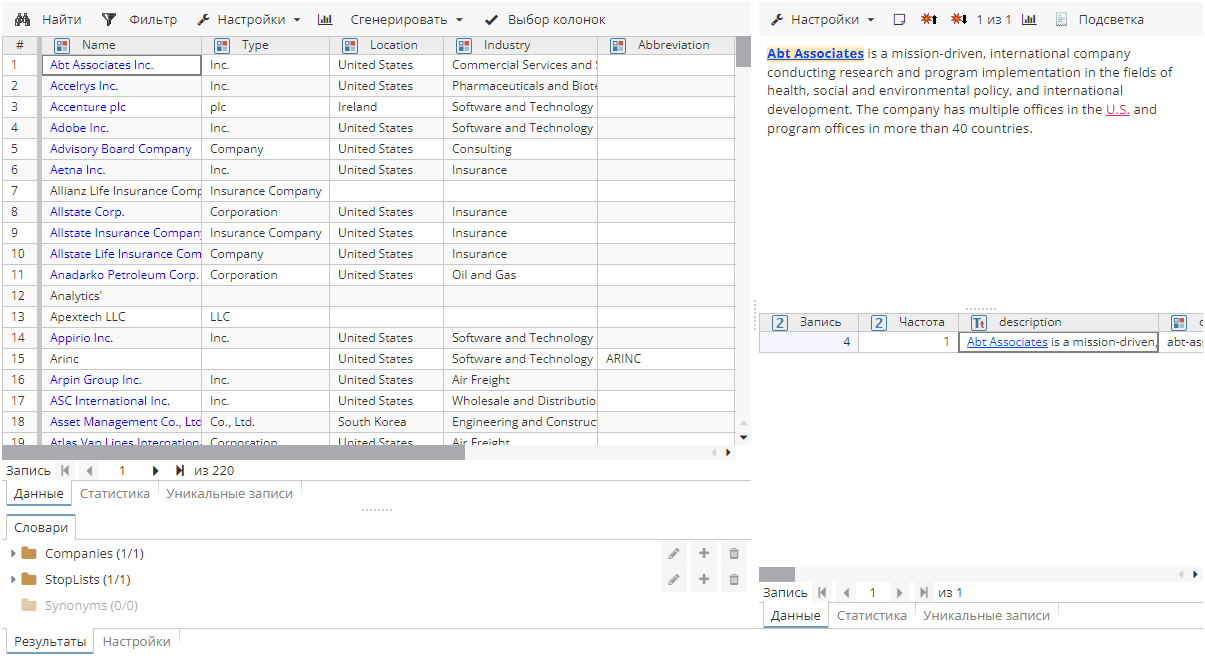
Постобработка
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
1. Aggregation (Агрегирование)
Постобработчик Aggregation (Агрегирование) позволяет объединять сущности с частично совпадающими атрибутами, в результате чего происходит объединение всей доступной информации об извлеченных сущностях. Объединение происходит, если некоторые атрибуты сущностей совпадают, а другие при этом не противоречат друг другу.
В поле Атрибут указываются имена атрибутов сущностей, найденных правилом. Имена атрибутов доступны в выпадающем списке. Пользователь может добавить те атрибуты, которые необходимо сравнить для того, чтобы собрать всю информацию о сущности.
Поле Режим объединения определяет режим такого сравнения, подробное описание которого представлено в разделе ниже.
