же последовательность. Значение достоверности по умолчанию равно 1. Если значение достоверности не указано, правило наследует значение достоверности от своего родительского правила.
Значение достоверности НЕ рассчитывается статистически. Оно устанавливается автором правила вручную и отражает субъективную оценку способности правила извлекать корректные результаты.
Если несколько правил имеют одинаковое значение достоверности, программа выбирает правило, которое выводит больше атрибутов. Если количество атрибутов одинаково — правило, объявленное первым.
Пример
На Изображении 5 приведены правила для поиска авиарейсов. Правило «рейсы» находит слово рейс, за которым следуют два географических названия (например, «рейс Москва-Прага»). Правило также выводит атрибуты «Пункт отправления» и «Пункт назначения» в отдельные колонки. Правило «рейсы_копия» является копией правила «рейсы», но не заполняет атрибуты.
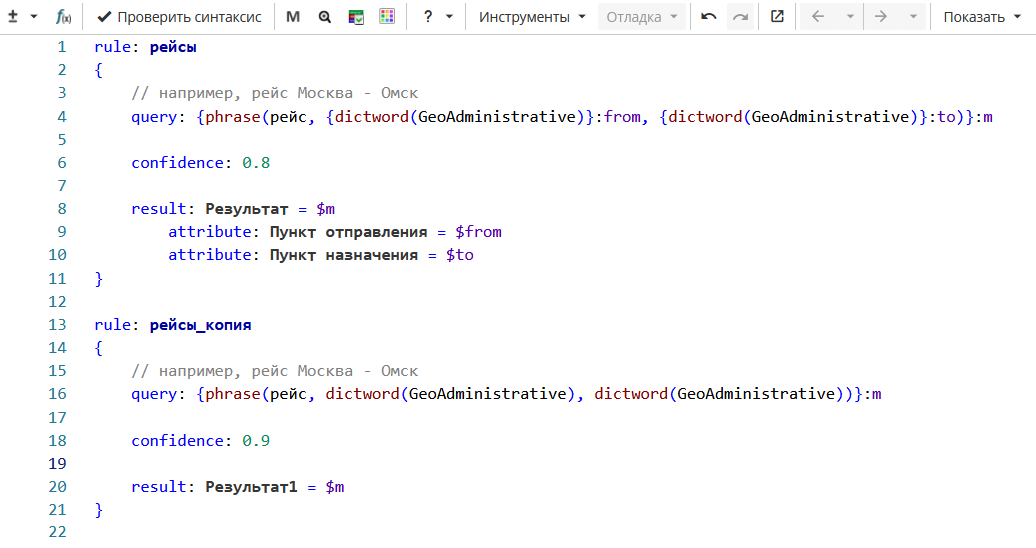
Фрагмент правила
rule: рейсы
{
// например, рейс Москва - Омск
query: {phrase(рейс, {dictword(GeoAdministrative)}:from, {dictword(GeoAdministrative)}:to)}:m
confidence: 0.9
result: Результат = $m
attribute: Пункт отправления = $from
attribute: Пункт назначения = $to
}
rule: рейсы_копия
{
// например, рейс Москва - Омск
query: {phrase(рейс, dictword(GeoAdministrative), dictword(GeoAdministrative))}:m
confidence: 0.9
result: Результат1 = $m
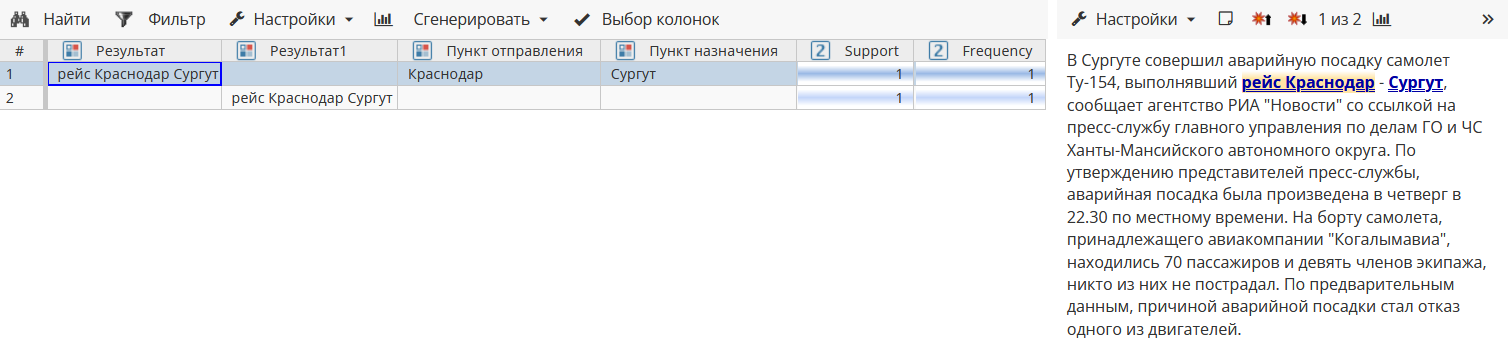
}В тексте

