Подготовка данных для анализа покупательских корзин
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Прежде чем приступать к анализу покупательских корзин, важно уметь правильно подготовить данные. Анализируемые данные должны иметь особый формат, в котором каждая колонка и каждая строка имеют свои значения. Кроме этого, товары должны быть представлены равномерно. Как правило, товар, который был продан лишь несколько раз, исключается из анализа, в противном случае ассоциативные правила для таких товаров, обнаруженные узлом, не будут иметь статистической значимости. Ни один товар не может быть представлен в данных в 10 раз чаще, чем любой другой. Во избежание таких ситуаций тренировочные данные подвергаются различным манипуляциям. Похожие товары с низкими значениями частотности объединяются в категории (например, хотдоги от разных производителей объединяются в категорию "хотдоги"), а товары с высокими показателями продаж разбиваются по типам товаров (например, все гамбургеры разделяются по брендам).
Входными данными для анализа покупательских корзин обычно является список транзакций, в котором каждая колонка означает товар, а каждая строка — продажу или клиента, в зависимости от цели анализа — найти, какие товары лучше всего продаются вместе в одно и то же время, либо одному и тому же лицу. Ячейки таблицы данных обычно содержат значения 1 (товар куплен) или 0 (товар не куплен), хотя PolyAnalyst может работать с другими данными в ячейках. Например, это может быть количество проданных товаров или полученная с их продажи прибыль. Данные также могут быть представлены в двух колонках, где одна колонка — идентификатор транзакции, а другая — купленный товар.
Как правило, каждая строка входной таблицы обозначает одну транзакцию. Каждая колонка таблицы (выбранная в качестве входной) должна представлять товар в корзине. Если товар был куплен, ячейка содержит истинное значение, если нет — ложное. Колонки товаров могут быть и числовыми, если означают объем продаж или значение общей/чистой прибыли по товару, и в этом случае нулевые значения рассматриваются как 0, что эквивалентно ложному значению, и означает, что товар не был куплен.
Пример данных для анализа покупательских корзин:
Для анализа покупательских корзин необходимо выполнение следующих важных условий. Чтобы получить значимые результаты, необходимо иметь большое количество данных о реальных транзакциях, но если частота приобретения товаров не одинакова, то точность полученных данных будет не очень высокой. Например, если в один анализ покупательской корзины включить молоко, которое входит почти в каждую транзакцию, и клей, который появляется в транзакциях один или два раза в месяц, то мы получим любопытные, но статистически незначимые результаты, которые не будут способствовать получению прибыли. Имея информацию об одном или двух покупателях клея, программа сможет точно указать, какие товары хорошо продаются с клеем, но эта информация будет действительна только для одного или двух покупателей. Однако такое ограничение можно обойти, представив товары в виде таксономии (иерархии).
Наиболее распространенным препятствием для успешного выполнения анализа покупательских корзин является присутствие в корзинах товаров с низкой поддержкой. С этой проблемой можно справиться двумя способами. Первый способ — задать минимальное значение поддержки. Любое сочетание товаров с поддержкой ниже заданного порога будет исключено из отчета узла. Если минимальный порог поддержки составляет 5 %, отсюда следует, что поскольку поддержка группы товаров всегда ниже, чем поддержка каждого отдельного товара в группе, все товары с поддержкой ниже 5% также будут исключены из анализа. К сожалению, такой способ имеет большой недостаток — он исключает некоторые потенциально полезные данные из отчета узла. Поэтому оптимальным решением проблемы низкой поддержки является создание таксономии. Таксономия — это упорядоченная иерархия товаров и их категорий, на которые товары делятся таким образом, что каждый товар в корзине имеет примерно одинаковую поддержку. Это достигается за счет объединения товаров с низкой поддержкой в группы; при этом товары с высокой поддержкой, наоборот, разбиваются на отдельные подкатегории.