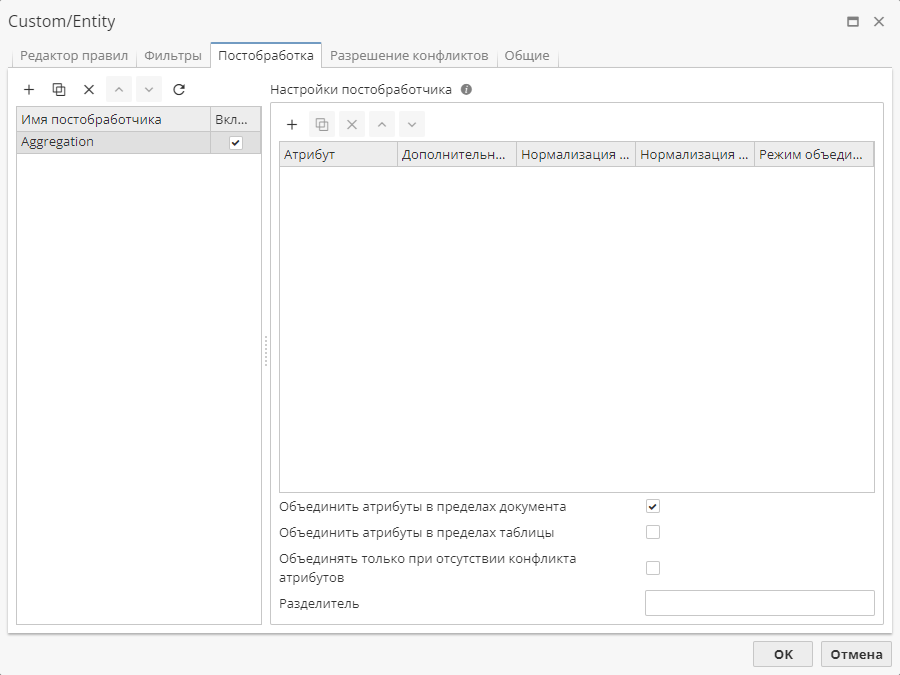
К каждому атрибуту можно применить Дополнительный поиск и настроить параметры Нормализации регистра и Нормализации формы, которые описаны далее.
Правило 1 извлекает упоминания людей и находит сущность с четырьмя атрибутами:
-
Имя
-
Фамилия
-
Возраст
-
Профессия
/* Пример XPDL-правила, позволяющего извлекать имена людей и атрибуты */
rule: Правило 1
{
query: {phrase(3,{optional(regex("\d+?-year-old"))}:age,
{optional(dictword(HumanNames, "Type=first name"))}:first,
{dictword(HumanNames, "Type=surname")}:last,
{optional(phrase(repeat(1,3,lemma(adjective|noun)),orn(physicist, actress, violinist)))}:prof)
}:m
result: Match = $m
attribute: Имя = $first
attribute: Фамилия = $last
attribute: Профессия = $prof
attribute: Возраст = toint(regex($age,"(\d+)","\1"))
}
Настройки агрегирования примера выглядят следующим образом:
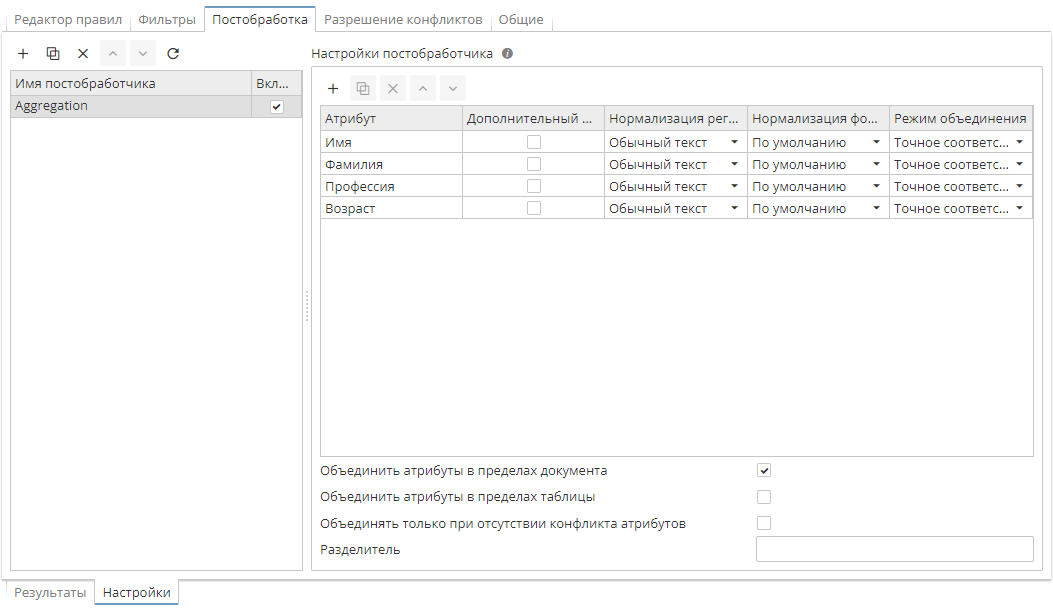
Атрибуты Имя, Фамилия, Профессия и Возраст добавляются в список, при этом выполнение агрегирования будет возможно только для тех сущностей, которые не имеют конфликтов ни по одному из добавленных атрибутов.
