Парсер на основе грамматики составляющих (constituency parser)
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
|
Термин парсер может относиться к двум разным типам алгоритмов:
|
Производительность
Устройство парсера составляющих в PolyAnalyst большей частью заимствовано из устройства Стэнфордского восходящего парсера на основе грамматики составляющих. Текущее его применение соответствует строке wsjSR.ser.gz и имеет следующие характеристики:
Загрузка (сек.) |
Разбор (сек.) |
LP/LR F1 |
4,5 |
14 |
85,99 |
Вводные замечания
Парсер составляющих можно представить в виде черного ящика, получающего на входе предложение и выдающего дерево, соответствующее этому предложению. По ребрам дерева можно перейти от родительских узлов к дочерним. Каждый узел этого дерева помечен некоторой строкой. Листья дерева соответствуют токенам предложения. Порядок, в котором в каждой вершине перечисляются дочерние вершины, имеет значение.
Внутренние узлы дерева соответствуют фразам (составляющим) в этом предложении: мы можем объединить некоторые токены предложения в группы, функционирующие как единые синтаксические единицы; мы также можем сделать соответствующий узел в дереве, написать в этом узле тип группы (например, "именная группа", "noun phrase", "NP"; или "глагольная группа", "verb phrase", "VP"). Узлы, соответствующие этим группам, далее опять объединяются и так далее, до тех пор, пока мы не получим одну большую группу, соответствующую всему предложению. Эта группа будет соответствовать корневому узлу дерева. Такие деревья называются деревьями фразовой структуры или же деревьями составляющих. Пример такого дерева представлен ниже:
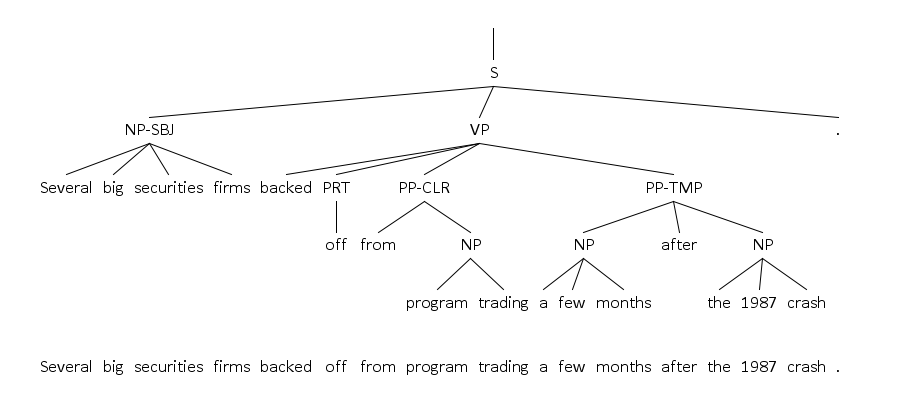
В большинстве случаев деревья составляющих записаны в корпусах в виде скобочной структуры. Эта скобочная структура может быть отформатирована, как на следующем рисунке:

Скобочную структуру также можно записать в одну строку, например:
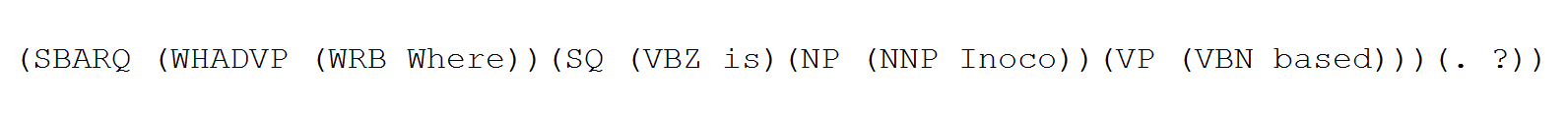
Способ записи деревьев на последних двух рисунках называется форматом MRG. Деревья могут быть записаны и в формате PRD. Различие между MRG и PRD заключается в том, что в PRD убраны пред-терминальные узлы (соответствующие частям речи):

Парсер составляющих в PolyAnalyst
В настоящее время в PolyAnalyst реализован "жадный" восходящий парсер составляющих для английского языка. Он использует базовый набор признаков и применяет liblinear в качестве классификатора.
