Поиск аргументов в произвольном порядке
Поиск аргументов в произвольном порядке на определенном расстоянии
Для поиска последовательности аргументов в произвольном порядке на определенном расстоянии используется функция near().
near() принимает в качестве аргументов слова и фразы в любой форме, а также другие функции поиска слов или последовательностей.
Синтаксис
Опциональный параметр расстояние определяет максимальную разницу в позициях между первым и последним токеном последовательности. При его отсутствии функция ищет аргументы, стоящие рядом.
Опциональные параметры функции
Следующие параметры регулируют расстояние между элементами последовательности:
Параметр |
Пояснение |
distance |
Определяет точную разницу в позициях между первым и последним токеном последовательности. |
min_distance |
Определяет минимальную разницу в позициях между первым и последним токеном последовательности. |
max_distance |
Определяет максимальную разницу в позициях между первым и последним токеном последовательности. Равнозначен опциональному параметру расстояние. |
range |
Определяет точную длину последовательности в токенах. |
min_range |
Определяет минимальную длину последовательности в токенах. |
max_range |
Определяет максимальную длину последовательности в токенах. |
gap |
Определяет точное количество токенов между аргументами последовательности. |
min_gap |
Определяет минимальное количество токенов между аргументами последовательности. |
max_gap |
Определяет максимальное количество токенов между аргументами последовательности. |
interval |
Определяет точную разницу в позициях между соседними аргументами последовательности. |
min_interval |
Определяет минимальную разницу в позициях между соседними аргументами последовательности. |
max_interval |
Определяет максимальную разницу в позициях между соседними аргументами последовательности. |
Параметры allow_punct и allow_space регулируют, соответственно, допустимость знаков препинания и пробелов внутри последовательности. Параметры принимают следующие значения:
Значение |
Пояснение |
yes (значение по умолчанию) |
Пробелы/Знаки пунктуации между аргументами последовательности допускаются. |
no |
Пробелы/Знаки пунктуации между аргументами последовательности не допускаются. |
Примечание
Специальные символы, такие как знак решетки (#), амперсанд (&) или коммерческое at (@), не относятся к знакам препинания и учитываются при расчете расстояния.
Примеры
Параметр match регулирует объем текста, извлекаемого функцией. Параметр принимает следующие значения:
Значение |
Пояснение |
arguments (значение по умолчанию) |
Будут извлечены только аргументы, перечисленные в функции. |
range |
Будет извлечен фрагмент текста от первого до последнего найденного аргумента. |
Пример
Примечания
-
Для поиска последовательности аргументов в произвольном порядке в пределах одного предложения используется функция snear(), аналогичная sentence(near()).
-
Для поиска последовательности аргументов в заданном порядке на определенном расстоянии используется функция fnear().
Функции поддерживают те же именованные параметры, что и функция near().
Примеры
Поиск аргументов в произвольном порядке в пределах предложения
Для поиска последовательности аргументов в произвольном порядке в пределах указанного числа предложений, используется функция sentence().
sentence() принимает в качестве аргументов слова и фразы в любой форме, а также другие функции поиска слов или последовательностей.
Синтаксис
У функции sentence() нет обязательных аргументов — при их отсутствии найдутся все предложения. Опциональный параметр расстояние определяет максимальное количество предложений, в пределах которых ищутся аргументы. При его отсутствии функция ищет аргументы в пределах одного предложения.
Функция также поддерживает следующие опциональные именованные параметры:
-
match, который позволяет регулировать объем текста, извлекаемого функцией;
-
whole:=yes, который позволяет извлекать предложения, состоящие только из аргументов, указанных в запросе.
Значение |
Пояснение |
match:=arguments (значение по умолчанию) |
Будут извлечены только аргументы, перечисленные в функции. |
match:=range |
Будут извлечены предложения, содержащие найденные аргументы, целиком. |
whole:=yes |
Будут извлечены предложения, состоящие только из аргументов, указанных в запросе. |
Примеры
Примечания
-
Для поиска аргументов в заданном порядке в пределах одного предложения используется функция sfollow(), аналогичная функции sentence(follow()) или follow(1,).
