Поддержка регулярных выражений
Для поиска фрагментов документа, соответствующих определенному регулярному выражению, используется функция regex().
Синтаксис
Функция принимает в качестве единственного аргумента регулярное выражение, записанное в кавычках. Регулярное выражение должно соответствовать синтаксису Perl (http://perldoc.perl.org/perlre.html).
Однако в PDL по умолчанию игнорируются пробелы в регулярных выражениях. Например, regex("a б") = regex("aб").
Функция regex() может принимать следующие опциональные именованные параметры:
Именованный параметр |
Пояснение |
scope:=word/sentence/paragraph/text |
область действия ограничена словом/предложением/параграфом/документом; |
casesens:=yes/no |
включает/отключает чувствительность к регистру; |
ignore_ws:=yes/no |
включает/отключает режим игнорирования пробелов в регулярном выражении; |
wholeword:=yes/no |
фрагмент, соответствующий регулярному выражению, совпадает/не совпадает с границей слова. |
Пример
Примечания
1) По умолчанию scope:=word, то есть функция regex() ищет отдельные токены текста, целиком соответствующие регулярному выражению. Чтобы также найти слова, чей фрагмент соответствует регулярному выражению, нужно добавить в запрос параметр wholeword:=no.
Пример
2) Чтобы найти фрагмент текста из нескольких токенов, соответствующий регулярному выражению, необходимо указать значение именованного параметра scope:=sentence/paragraph/text.