Числовые характеристики парсера составляющих в PolyAnalyst:
-
точность ~= 0,840382
-
полнота ~= 0,840744
-
F1 ~= 0,84
-
время загрузки с диска ~= 7 секунд
-
скорость работы ~= 300-400 предложений в секунду
Оценка качества разбора
Допустим, что мы хотим оценить качество разбора. Для этого мы берем набор предложений, размеченных людьми (про эти предложения мы считаем, что они размечены полностью правильно, и назовем их эталонными деревьями). Мы также считаем, что и черный ящик, и эталонные деревья используют одни и те же условия разбора (и черный ящик теоретически должен давать разборы, совпадающие с эталонными).
Оценку качества принято делать в терминах точности и полноты. Если мы произведем обход (поиском в ширину или в глубину) такого дерева из какого-либо узла, то в результате посетим некоторое множество листьев. Напомним, что мы переходим по ребрам только в направлении от родительского узла к дочернему. Это множество листьев должно соответствовать некоторой непрерывной последовательности токенов в разобранном предложении.
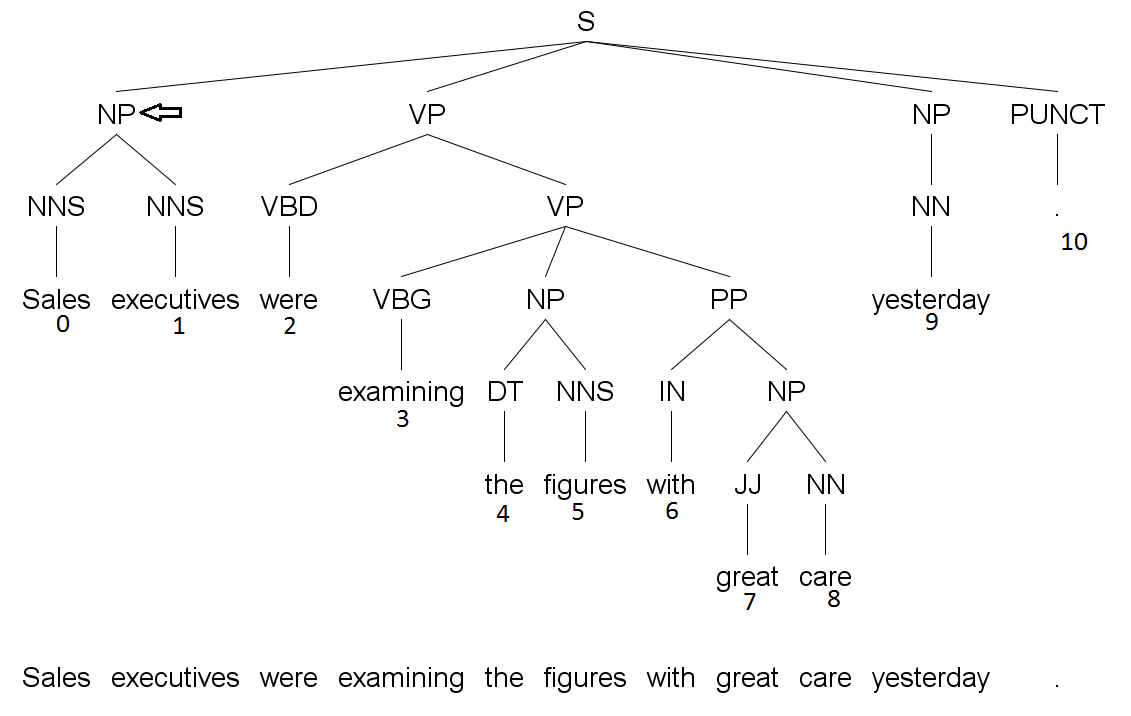
Для примера см. Рисунок 5. При обходе из самого левого узла NP, отмеченного стрелкой, в дереве, мы получим последовательность (Sales, executives). В результате мы можем записать тройку: (метка узла, индекс первого токена в множестве дочерних листьев, индекс последнего токена в множестве дочерних листьев). В рассматриваемом примере это будет (NP, 0, 1).