-
Для поиска последовательности аргументов на заданном расстоянии в пределах одного предложения используется функция snear(), аналогичная sentence(near()).
Поиск аргументов в произвольном порядке в пределах нескольких строк
Для поиска последовательности аргументов в произвольном порядке в пределах указанного числа строк, используется функция line().
Синтаксис
У функции нет обязательных аргументов — при их отсутствии найдутся все строки.
line() принимает в качестве аргументов слова и фразы в любой форме, а также другие функции поиска слов или последовательностей.
Опциональный параметр число_строк позволяет указать максимально допустимое число строк, в пределах которых нужно искать аргументы или члены последовательности. При его отсутствии функция ищет аргументы в пределах одной строки.
Функция также поддерживает следующие опциональные именованные параметры:
Значение |
Пояснение |
match:=arguments (значение по умолчанию) |
Будут извлечены только аргументы, перечисленные в функции. |
match:=range |
Будут извлечены фрагменты строк от первого до последнего вхождения каждого из аргументов функции. |
whole:=yes |
Будут полностью извлечены строки, которые содержат аргументы запроса. |
min_length |
Задает минимальную длину строки в токенах. |
max_length |
Задает максимальную длину строки в токенах. |
Примечание
При работе функции line пустые строки игнорируются.
Пример
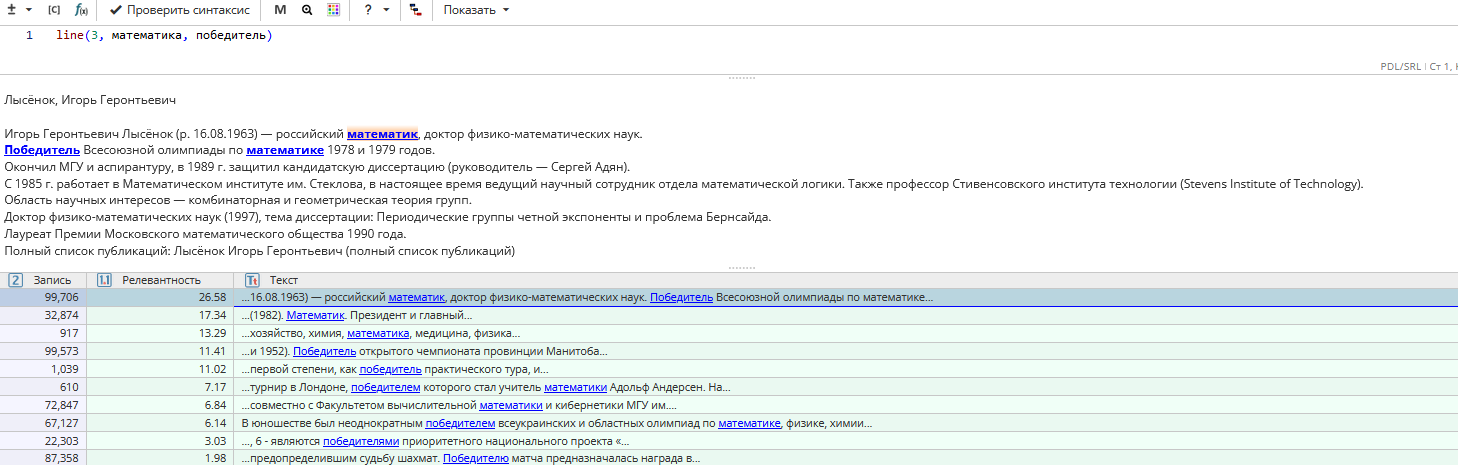
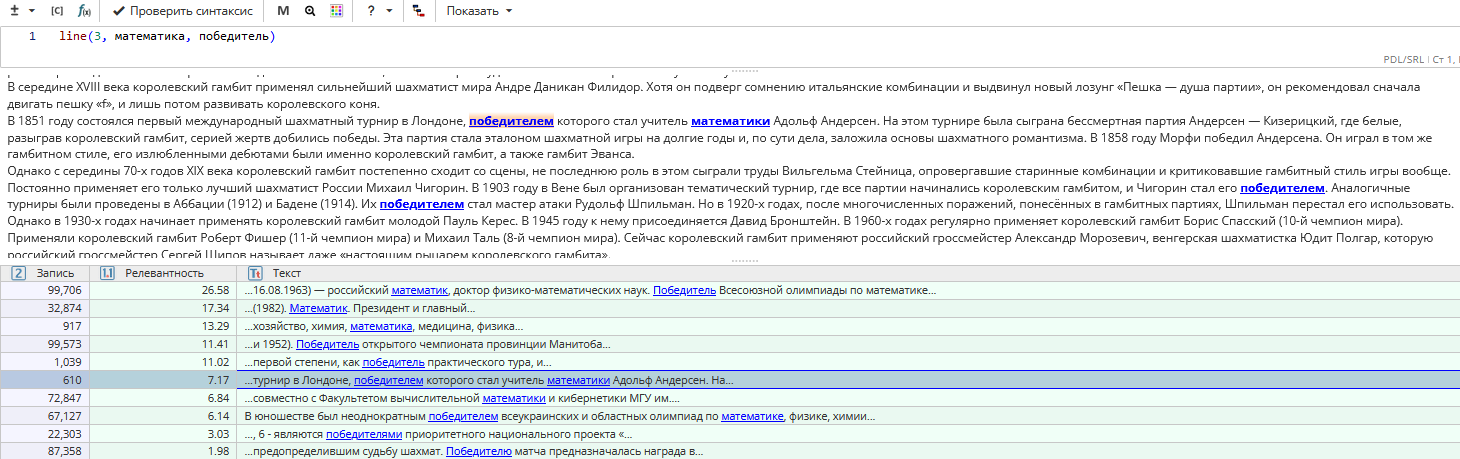
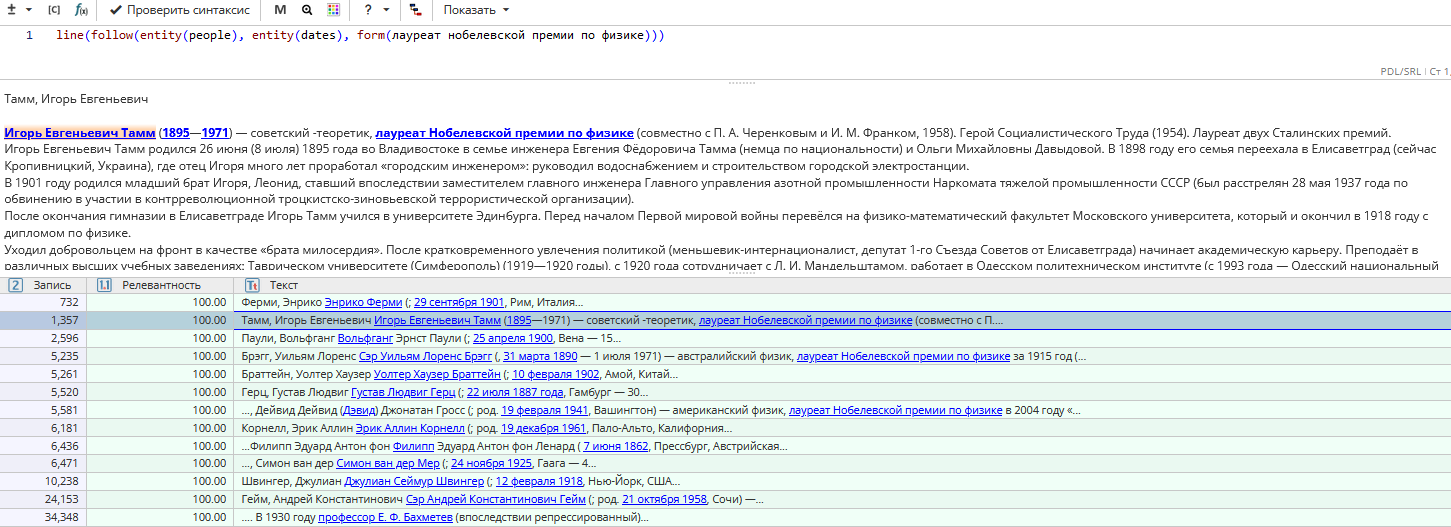
Пример задачи: Найти имена и даты жизни лауреатов Нобелевской премии по физике в статьях Википедии
Для того, чтобы решить эту задачу, можно составить запрос line(follow(entity(people), entity(dates), form(лауреат нобелевской премии по физике))). Он находит имя человека, за которым следуют дата и словосочетание «лауреат Нобелевской премии по физике» в пределах 1 предложения и 1 строки.
