Типы правил
В дополнение к стандартным правилам язык XPDL имеет два специализированных типа правил: фильтрующее правило и исключающее правило. Они служат для сужения поиска, когда правило верхнего уровня слишком широкое и извлекает ненужные паттерны.
Рассмотрим задачу извлечения имен людей. Правило на Изображении 1 использует простой подход к этой задаче: извлекает слова из словаря имен людей, за которым следует слово с заглавной буквы (предположительно, фамилия человека).

Фрагмент правила
rule: dict_people
{
query: {phrase(0, dictword(HumanNames, "type=first name"),
case(title, lemma(noun|adjective)))}:mention
result: Match = $mention
}Правило отрабатывает на следующих текстах:

Примеры имен, которые находит это правило, приведены на Изображении 2:

Среди результатов есть и некорректные вхождения (например, название компании, в котором фигурирует имя): «Евгений Герасимов и партнеры».
Чтобы исключить некорректные результаты, можно использовать вложенное правило, как показно на Изображении 3:

Фрагмент правила
rule: dict_people
{
query: {phrase(0, dictword(HumanNames, "type=first name"), case(title, lemma(noun|adjective)))}:name
rule: exceptions
{
query: {phrase(0, $name, not([и партнеры]))}:name1
result: Match = $name1
}
}Вложенное правило «exceptions» извлекает фразы, хранящиеся в именованной группе «name», если за ними не следуют слова «и партнеры». Правило объявляет новую именованную группу «name1» для хранения результатов, которые соответствуют этому ограничению. Новая именованная группа необходима, поскольку стандартные правила не могут изменять содержимое ранее объявленных именованных групп.