Текст примера:
Сущности до агрегирования:
Имя |
Фамилия |
Профессия |
Возраст |
Frequency (Частота) |
Albert |
Einstein |
German-born theoretical physicist |
1 |
|
Albert |
Einstein |
42 |
1 |
Сущности после агрегирования:
Имя |
Фамилия |
Профессия |
Возраст |
Frequency (Частота) |
Albert |
Einstein |
German-born theoretical physicist |
42 |
2 |
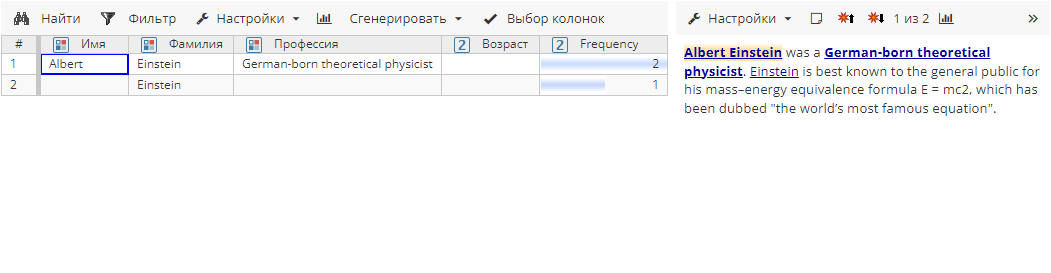
Атрибуты Имя и Фамилия совпадают, а атрибуты Профессия и Возраст не противоречат друг другу, поэтому две сущности, обнаруженные правилом, объединяются.
Правило 1 без выполнения постобработки находит следующие атрибуты сущности:
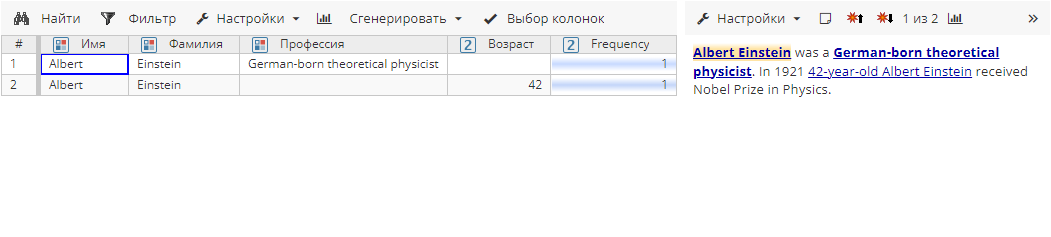
| Обратите внимание, что некоторые колонки были вручную скрыты из результатов с помощью меню Выбор колонок. |
Если постобработчик Aggregation включен, происходит объединение атрибутов сущностей:
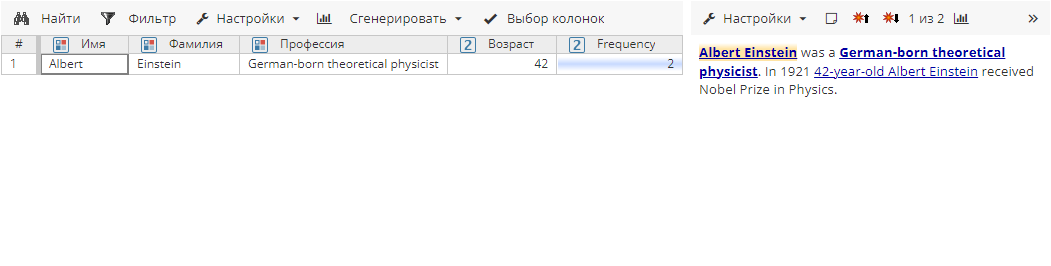
(2) Пример 2:
Используется то же правило, те же атрибуты и настройки агрегирования, что и в Примере 1.