Подробнее о функции entity() можно узнать в разделе "Поиск объектов, извлеченных другими узлами текстового анализа".
Поиск аргументов в произвольном порядке в пределах нескольких абзацев
Для поиска последовательности аргументов в произвольном порядке в пределах указанного числа абзацев, используется функция paragraph().
Синтаксис
У функции нет обязательных аргументов — при их отсутствии найдутся все абзацы.
paragraph() принимает в качестве аргументов слова и фразы в любой форме, а также другие функции поиска слов или последовательностей.
Опциональный параметр число_абзацев позволяет указать максимально допустимое число абзацев, в пределах которых нужно искать аргументы или члены последовательности. При его отсутствии функция ищет аргументы в пределах одного абзаца.
Функция также поддерживает следующие опциональные именованные параметры:
-
match, который позволяет регулировать объем текста, извлекаемого функцией;
-
whole:=yes, который позволяет извлечь абзацы, состоящие только из аргументов, указанных в запросе.
Значение |
Пояснение |
arguments (значение по умолчанию) |
Будут извлечены только аргументы, перечисленные в функции. |
range |
Будут извлечены абзацы, содержащие найденные аргументы, целиком. |
whole:=yes |
Будут извлечены абзацы, состоящие только из аргументов, указанных в запросе. |
Примечание
Разбиение текста на абзацы можно увидеть в узлах Индекс или Разметка текста.
Пример
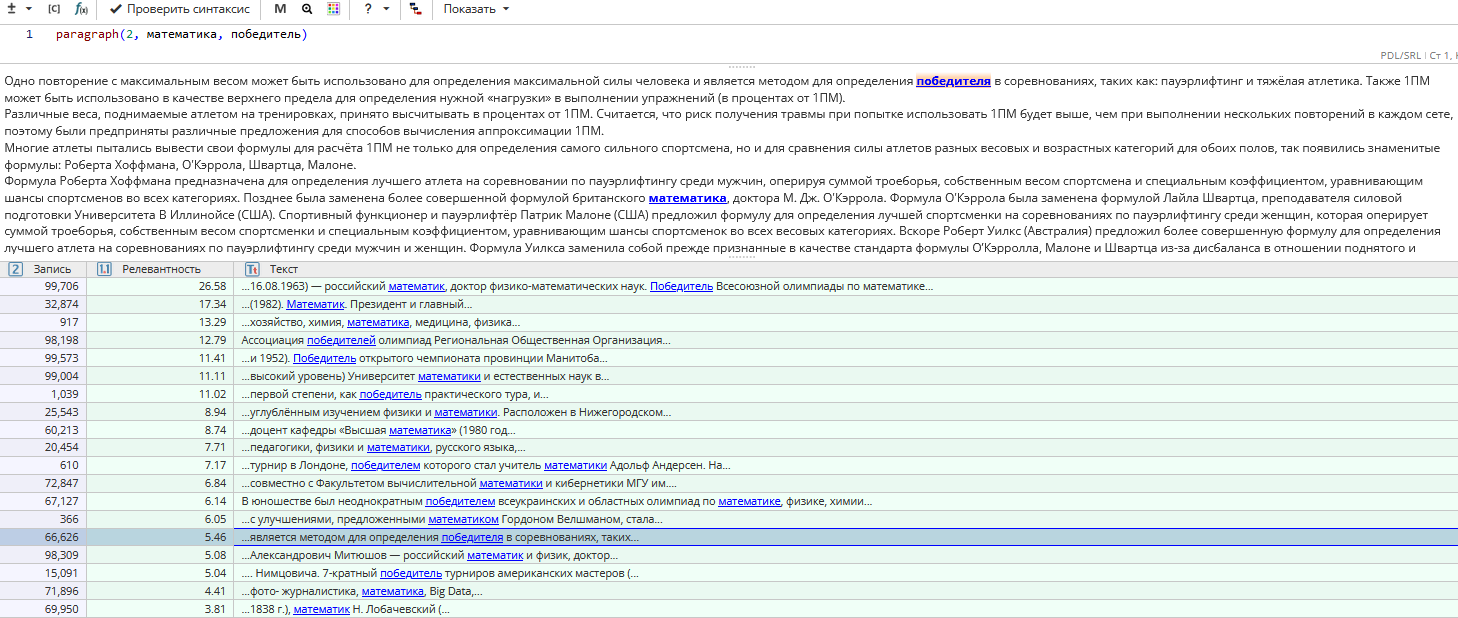
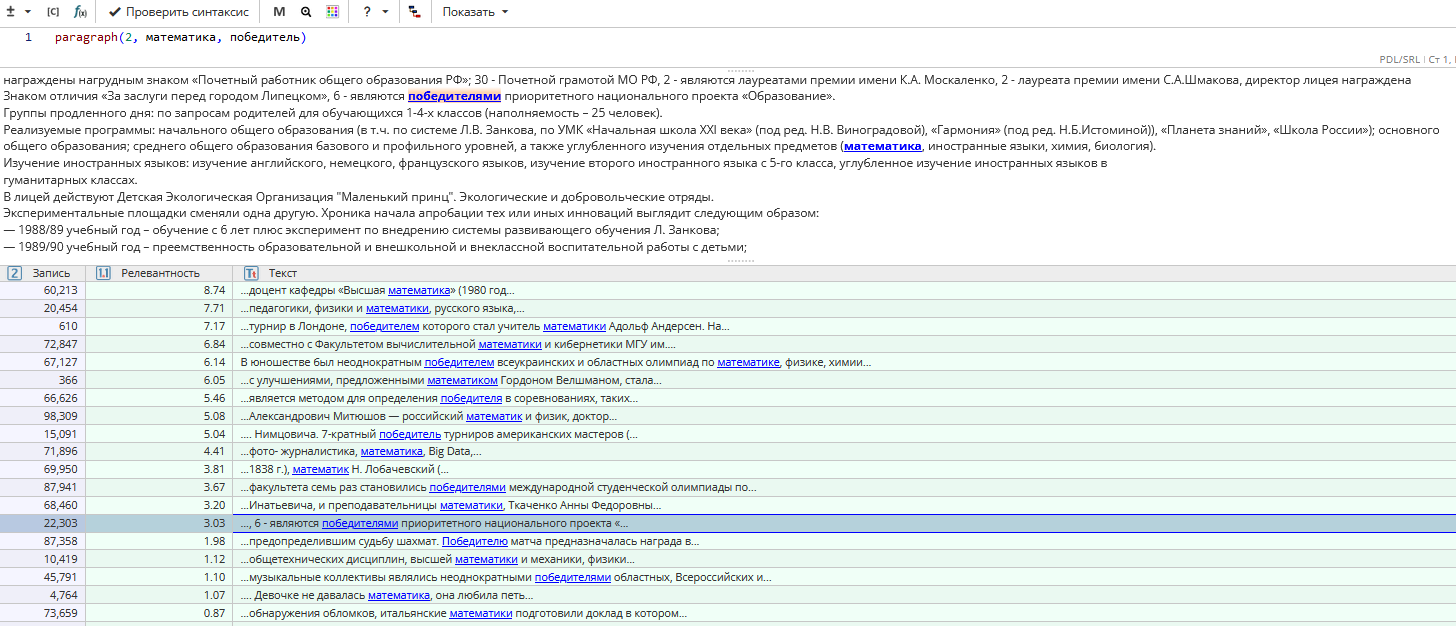
Пример задачи: Поиск контактной информации
Для того, чтобы решить эту задачу, можно составить запрос paragraph(2, entity(Post Addresses), entity(Phone Numbers)). Подробнее о функции entity() можно узнать в разделе "Поиск объектов, извлеченных другими узлами текстового анализа".