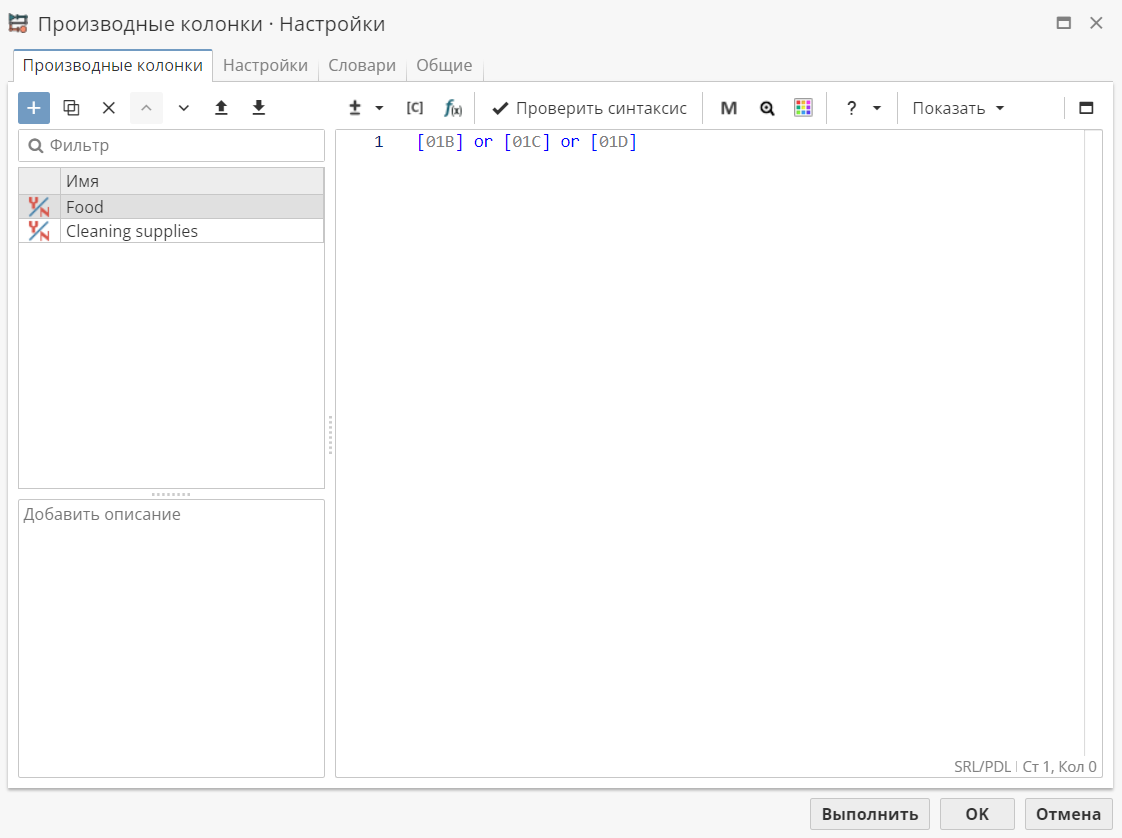
Пользователи должны создать группы товаров, объединив отдельные колонки товаров с помощью узла Производные колонки. Например, предположим, что у нас есть таблица с товарами A, B, C, D и т.д. Предположим, что A и B — продовольственные товары, а C и D — чистящие средства. Используя узел Производные колонки, мы создадим булевую колонку Food (Продовольствие), которая будет истинной, если A и B — истинные (или если или A, или B истинные). Таким же образом мы создадим колонку Cleaning supplies (Чистящие средства), которая будет содержать истинные значения, если C и D — истинные. Затем, в узле Анализ покупательских корзин, вместо того, чтобы выбирать A, B, C, D в качестве исходных колонок, мы можем использовать колонки Food и Cleaning supplies. Таким образом пользователи могут настроить алгоритм на работу с иерархиями товаров.
Можно создать несколько иерархий товаров (или многоуровневую иерархию). Мы можем добавить второй узел Производные колонки после первого узла, который создаст категории товаров более высокого уровня путем объединения низших категорий товаров. Для создания иерархии товаров нужного уровня генерализации вы можете добавить на скрипт узел Производные колонки неограниченное число раз. Затем любой уровень иерархии может стать исходным для алгоритма анализа потребительских корзин.
Обратите внимание на то, что подобная группировка товаров приводит к некому искажению данных (в ваших личных интересах или в интересах вашей компании). Обычно это оправдывают "производственной необходимостью". В ходе любой дополнительной предварительной обработки данных существует вероятность того, что алгоритм обнаружит только определенные результаты, а не все группы товаров, которые были бы обнаружены при обучении модели без учителя. Иногда вмешательство человека приводит к тому, что алгоритм упускает из виду отдельные группы товаров. В то же время, за счет исключения незначимых правил могут быть обнаружены более значимые и полезные ассоциативные правила.