Текст примера:
Сущности до агрегирования:
Имя |
Фамилия |
Профессия |
Возраст |
Frequency (Частота) |
Albert |
Einstein |
German-born theoretical physicist |
1 |
|
Albert |
Einstein |
good violinist |
1 |
|
Albert |
Einstein |
42 |
1 |
Сущности после агрегирования:
Имя |
Фамилия |
Профессия |
Возраст |
Frequency (Частота) |
Albert |
Einstein |
German-born theoretical physicist |
1 |
|
Albert |
Einstein |
good violinist |
1 |
|
Albert |
Einstein |
42 |
1 |
Атрибуты Имя и Фамилия совпадают, конфликт для атрибута Возраст отсутствует, но атрибуты Профессия противоречат друг другу, поэтому объединение не выполняется, даже если включен постобработчик Aggregation:
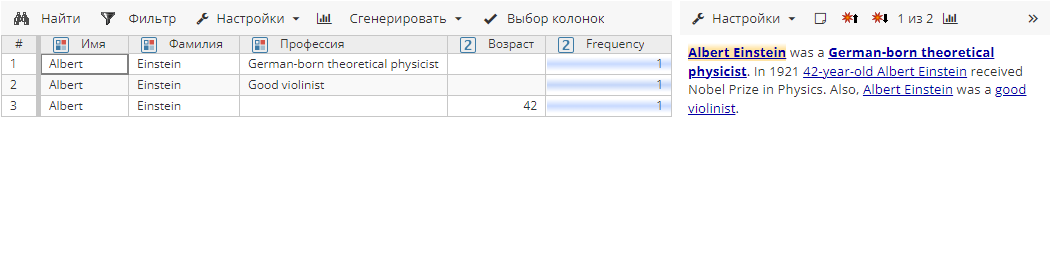
1.1.1 Область
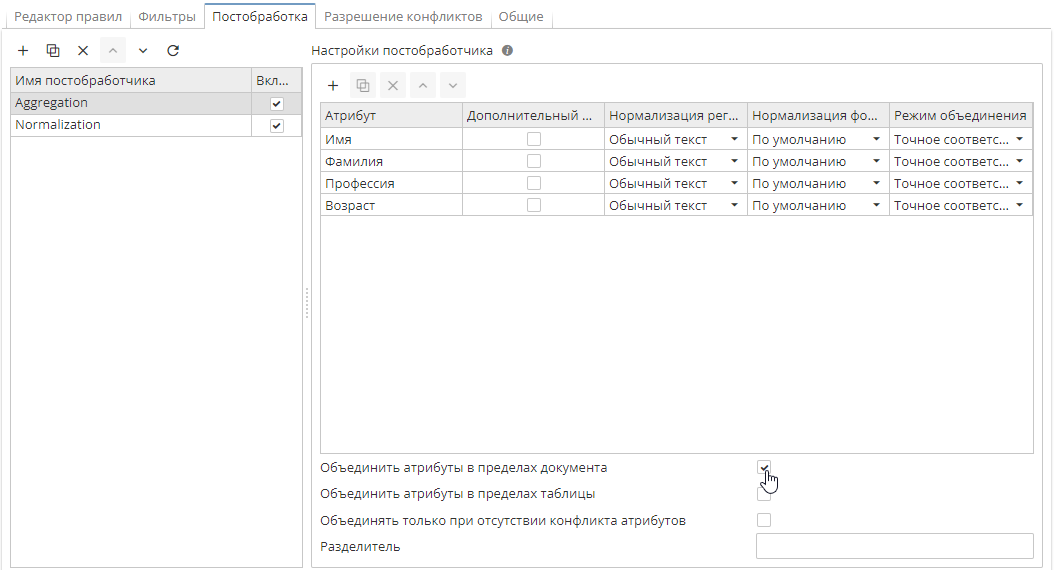
Пользователи могут выбрать область агрегирования: агрегирование может применяться к отдельному документу или к целой таблице данных. Опция Объединить атрибуты в пределах документа позволяет объединить атрибуты сущностей, найденные правилом в пределах одной записи. Опция Объединить атрибуты в пределах таблицы позволяет объединить атрибуты сущностей, найденные в одном или разных документах в таблице данных.
Для того, чтобы указать область агрегирования, отметьте галочкой соответствующие опции под списком атрибутов:
(3) Пример 3:
Используется то же правило, те же атрибуты и настройки агрегирования, что и в Примере 1.