Этот запрос найдет последовательность из предварительно найденных адреса и телефона. Область поиска состоит из двух абзацев, поскольку адрес и телефон могут быть разделены пустой строкой.
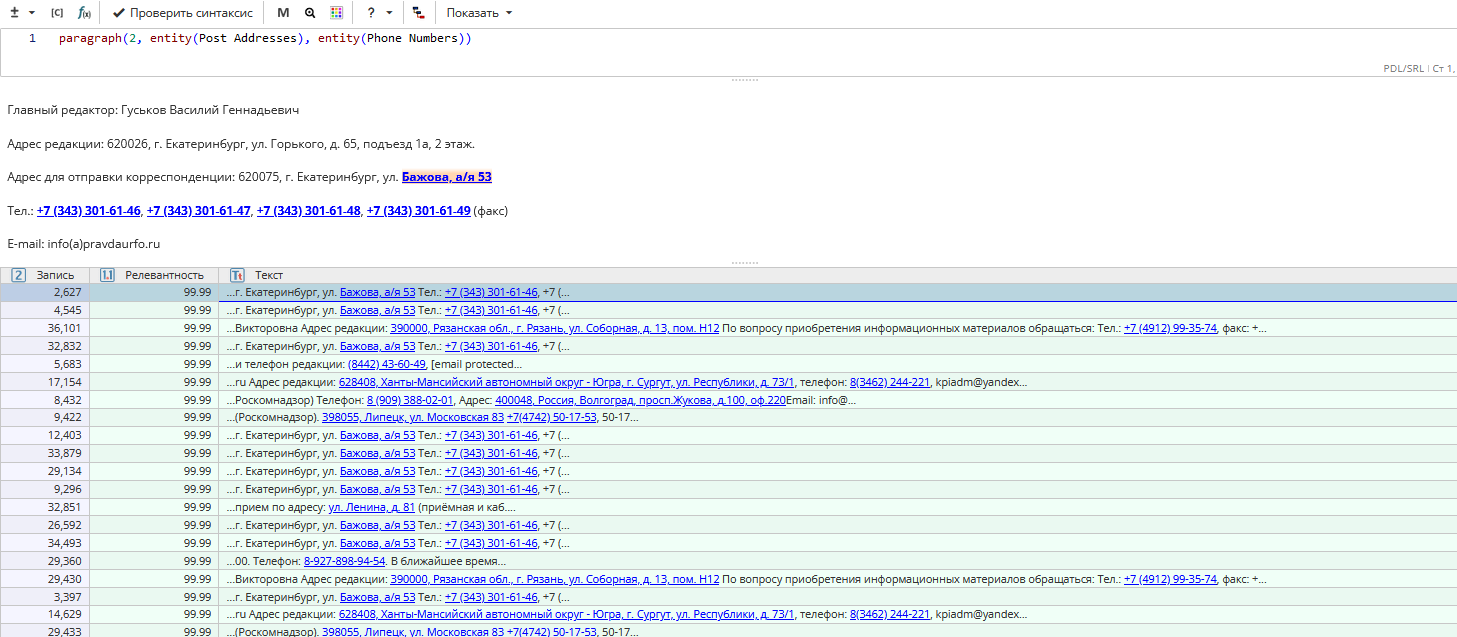
Поиск внутри датасета
Функция document() используется для поиска документов внутри датасета.