На следующих скриншотах показано, как мы создаем групповые колонки на основе файла BasketData.csv (расположен в папке Примеры, которая была создана при установке PolyAnalyst). Названия выбранных групп являются условными. Сначала создадим и настроим узел Производные колонки с нужными колонками. Например, в этом случае мы создали колонку Food, которая будет содержать истинные значения в том случае, если любая из трех колонок с продовольственными товарами окажется истинной.
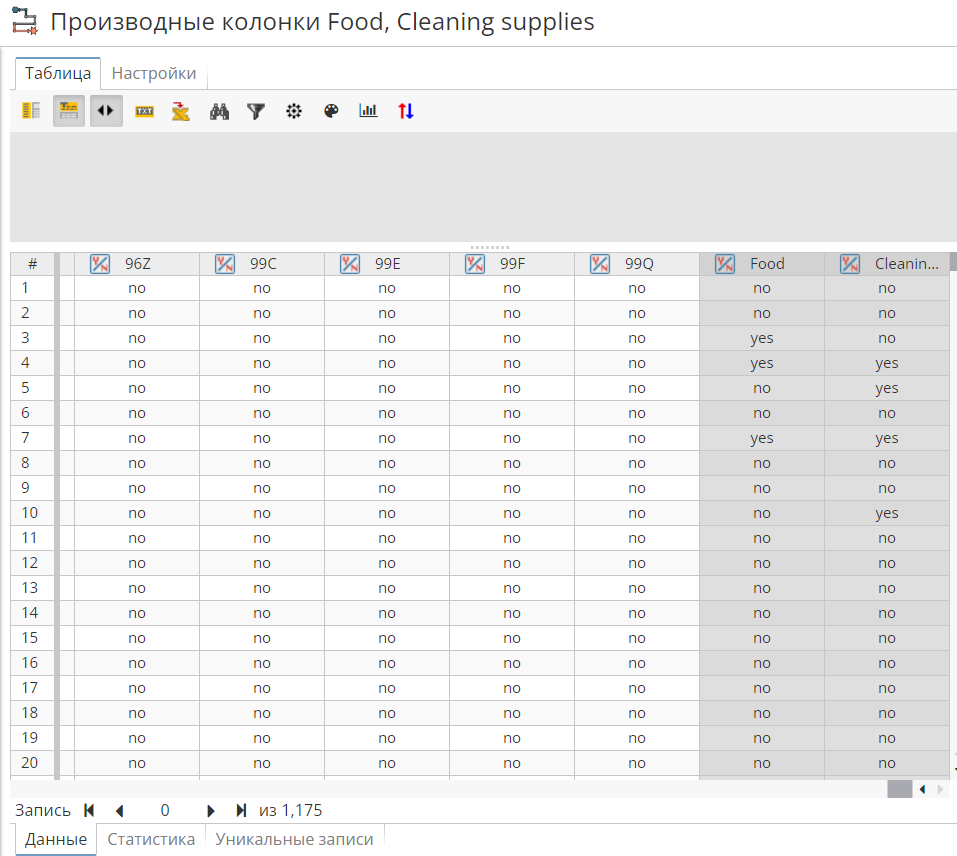
Затем выполним узел Производные колонки, который создаст новые колонки, являющиеся по сути группами колонок с товарами:
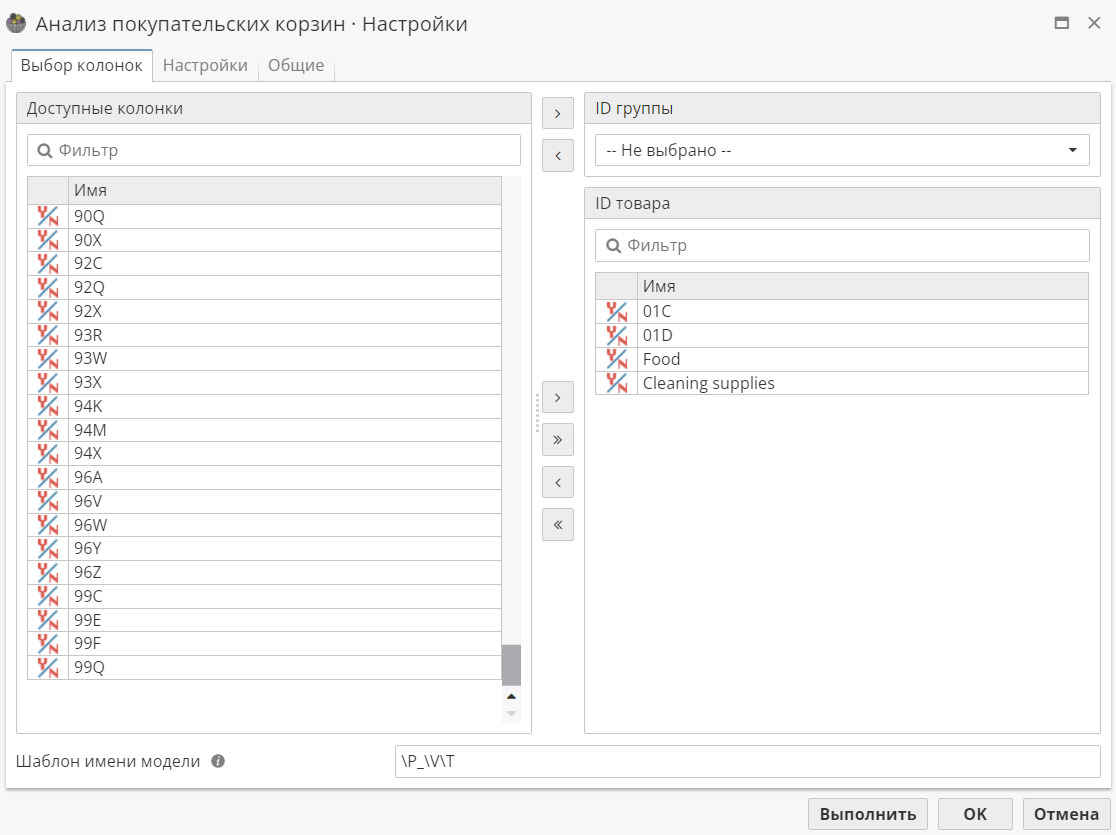
Затем, вместо того, чтобы выбирать отдельные товары в качестве входных данных для узла Анализ покупательских корзин, выберем группы товаров. На следующем рисунке показано, как в качестве целевых колонок узла Анализ покупательских корзин мы выбираем отдельные товары и группы. При такой настройке узел будет искать ассоциации между отдельными товарами, между товарами и группами, или между группами.
Пользователи могут создать неограниченное количество узлов анализа покупательских корзин, которые будут выполнять поиск ассоциативных правил по одной и той же таблице данных. Каждый из этих узлов может быть настроен на выполнение конкретной исследовательской задачи. Объединяя отдельные товары в группы и разбивая группы на отдельные элементы, мы можем выделить в таблице товары с приблизительно одинаковым уровнем поддержки. Уровни поддержки не должны быть абсолютно одинаковыми, но если у одного товара поддержка на порядок выше, чем у другого, то элементы с меньшей поддержкой могут доминировать в полученных ассоциативных правилах. Сравнивая товары с сопоставимым уровнем поддержки, вы можете получить значимые ассоциативные правила.