оба правила извлекают фразу «рейс Краснодар - Сургут». Однако результат правила «рейсы_копия» является приоритетным из-за более высокой достоверности правила (0.9), поэтому колонки «Пункт отправления» и «Пункт назначения» остаются пустыми, как показано на Изображении 6.

Если бы достоверность правила «рейсы» была выше или равна достоверности правила «рейсы_копия», то колонки «Пункт отправления» и «Пункт назначения» были бы заполнены, как показано на Изображении 7.

4) Если правила извлекают совпадающие результаты под разными именами, сохраняются оба результата.
Пример
Правила для поиска авиарейсов на Изображении 8 почти идентичны правилам на Изображении 5, но теперь у правил совпадает значение достоверности, а результаты выводятся в колонки «Результат» и «Результат1».
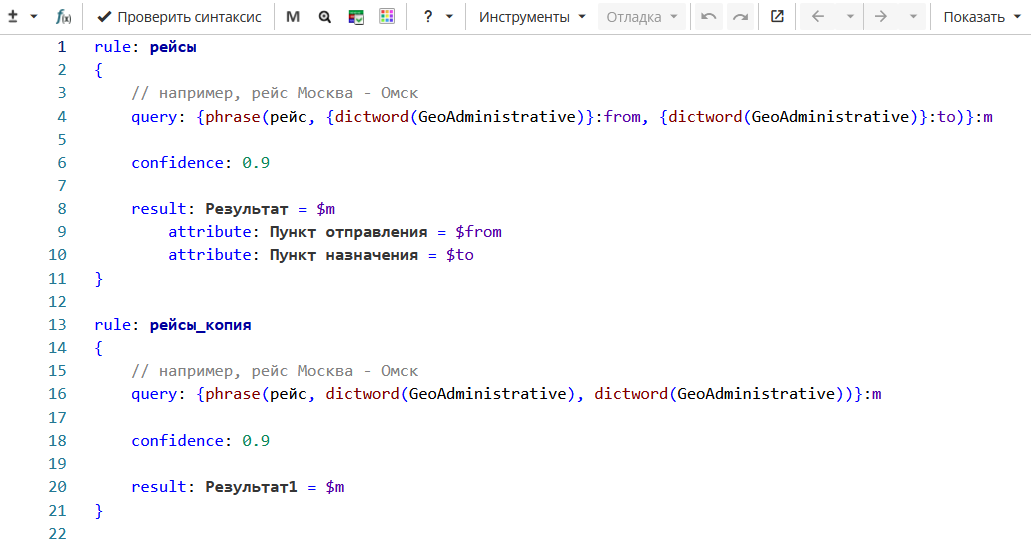
В тексте
оба правила находят один и тот же результат «рейс Краснодар - Сургут». Но так как у результатов разные имена, они оба сохраняются, как показано на Изображении 9.