Синтаксис
У функции document() нет обязательных аргументов. При их отсутствии функция извлечет все слова документа. Опциональные параметры минимальный_номер и максимальный_номер определяют минимальный и максимальный номер документа в пределах датасета. В их отсутствие функция ищет документы в пределах всего датасета. При этом все значимые аргументы должны находиться в пределах одного документа.
Функция поддерживает следующие опциональные именованные параметры:
Параметр |
Пояснение |
match:=range |
Документы, содержащие найденные аргументы, будут извлечены целиком. |
match:=arguments |
Будут извлечены только аргументы, перечисленные в функции. |
whole:=yes |
Будут извлечены документы, состоящие только из аргументов, указанных в запросе. |
allow_punct:=yes/no |
Знаки пунктуации между аргументами последовательности допускаются или запрещаются (по умолчанию allow_punct:=yes). |
allow_space:=yes/no |
Пробелы между аргументами последовательности допускаются или запрещаются (по умолчанию allow_space:=yes). |
min_doc:=<numeral> |
Задает минимальный номер документа в датасете. |
max_doc:=<numeral> |
Задает максимальный номер документа в датасете. |
mode:=forward/backward |
Указывает позицию от начала/конца датасета. |
Примечание
Если первый и/или второй аргумент функции является числом, то он будет трактоваться как минимальный_номер и максимальный_номер соответственно.
Если указаны как первые числовые аргументы минимальный_номер и максимальный_номер, так и именованные параметры min_doc и max_doc, то приоритет будет отдаваться последним.
Пример
Функция document() может использоваться совместно с функциями типа case(), length(), lemma().
Пример
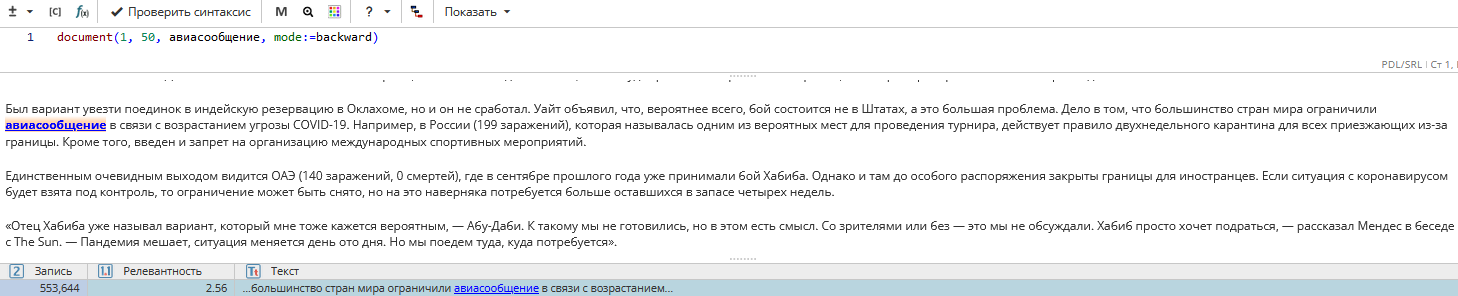
Пример задачи: Найти упоминание авиасообщений в 50 последних предложениях датасета
Для того, чтобы решить эту задачу, можно составить запрос document(1, 50, авиасообщение, mode:=backward)