Предположим, что код товара 01B означает телевизоры, а 01L — гарантию на них. Очевидно, что клиенты, покупающие гарантию, покупают и сам телевизор (это очевидно для людей, но не для алгоритма). Поскольку колонка телевизоров будет содержать истинные значения в 100% случаев при наличии гарантии, это условие алгоритм будет рассматривать как ассоциативное правило. Этот результат не будет иметь значения и, возможно, помешает алгоритму выявить совместные покупки телевизора и другого сопутствующего товара, представляющие больший интерес.
Существует несколько способов решения этой проблемы. Можно использовать узел Модификация колонок или Фильтрация колонок перед узлом Анализ покупательских корзин, чтобы удалить зависимые колонки. Таким образом алгоритм не сможет искать и находить такие ассоциации, а скорость алгоритма увеличится, поскольку сократится количество товаров. Другой вариант — создать небольшую иерархию товаров, используя описанный выше способ, и группируя телевизоры и гарантии на них, а затем в качестве входных данных использовать эту группу, а не код каждого отдельного товара. Вы также можете не использовать колонку кода с гарантией на телевизор в качестве независимой колонки при настройке узла Анализ покупательских корзин; вместо этого оставьте эту колонку в списке доступных колонок. Результат будет таким же, как при фильтрации колонок. Выбор одного из описанных способов зависит исключительно от предпочтений пользователя и позволяет получить одинаковый результат.