С помощью исключающего или фильтрующего правила можно решить эту задачу более компактным способом. В частности, нам не понадобится создавать именованную группу "name1".
Исключающее правило начинается с ключевого слова rule_except и описывает конструкции, которые нужно исключить из дальнейшей обработки. В нашем примере нужно убрать из группы «name» фразы, за которыми следуют слова «и партнеры». Тогда запрос будет выглядеть так, как показано на Изображении 5.
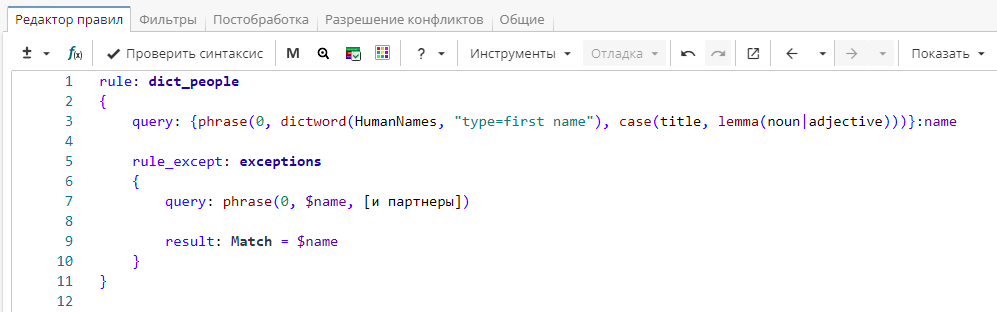
Фрагмент правила
rule: dict_people
{
query: {phrase(0, dictword(HumanNames, "type=first name"), case(title, lemma(noun|adjective)))}:name
rule_except: exceptions
{
query: phrase(0, $name, [и партнеры])
result: Match = $name
}
}После отработки исключающего правила из именованной группы "name" будут удалены фразы, за которыми следует «и партнеры».
На Изображении 6 показана пошаговая работа правила.
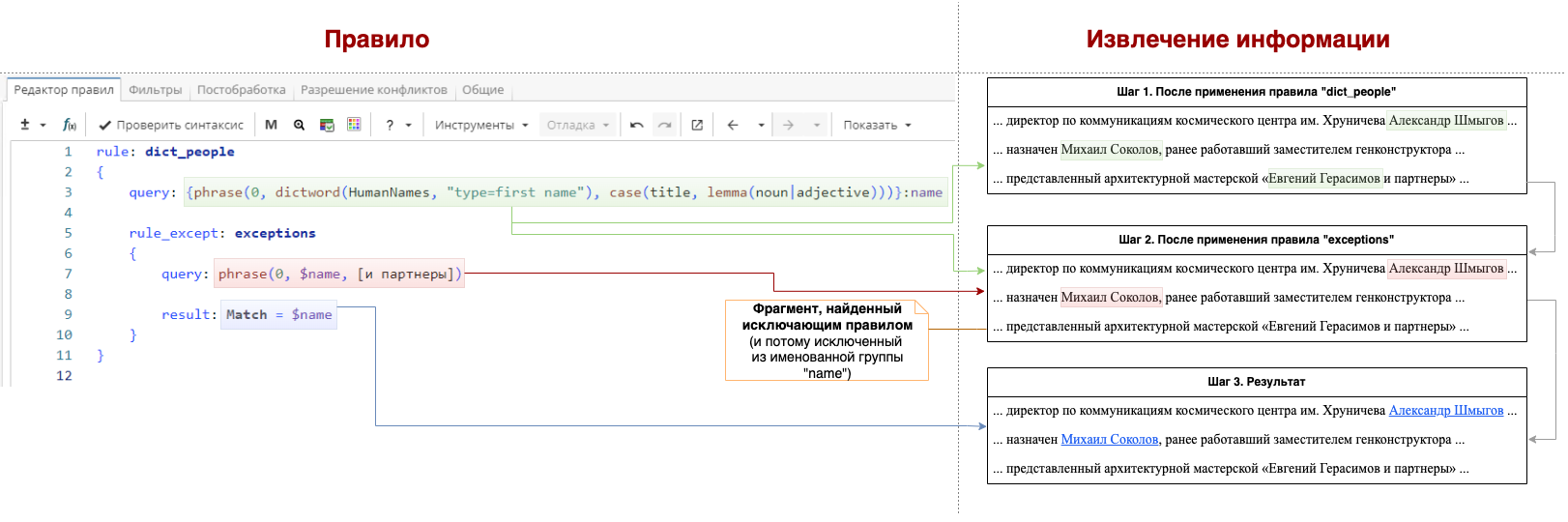
Теперь рассмотрим, как эта же задача может быть решена с использованием фильтрующего правила. Фильтрующее правило противоположно исключающему правилу: оно описывает конструкции, которые нужно сохранить для дальнейшей обработки. В нашем примере мы хотели бы сохранить в группе «name» только те фразы, за которыми НЕ следуют слова «и партнеры». Тогда запрос будет выглядеть так, как показано Изображении 7. Фильтрующее правило начинается с ключевого слова rule_filter:
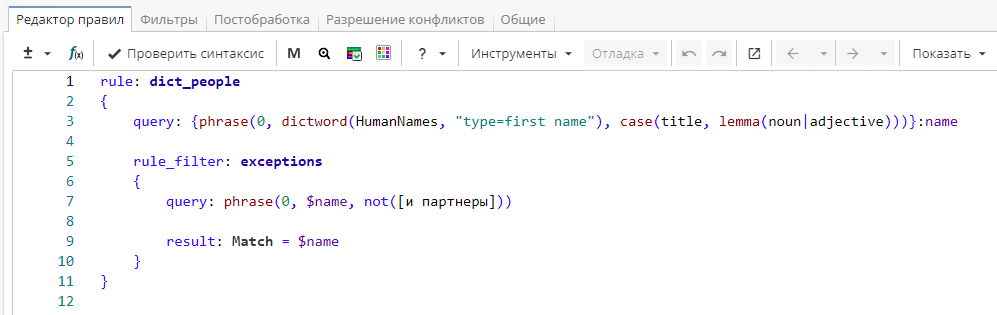
Фрагмент правила
rule: dict_people
{
query: {phrase(0, dictword(HumanNames, "type=first name"), case(title, lemma(noun|adjective)))}:name