Пример
Если scope:=sentence/paragraph/text, фрагмент текста, соответствующий регулярному выражению, по умолчанию может не совпадать с границей слова. Чтобы изменить данное поведение, следует добавить в запрос wholeword:=yes.
Пример
3) По умолчанию casesens:=no, то есть функция regex() не учитывает регистр при поиске.
Чтобы сделать регулярное выражение чувствительным к регистру, следует добавить именованный параметр casesens:=yes.
Пример
4) По умолчанию ignore_ws:=yes, то есть пробелы внутри регулярного выражения игнорируются. Чтобы изменить данное поведение, следует добавить в запрос ignore_ws:=no, либо заменить символы пробелов на \s.
Пример
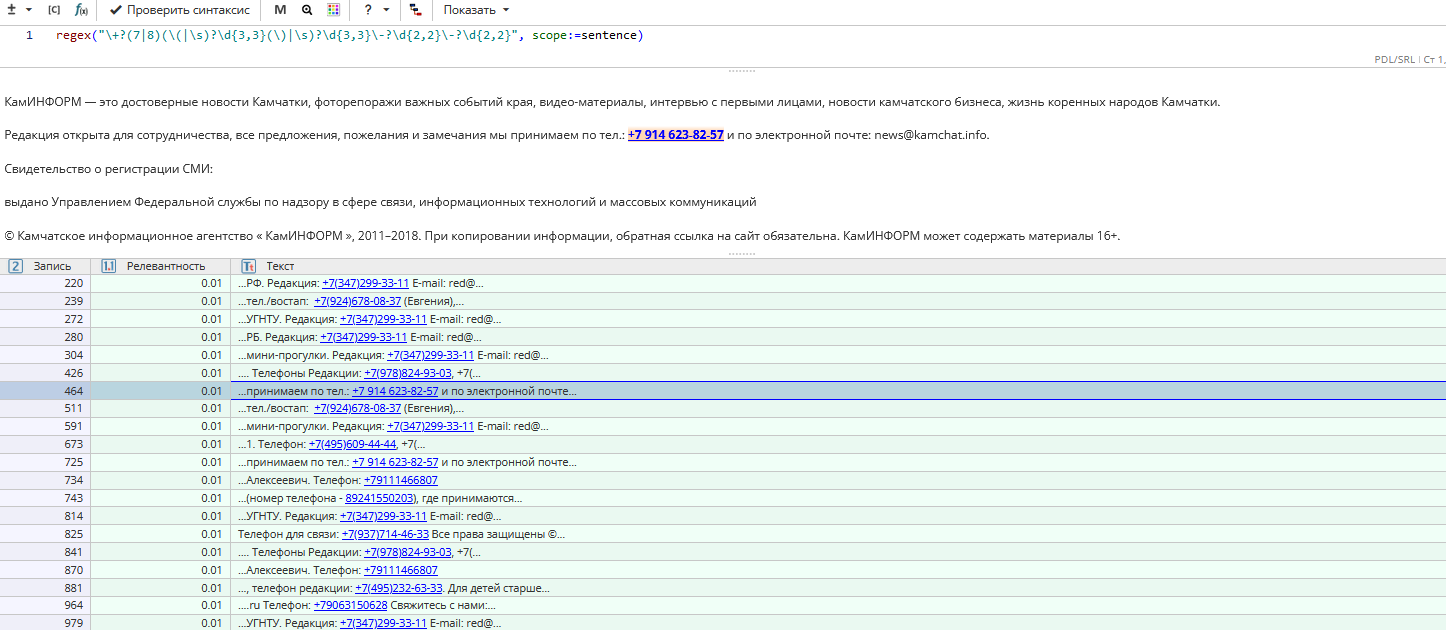
Пример задачи 1: Найти номера телефонов
Запрос для нахождения номеров телефонов в формате +7(XXX)XXX-XX-XX, +7 XXX XXX-XX-XX, 8(XXX)XXX-XX-XX, 8 XXX XXX-XX-XX может выглядеть следующим образом:
Заметим, что без параметра scope:=sentence данный запрос работать не будет, так как искомый фрагмент документа представляет собой последовательность из нескольких токенов.
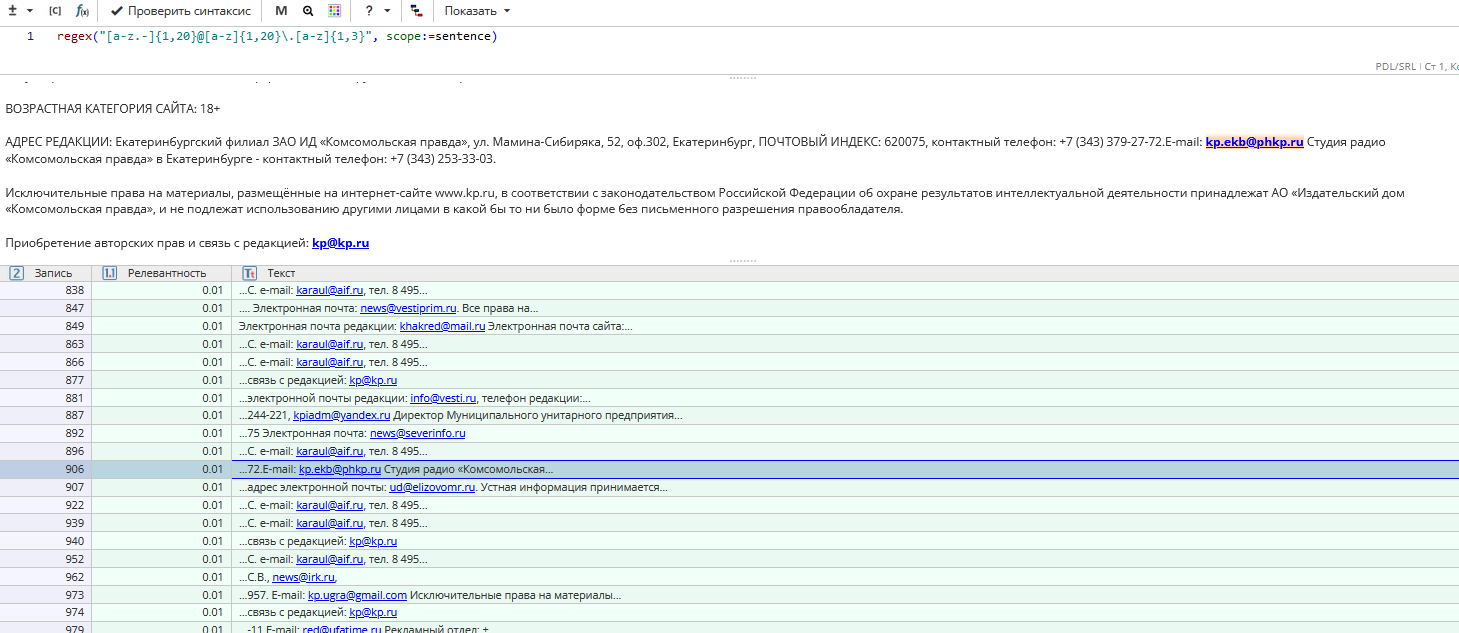
Пример задачи 2: Найти адреса электронной почты
Запрос для нахождения адресов электронной почты может выглядеть следующим образом:
Как и в предыдущем примере, без параметра scope:=sentence данный запрос работать не будет, так как искомый фрагмент документа представляет собой последовательность из нескольких токенов.