Получим такую тройку для каждого узла в дереве (за исключением терминалов, содержащих слова, и предтерминалов, содержащих части речи, – они одинаковые в обоих деревьях), полученном при помощи «черного ящика» для некоторого предложения.
Также получим аналогичный набор троек для дерева, построенного экспертом для этого же предложения. Далее обычным способом посчитаем точность и полноту для этих двух наборов троек. Точность означает, сколько троек было найдено верно (среди всех троек, полученных из дерева, которое было создано алгоритмом). Полнота означает, сколько троек, присутствующих в наборе, который был получен из идеального дерева, присутствуют также в наборе, полученном из дерева, которое было создано алгоритмом.
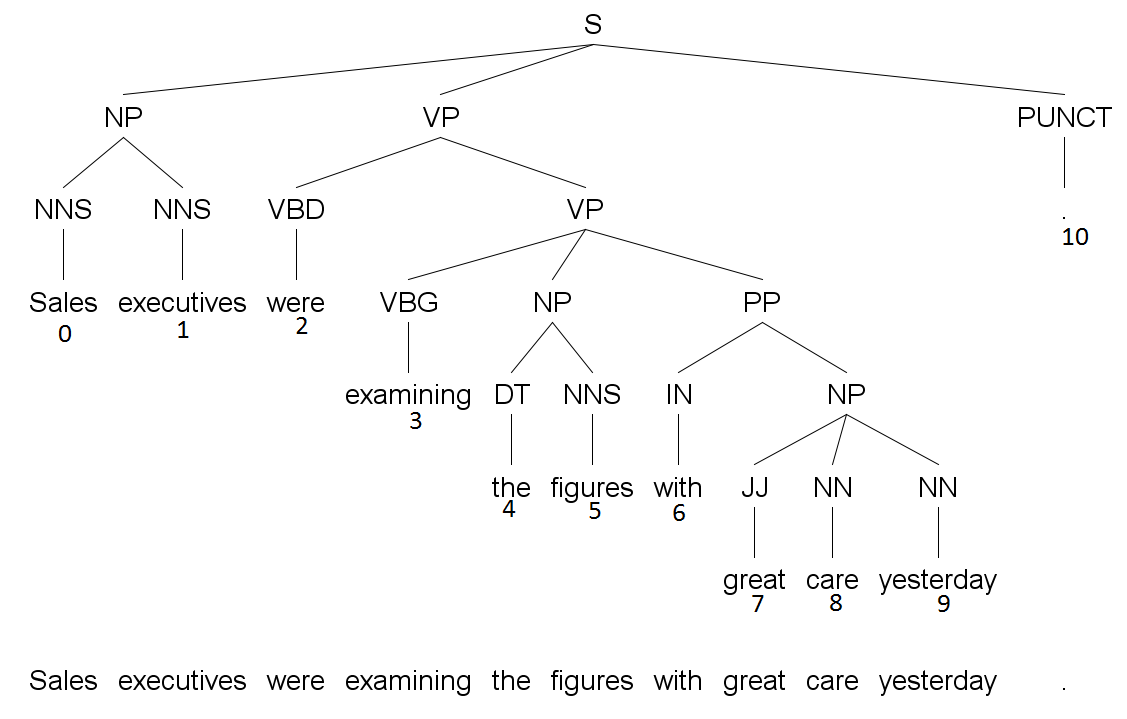
Из эталонного дерева мы получаем следующий набор троек:
(S, 0, 10), (NP, 0, 1), (VP, 2, 8), (VP, 3, 8), (NP, 4, 5), (PP, 6, 8), (NP, 7, 8), NP(9, 9)
Из дерева, выданного парсером, мы получаем следующий набор троек:
(S, 0, 10), (NP, 0, 1), (VP, 2, 9), (VP, 3, 9), (NP, 4, 5), (PP, 6, 9), (NP, 7, 9)
В результате мы получаем точность 3/7 (мощность пересечения этих двух наборов, разделенная на мощность набора, полученного из дерева, которое создал алгоритм) и полноту 3/8 (мощность пересечения этих двух наборов, разделенная на мощность набора, который был получен из экспертного дерева).
Точность и полноту можно использовать для расчета некоторых производных величин, например, F1-меры. Можно также рассчитывать правильность – число полностью правильно разобранных предложений по отношению к общему числу предложений в тестовом наборе.
Алгоритм восходящего парсера
Если мы хотим выполнить разбор (парсинг) предложения, нам нужно завести стек и очередь. В начальный момент времени стек пуст, а очередь содержит маленькие деревья из двух узлов: каждое такое дерево состоит из терминального узла-токена, который подвешивается к узлу-части речи. Эти маленькие деревья расположены в очереди в том же порядке, в котором соответствующие токены идут в предложении.
Для выполнения разбора система должна выполнить следующие шаги:
-
Shift – перемещает дерево из головы очереди на вершину стека.
Допустимо, если очередь не пуста. -
Unary Reduce (Label) – создает новый узел с меткой "Label". Берет дерево с вершины стека, подвешивает его к новому узлу, помещает измененное дерево обратно на вершину стека.
Допустимо, если стек не пустой. -
Left/Right Binary Reduce – создает новый узел с меткой "Label". Извлекает из стека два верхних дерева, подвешивает их к новому узлу. Дерево, ранее находившееся на самой вершине стека, становится правым дочерним поддеревом нового узла. Соответственно дерево, ранее находившееся сразу под вершиной стека, становится левым дочерним поддеревом. Помещает измененное дерево на вершину стека.
Допустимо, если в стеке находятся как минимум два элемента. -
Finalize (Label) – создает новый узел с меткой "Label". Все находящиеся в стеке деревья извлекаются из него и подвешиваются к новому узлу. Новый узел помещается в стек.
Допустимо, если очередь пуста.
Также в системе имеется "оракул", который на основе текущего состояния стека и очереди предсказывает, какое действие стоит сделать следующим, либо выдает все возможные действия, отсортированные в порядке от лучшего к худшему. Чаще всего эта часть реализована на основе алгоритмов машинного обучения. Заметим, что, хотя у нас всего 4 логических действия, 3 из них требуют также метку.
При использовании описанной схемы мы можем построить только бинарные деревья с арностью не выше 2. Но настоящие деревья разбора естественно имеют большую арность, поэтому обучающие деревья предварительно бинаризуют. В результате этого процесса в них возникают новые узлы, которые помечаются специальным образом, чтобы их можно было бы отличить от "нормальных" узлов, изначально бывших в дереве. Метка таких узлов начинается с префикса "@", например +@NP+. Далее оракул обучается на бинаризованных деревьях. После обучения парсер выдает бинаризованные деревья, содержащие искусственные узлы. К этим деревьям можно применить алгоритм дебинаризации, в результате чего из деревьев удаляются искусственные узлы и увеличивается арность.
Оракул, основанный на алгоритмах машинного обучения, иногда может предсказывать действие, неприменимое в данном контексте (например, Binary Reduce в ситуации, когда в стеке находится всего один элемент). Поэтому лучше, если оракул возвращает не просто самое лучшее в данном контексте действие, а все действия вместе с числовой оценкой их "привлекательности". Используя эти оценки, мы сортируем действия по убыванию в соответствии с их привлекательностью; затем выбираем наилучшее действие, удовлетворяющее нашим условиям.
Алгоритм дебинаризации
Для дебинаризации дерева, построенного парсером, мы можем использовать простую рекурсивную функцию. Она принимает в качестве аргумента вершину поддерева и возвращает вершину дебинаризованного поддерева (исходное дерево не меняется). В возвращаемом дебинаризованном поддереве вершина все еще может быть "искусственной", но все прочие узлы уже "настоящие". Процесс происходит следующим образом:
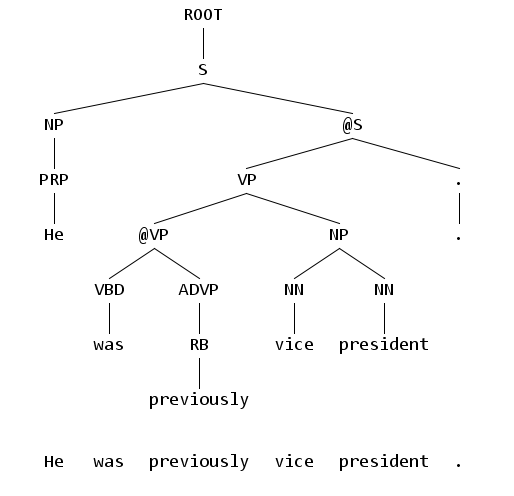
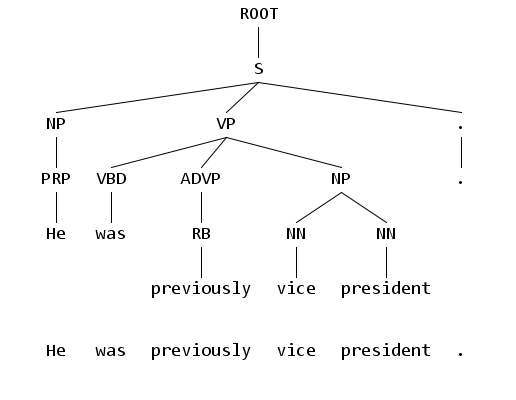
Правила нахождения главного слова
Для понимания дальнейшей информации необходимо ознакомиться с понятием так называемых правил нахождения главного слова. В целом, в каждой фразе есть одно главное слово.
На Рис. 1 во фразе few month главным словом является month. На Рис. 5 во фразе were examining figures with great care главным словом является were.
Находясь в каком-либо из внутренних узлов дерева составляющих, правила нахождения главного слова позволяют определить, какой из дочерних узлов является в подобном смысле "главным".
На Рис. 1 для узла NP (соответствующего фразе a few months) с дочерними узлами DT, JJ, NNS, можно сказать, что NNS является главным узлом.
Каждое правило состоит из метки узла, среди дочерних узлов которого мы будем искать главное слово; списка меток и указания стратегии поиска главного дочернего узла. Для одной и той же метки может быть несколько правил. В таком случае мы последовательно пробуем их, до тех пор, пока главный дочерний узел не будет определен (обычно определен приоритет правил). Очень редко бывают ситуации, когда, перепробовав все правила, не удается найти главный дочерний узел. Если главный дочерний узел не найден, выбирается самый левый или самый правый узел.
Правила нахождения главного слова необходимы для обучения восходящего парсера составляющих (в том числе для бинаризации). Более того, правила нахождения главного слова используются во время конвертации из составляющих в зависимости, а также в других подходах к разбору составляющих.
Используемые признаки
Алгоритмы машинного обучения, используемые в оракулах, часто являются линейными (однослойный многоклассовый персептрон, линейный SVM: liblinear). Для повышения качества классификации нелинейность вносится искусственно: добавляются признаки, являющиеся конкатенациями двух и более "элементарных" признаков. Примерный результат представлен в следующей таблице:
Базовые признаки восходящего парсера составляющих
s0_hpos+s0_label, |
q0_word+q0_pos, |
s0_L_hword+s0_L_label, |
s0_hword+s1_hword, |
s0_label+s1_label+s2_label, |
Примечания к таблице:
q0 – признак берется из головного элемента очереди;
q1 – признак берется из элемента очереди, следующего за головным;
s0 – признак берется из элемента на вершине стека;
s1 – признак берется из элемента стека, лежащего сразу под вершиной, и т.д.
hword – главное слово во фразе;
hpos – часть речи главного слова во фразе;
label – метка фразы;
word - слово;
pos – часть речи;
L – признак извлекается из левого дочернего узла (при условии, что есть ровно 2 дочерних узла);
R – признак извлекается из правого дочернего узла (при условии, что есть ровно 2 дочерних узла);
u – признак извлекается из единственного дочернего узла (при условии что есть ровно 1 дочерний узел).
Все эти признаки являются строковыми, в то время как многие алгоритмы машинного обучения работают с числовыми признаками. Перевод строковых признаков в числовые подробно описан в разделе Парсер на основе грамматики зависимостей.
Замечание о liblinear
В восходящем парсере составляющих в качестве алгоритма машинного обучения в оракуле используется однослойный многоклассовый персептрон. Реализация данного алгоритма не является слишком сложной. Однако, можно использовать liblinear.
Модель, обученную liblinear, нужно сжать и конвертировать в другой формат. После обучения liblinear возвращает линейный массив w чисел типа double. Длина массива w кратна числу признаков, а его содержимое таково:
weight for feature # 1 |
weight for Feature feature # 2 |
… |
weight for Feature #nr_feat |
Примечания:
ne_class – число классов
nr_feat – число признаков
Допустим, нам нужно классифицировать объект, описываемый числовым вектором x длины nr_feat. Заведем вектор scores итоговых оценок длины nr_class и инициализируем его нулями. Далее идем по всем признакам из x, и для n-го признака получаем:
scores (вектор) += x[n] (число) * (веса для признака #n (вектор; заполнен соответствующим диапазоном из w)).
В итоге мы выберем класс, который соответствует ячейке в scores с максимальным значением.
Лучевой поиск
Лучевой поиск - это подход, использующийся в ряде парсеров составляющих / зависимостей для повышения качества разбора (за счет более медленной, но не асимптотически, скорости работы).
Чтобы описать его работу применительно к восходящему парсеру составляющих, нам потребуется оракул, который бы выдавал не единственное локально наилучшее действие, а приписывал каждому возможному действию числовую оценку. Эта оценка позволит отранжировать действия от лучшего к худшему.
Контекстно-свободные грамматики
Еще один класс парсеров основан на том, что дерево составляющих можно трактовать как дерево вывода в некоторой контекстно-свободной грамматике. Контекстно-свободной грамматикой называется четверка N, T, R, B, где:
-
N – множество нетерминальных символов (в нашем случае это фразовые метки NP, VP, ADJP и т.д.);
-
T – множество терминальных символов, не пересекающееся с N (в нашем случае это токены предложений);
-
R – множество правил вывода (правила вывода также называются продукциями). Каждое правило имеет вид A→b, где A – один из нетерминалов, b – строка, символы которой берутся из множеств N и T;
-
B – стартовый символ.
Рассмотрим, например, такую грамматику:
-
N = {S, VP, NP, Verb, Det, Nominal, Noun}
-
T = {book, that, flight}
-
R = {S→VP, VP→Verb NP, Verb→book, NP→Det Nominal, Det→that, Nominal→Noun, Noun → flight}
-
B = {S}
Начиная со стартового символа и применяя правила вывода, мы получаем, что в этой грамматике выводится предложение book that flight. Действительно: S ⇒ VP ⇒ Verb NP ⇒ Verb Det Nominal ⇒ Verb Det Noun ⇒ book Det Noun ⇒ book that Noun ⇒ book that flight. Такой вывод соответствует следующему дереву разбора:
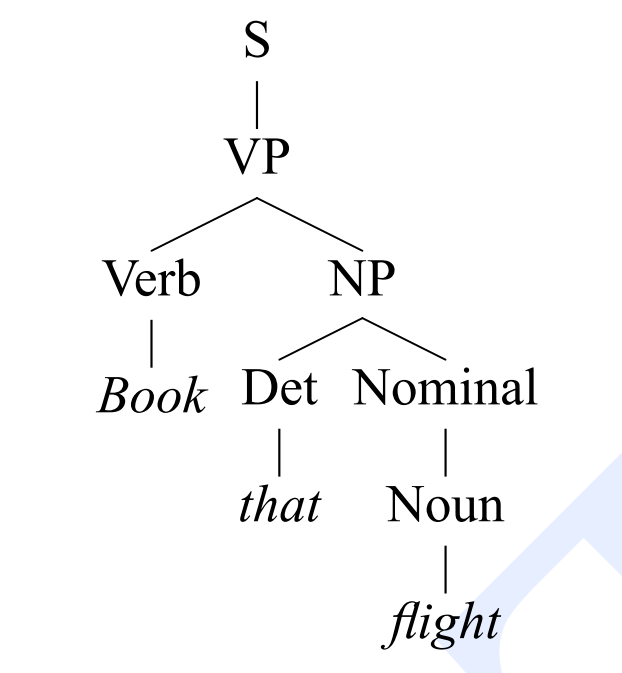
Термин "контекстно-свободная" означает, что мы можем применить продукцию к нетерминалу без учета его контекста (например, когда мы используем продукцию "NP → Det Nominal" в "Verb Np", для нас не имеет значения то, что слева от NP стоит Verb).