Настройка дополнительных опций узла
Другие опции узла содержат дополнительные настройки парсера, например, нормализацию символов, распознавание таблиц и т.д.
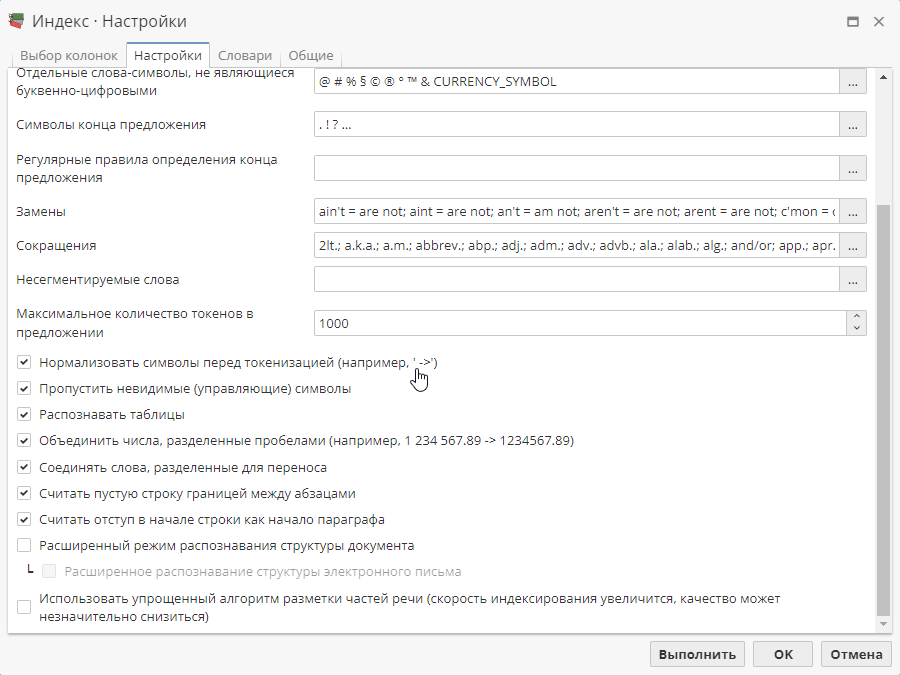
Описание опций приведено ниже.
-
Нормализовать символы перед токенизацией
Данная опция позволяет алгоритму индексирования рассматривать символы, которые имеют одинаковое значение, но различное графическое оформление, как идентичные. Например, к таким символам относятся "" и «».
-
Пропустить невидимые (управляющие) символы
Данная опция позволяет игнорировать специальные символы разметки страницы (абзац, табуляция, пробел, разрыв строки и т.д.).
-
Распознавать таблицы
Если опция включена, PolyAnalyst попытается определить наличие таблиц в документах. Если поведение по умолчанию не приносит желаемых результатов, либо полученные результаты являются ложно-положительными, отключите данную опцию.
-
Объединить числа, разделенные пробелами
Если данная опция включена, PolyAnalyst будет объединять последовательности чисел с пробелом в один токен при парсинге текстов.
Пользователи могут столкнуться с подобной проблемой при использовании PDL-функции number() в узлах Поисковый запрос, Многомерная матрица или Таксономия. Если в результатах узла в ряду разделенных пробелом чисел цветом выделено только первое число, это указывает на то, что данная опция отключена, и что эти числа рассматриваются как отдельные токены.
-
Соединять слова, разделенные для переноса
Если опция включена, алгоритм индексирования будет игнорировать плавающие дефисы, т.е. будет рассматривать слова с дефисами как одно слово. При отключении этой опции алгоритм индексирования будет рассматривать дефис в качестве разделителя слов.
В тексте дефис может выполнять две функции, поэтому алгоритм индексирования может трактовать его двояко. С одной стороны, символ - характеризует конкретное составное слово. Например, когда слово появляется в конце строки в книге, оно разбивается дефисом для переноса, и одна часть слова с дефисом располагается на текущей строке, а оставшиеся буквы слова – на следующей строке. Иногда при сохранении текста в цифровом формате это написание через дефис сохраняется в данных. Простой алгоритм обработки будет распознавать слово с дефисом как два отдельных слова, которые при отдельном упоминании могут не иметь смысла, поскольку не существуют в естественном языке. С другой стороны, символ дефиса иногда означает два разных слова, каждое из которых следует обрабатывать отдельно в процессе индексирования.
-
Считать пустую строку границей между абзацами
Если опция включена, пустая строка будет трактоваться как разделитель между абзацами.
-
Трактовать отступ в начале строки как начало параграфа
Если опция включена, отступ в начале строки будет считаться признаком начала абзаца.
-
Расширенный режим распознавания структуры документа
При включении данной опции будет использован эвристический алгоритм определения заголовков, когда заголовки разделов не обозначены явно (т.е. не характеризуются специальным стилем заголовка). Если родительский набор данных состоит из электронных писем, отметьте галочкой опцию Расширенное распознавание структуры электронного письма для выделения отдельных разделов (например, отправитель, тема и т.д.).
-
Использовать упрощенный алгоритм разметки частей речи
Данная опция позволяет увеличить скорость индексирования текста на 60-90% за счет незначительного снижения качества результатов. При этом будут пропущены некоторые необязательные этапы обработки текста.