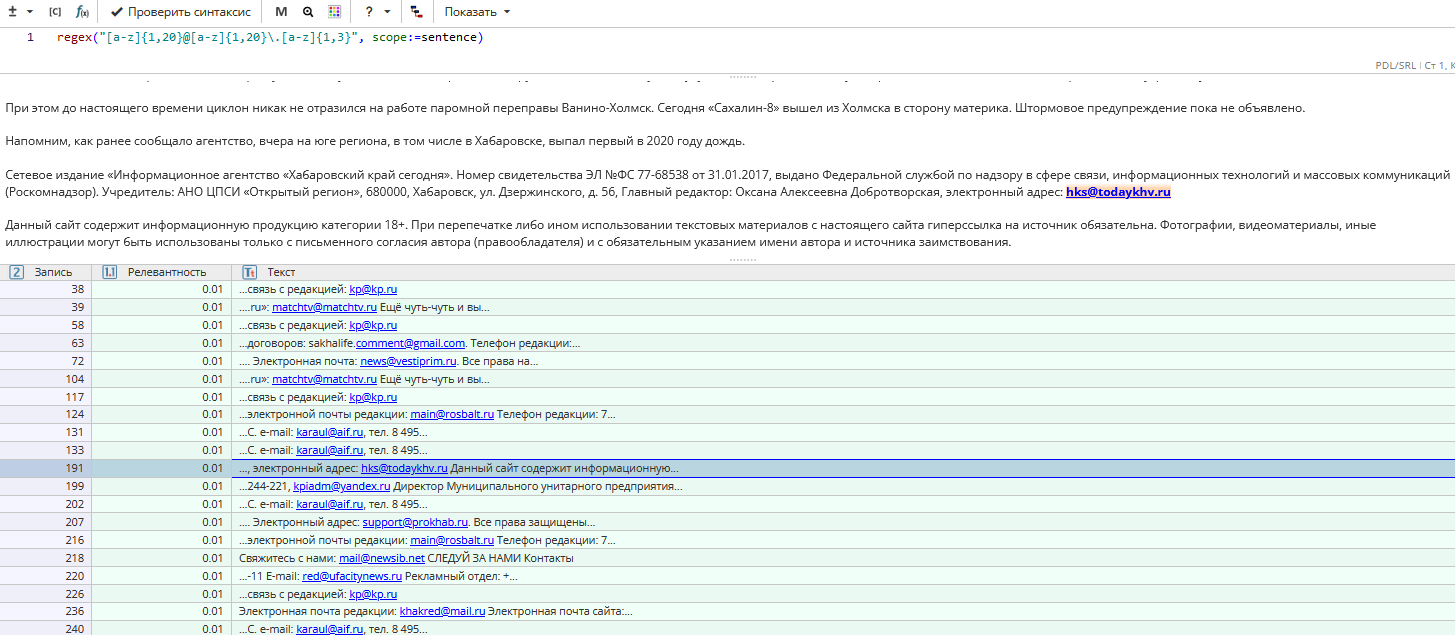
Этот запрос найдет contest@interfax.ru, info@capital.ua, info@vesti.ru, marketing@news.am, но не найдет ivan.ivanov@gmail.com или questions.msk@beeline.ru.
Для нахождения такого адреса нужно добавить возможные знаки пунктуации («.»,«-») перед знаком «@», изменив первоначальный запрос: