Разделы для продвинутых пользователей
В этом разделе рассматриваются более сложные функции XPDL.
Правила без именованных групп
Правило, которое не объявляет именованные группы, действует как фильтр на уровне документа, то есть его вложенные правила вызываются, только если документ удовлетворяет родительскому правилу (см. пример ниже).
Пример
Правило на Изображении 1 извлекает все конструкции «предлог + слово «дача» в одной из форм».

Фрагмент правила
rule: Dacha
{
// ищется предложение со словом "дача" с предлогом
query: {phrase(0, partofspeech(preposition), "дача")}:m
result: Match = $m
}Это правило извлекает документы, содержащие фразы «На дачах и огородах нужно убирать сухостой», «сезонное использование под дачи», «предстать перед судом для дачи показаний» и т.д. Чтобы исключить юридические контексты («дача взятки», «дача показаний»), можно написать правило верхнего уровня, которое будет исключать такие вхождения.

Фрагмент правила
rule: exclude_law
{
// исключается юридический контекст
query: not orn(ложный, взятка, показание)
rule: dacha
{
// ищется предложение со словом "дача" с предлогом
query: {phrase(0, partofspeech(preposition), "дача")}:m
result: Match = $m
}
}Несколько групп с одинаковым именем
XPDL допускает несколько групп с одним и тем же именем в одном запросе. Это позволяет хранить разрывные вхождения.
Пример
В этом случае все группы с одинаковым именем становятся единым целым: паттерны, извлекаемые этими группами, объединяются в одно вхождение. Например, в приведенном выше примере «$1» включает «a» и «c».
Эта функциональность может быть полезна для исключения незначимых позиций (см. пример ниже).
Пример
Рассмотрим правило с запросом, извлекающим стандартное написание адреса.

Фрагмент правила
rule: addresses
{
// поиск адресов стандартного вида
query: {phrase(2, lemma("улица" or [ул.]), case(title), lemma("дом" or [д.]), char(numeral), lemma("квартира" or [кв.]), char(numeral))}:m
result: Match = $m
}Это правило находит, например «ул. Добролюбова, д. 10, кв. 11», «ул. Садовая, д. 29, кв. 8».
В следующем варианте правила нескольким элементам (название улицы, номер дома и номер квартиры) присвоено одно и то же имя — тогда в результат не попадают незначимые слова («дом», «квартира»).

Фрагмент правила
rule: addresses
{
// поиск адресов стандартного вида
query: phrase(2, lemma("улица" or [ул.]), {case(title)}:m, lemma("дом" or [д.]), {char(numeral)}:m, lemma("квартира" or [кв.]), {char(numeral)}:m)
result: Match = $m
}Соответственно, правило извлечет «Добролюбова 10 11» и «Садовая 29 8».
Ссылки на скобочные группы из регулярных выражений
XPDL позволяет ссылаться на скобочные группы из регулярных выражений с помощью обратных ссылок на регулярные выражения. Синтаксис обратных ссылок на регулярные выражения имеет свои особенности, но в целом они эквивалентны простым обратным ссылкам XPDL и могут использоваться таким же образом.
Можно ссылаться как на именованные, так и на нумерованные скобочные группы. Чтобы сослаться на скобочную группу, сначала нужно поместить в именованную группу функцию regex().
Синтаксис
В следующем примере показан вариант использования этой функции.
Пример. Извлечение email-адресов
Рассмотрим правило на Изображении 5, которое извлекает адреса электронной почты.

Фрагмент правила
rule: email
{
query: {regex("(?<user>[a-z]+)@(?<server>[a-z]+\.[a-z]{2,3})", scope:=text)}:email
result: Email = $email
attribute:User = $email\user
attribute: Server = $email\server
}Регулярное выражение в правиле содержит две группы с именами «user» и «server», которые извлекают последовательность символов до и после «@» соответственно. Обратные ссылки «$email\user» и «$email\server» соответствуют последовательностям, извлеченным этими группами. Результаты работы правила показаны на Изображении 6.

Этот пример можно записать и по-другому, используя нумерованные группы, как показано на Изображении 7.

Фрагмент правила
rule: email
{
query: {regex("([a-z]+)@([a-z]+\.[a-z]{2,3})", scope:=text)}:email
result: Email = $email
attribute: User = $email\1
attribute: Server = $email\2
}Регулярные выражения на Изображении 5 и Изображении 7 идентичны по значению, но во втором случае захватываемые группы не поименованы, поэтому вместо них используется номер группы.
Таким образом, «$email\1» соответствует части запроса в первых скобках, а «$email\2» — части запроса во вторых скобках. Правило возвращает тот же результат, что и правило из предыдущего примера (см. Изображение 6).
Именованные подгруппы и составные ссылки
При создании именованной группы все ее вложенные именованные группы и ссылки сохраняются в подгруппах внутри нее. Впоследствии на них можно ссылаться вместе со всей именованной группой.
Рассмотрим правила, извлекающие названия министерств на Изображении 8.

Фрагмент правила
rule: ministry
// Министерство труда
{
query: {phrase(министерство, {lemma(noun_genitive)}:industry)}:ministry
rule: ministry_geo
// Министерство труда РФ
{
query: {phrase($ministry, {dictword(GeoAdministrative)}:geo)}:ministry_geo
result: Отрасль = $industry
}
}Верхнее правило объявляет две именованные группы: «ministry» и «industry».
Найденные верхним правилом вхождения («труда» и «Министерство труда») хранятся в группах «industry» и «ministry» соответственно. «Труда» также хранится в подгруппе «industry» группы «ministry», потому что подгруппа «industry» вложена в группу «ministry».
По аналогии, когда вложенное правило находит вхождение «Министерство труда РФ», оно хранится в группе «ministry_geo». «Министерство труда» и «труда» хранятся в подгруппах «ministry» и «industry» соответственно (у «ministry_geo» есть вложенная ссылка на группу «ministry», которая, в свою очередь, ссылается на подгруппу «industry»).
Сослаться на подгруппы можно при помощи составной ссылки $группа:подгруппа. Например, $ministry_geo:ministry ссылается на «Министерство труда».
При работе с несколькими уровнями вложенности (industry → ministry → ministry_geo) нужно указать только группы верхнего и нижнего уровня (промежуточные группы игнорируются). Например, $ministry_geo:industry.
На первый взгляд этот функционал кажется сложным, но он может быть полезен для решения конкретных задач.
Пример. Контекстное извлечение имен людей
Этот пример иллюстрирует контекстный подход к извлечению имен людей. Правило на Изображении 9 опирается на такие слова-маркеры, как профессии (архитектор, писатель, предприниматель), так как следующие за ними слова с заглавной буквы могут быть именем человека. Предположим, что эти слова были заранее добавлены в список слов «profession». Поисковый запрос извлекает слова из словарного списка «profession», после которых идут два или три слова с большой буквы («адвокат Рамиль Ахметгалиев», «редактор Миронова Инна Богдановна»…).

Фрагмент правила
rule: person_context
{
query: {phrase(0, {term(ee_professions)}:profession, {repeat(2, 3, case(title))}:name)}:mention
result: Персона = $mention
attribute: Имя = $name
attribute: Профессия = $profession
}Правило отрабатывает в следующих случаях:

В целом правило выдает правильные результаты. Однако можно заметить, что слова-маркеры во множественном числе часто указывают на то, что речь идет не об одном, а о нескольких людях (например, «адвокаты Евгений Жуков и Анатолий Шевчук»). Сейчас правило извлекает только имя первого человека после названия профессии, но его можно расширить, чтобы извлечь и второе имя, как показано на Изображении 10.

Фрагмент правила
rule: person_context
{
query: {phrase(0, {term(ee_professions)}:profession, {repeat(2, 3, case(title))}:name)}:mention
result: Персона = $mention
attribute: Имя = $name
attribute: Профессия = $profession
rule: context_coordinated
{
query: {phrase(0, $mention, и, {repeat(2, 3, case(title))}:name2)}:mention2
result: Персона = $mention2
attribute: Имя = $name2
attribute: Профессия = $profession
}
}Отредактированное правило извлекает и неправильные вхождения, например «директор Росгвардии Виктор Золотов и Правительство Тульской области». Чтобы их исключить, можно проверить, что слово-маркер употреблено во множественном числе. В таком случае нужно обратиться не ко всей именованной группе «mention», а к подгруппе «profession», как показано на Изображении 11.

Фрагмент правила
rule: person_context
{
query: {phrase(0, {term(ee_professions)}:profession, {repeat(2, 3, case(title))}:name)}:mention
result: Персона = $mention
attribute: Имя = $name
attribute: Профессия = $profession
rule: context_coordinated
{
query: {phrase(0, lemma(plural, $mention:profession), $mention:name, и, {repeat(2, 3, case(title))}:name2)}:mention2
result: Персона = $mention2
attribute: Имя = $name2
attribute: Профессия = $profession
}
}Финальная версия правила возвращает правильные результаты, как показано на Изображении 12.

Ссылки на позицию и ссылки на содержимое
Рассмотрим правила на Изображении 13, которые извлекают аббревиатуры после последовательности «название компании (аббревиатура)».

Фрагмент правила
rule: full_comp_names
{
// например, ОАО "Российские железные дороги"
query: {phrase(orn(зао, пао, оао, ooo), case(title_mixed), repeat(1, 2, lemma(noun|adjective)))}: comp
result: Компания = $comp
rule: abbrev_after_comp
{
// например, ОАО "Российские железные дороги" (РЖД)
query: phrase($comp, "(", {case(upper)}:abbr, ")")
result: Компания = $abbr
}
}Эти правила извлекают только те аббревиатуры, которые следуют за названием компании, как в примере на Изображении 14.

Однако сокращенные названия компаний могут встретиться в тексте изолированно, как показано на Изображении 15.

Хочется извлекать и такие независимые вхождения, так как уже известно, к какой компании они относятся. Кажется логичным использовать обратную ссылку, как показано на Изображении 16.

Фрагмент правила
rule: full_comp_names
{
// например, ОАО "Российские железные дороги"
query: {phrase(orn(зао, пао, оао, ooo), case(title_mixed), repeat(1, 2, lemma(noun|adjective)))}: comp
result: Компания = $comp
rule: abbrev_after_comp
{
// например, ОАО "Российские железные дороги" (РЖД)
query: phrase($comp, "(", {case(upper)}:abbr, ")")
result: Компания = $abbr
rule: other_abbrev
{
// например, РЖД начнут проектирование транспортной линии в 2028 году
query: {$abbr}:abbrl
result: Компания = $abbrl
}
}
}К сожалению, если запустить правило на том же тексте, то оно все равно не извлечет «РЖД», как видно на Изображении 17.
Так происходит, потому что обратные ссылки в XPDL относятся к определенной позиции найденного вхождения в документе, а не к документу целиком. Таким образом, запрос «$abbrev» отсылает НЕ к слову «РЖД» вообще, а к «<слову, расположенному на 11 позиции в тексте>». Такой подход оправдан для большинства задач на извлечение информации из текста, он применяется по умолчанию.
Однако есть задачи, где необходимо ссылаться не на позицию, а на весь текст. В таких случаях XPDL позволяет делать обратные ссылки на текст, которые находят то же вхождение, что было найдено в именованной группе.
Синтаксис
Давайте изменим правила, используя обратные ссылки на текст, как показано на Изображении 18.
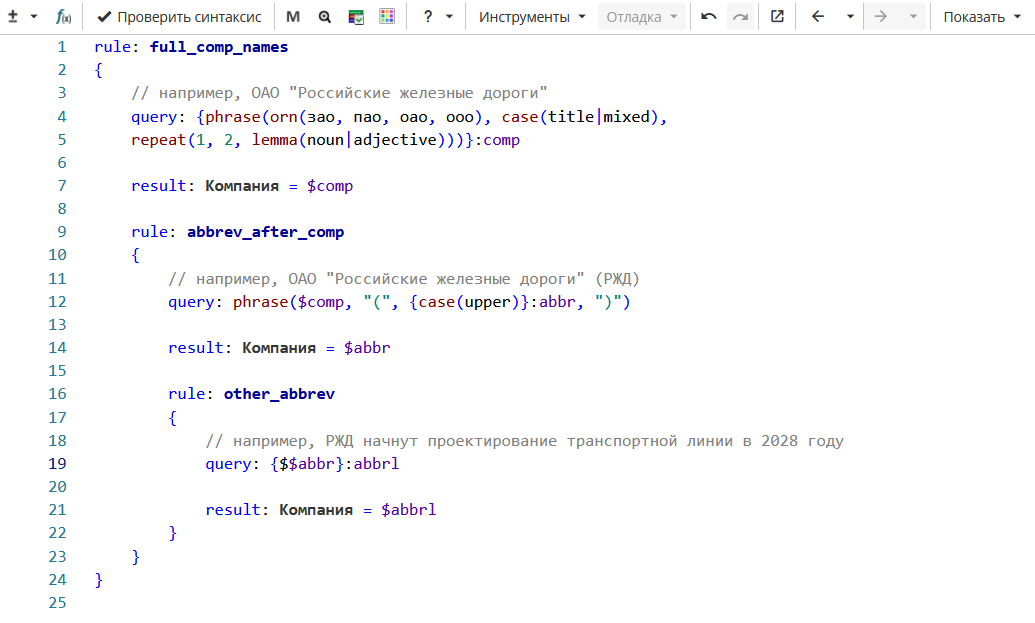
Фрагмент правила
rule: full_comp_names
{
// например, ОАО "Российские железные дороги"
query: {phrase(orn(зао, пао, оао, ooo), case(title_mixed), repeat(1, 2, lemma(noun|adjective)))}: comp
result: Компания = $comp
rule: abbrev_after_comp
{
// например, ОАО "Российские железные дороги" (РЖД)
query: phrase($comp, "(", {case(upper)}:abbr, ")")
result: Компания = $abbr
rule: other_abbrev
{
// например, РЖД начнут проектирование транспортной линии в 2028 году
query: {$$abbr}:abbrl
result: Компания = $abbrl
}
}
}Как видно на Изображении 19, отредактированная версия правила извлекает все аббревиатуры компаний, включая их изолированное употребление.