rule_filter: exceptions
{
query: phrase(0, $name, not ([и партнеры]))
result: Match = $name
}
}После отработки фильтрующего правила из именованной группы "name" будут удалены фразы, за которыми следует «и партнеры».
На Изображении 8 показана пошаговая работа правила.
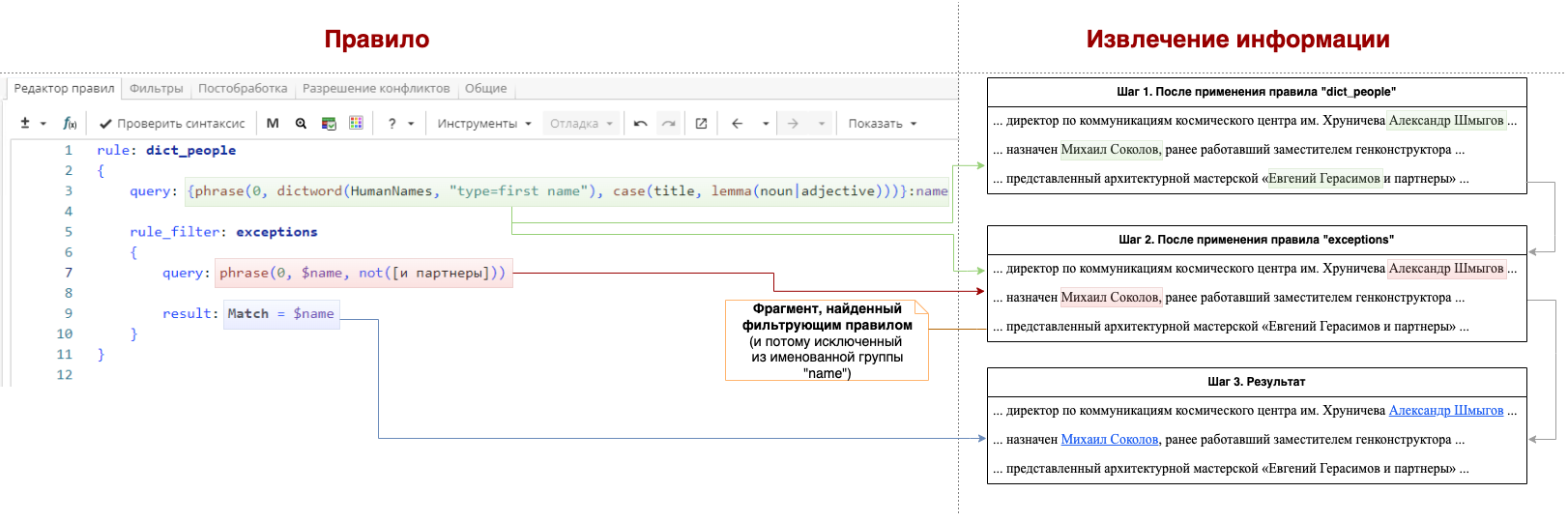
Правила на Изображении 5 и на Изображении 7 приводят к одинаковому результату: в именованной группе "name" остаются только те фразы, за которыми не следует "и партнеры".
Фильтрующее и исключающее правила часто взаимозаменяемы. Если удобнее описать конструкции, которые следует сохранить для дальнейшей обработки, следует использовать фильтрующее правило. Если проще описать конструкции, которые следует исключить, следует использовать исключающее правило.
Стандартные и специализированные правила демонстрируют два разных подхода к извлечению паттернов. Первый подход заключается в извлечении основных элементов, а затем в постепенном расширении поиска для получения более полного вхождения («Бюро» → «Федеральное бюро» → «Федеральное бюро расследований»). Стандартные правила следуют этой логике.
Однако иногда требуется другой подход, поскольку может быть проще написать общее правило верхнего уровня, а затем постепенно отфильтровывать ненужные вхождения. В этом случае используются специальные правила, хотя фильтрация также может быть выполнена и с использованием стандартных правил, как было показано на примере на Изображении 3.
Выбор подхода зависит от задачи. Обычно иерархии правил включают в себя как стандартные, так и специализированные правила.