Текст примера:
Имена собственные Einstein и Albert Einstein встречаются в одном и том же документе, опция Объединить атрибуты в пределах документа включена, в результате чего Einstein и Albert Einstein будут объединены:
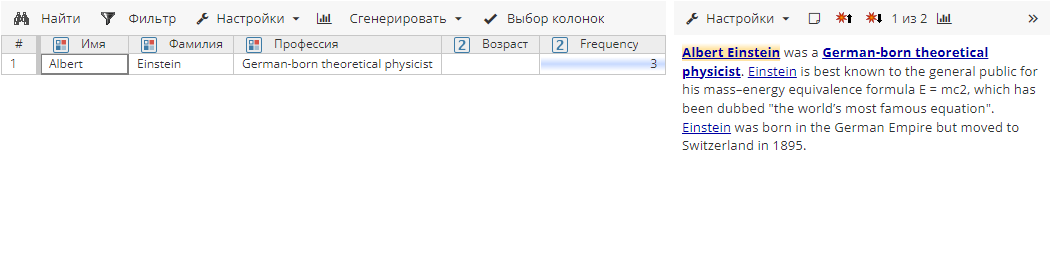
Однако если Einstein и Albert Einstein встречаются в разных документах, объединение атрибутов не произойдет.
Текст 1:
Текст 2:
В этом случае Einstein и Albert Einstein из Текста 1 будут объединены, но Einstein из Текста 2 останется без изменений.
Для того, чтобы объединить сущности из разных документов, отметьте галочкой опцию Объединить атрибуты в пределах таблицы.
| Если включены обе эти опции, операция объединения выполняется в два этапа: сначала объединяются сущности в пределах одного документа, а затем – в пределах всей таблицы. Если обе опции отключены, объединение сущностей не выполняется. |
По умолчанию постобработчик Aggregation учитывает только те атрибуты, которые добавлены в список. Даже при конфликте прочих атрибутов он агрегирует информацию только о добавленных пользователем атрибутах.
Правило 2 извлекает упоминания возбудителей инфекций и создает сущность с тремя атрибутами:
-
Возбудитель
-
Аббревиатура
-
Очаг
/* Пример XPDL-правила для извлечения упоминаний возбудителей инфекций */
rule: Правило 2
{
query: {phrase(3,{"Methicillin-resistant Staphylococcus aureus"}:agent or {MRSA}:abbr,
{optional(case(upper))}:abbr,
{optional("peg site" or "left picc site")}:site)
}:m
result: Match = $m
attribute: Возбудитель = $agent
attribute: Аббревиатура = $abbr
attribute: Очаг = $site
}
Текст 1:
Текст 2:
Текст 3:
Правило 2 без выполнения постобработки находит следующие атрибуты сущностей:
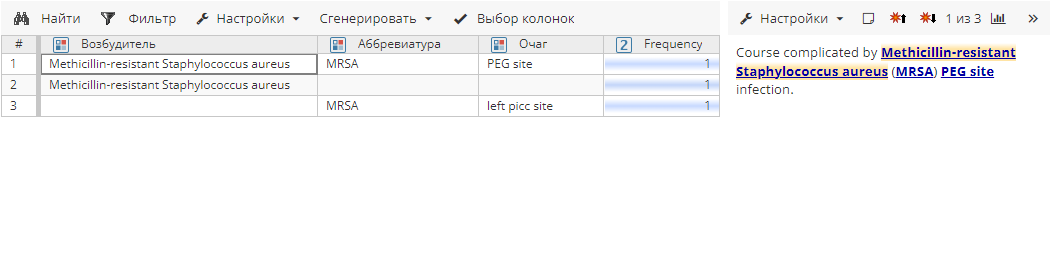
Первый текст предоставляет нам значения для атрибутов Возбудитель и Аббревиатура, второй – только для атрибута Возбудитель, а третий – только для атрибута Аббревиатура. Очевидно, что для одного и того же возбудителя инфекции используется одинаковая аббревиатура, поэтому мы можем использовать информацию из первого текста для дополнения сущностей из двух других текстов. Несмотря на конфликт для атрибута Очаг, он не является релевантным, т.к. не влияет на имя возбудителя и его аббревиатуру. Следовательно, в список в разделе Настройки постобработчика мы добавим только атрибуты Возбудитель и Аббревиатура.
Настройки агрегирования примера выглядят следующим образом:
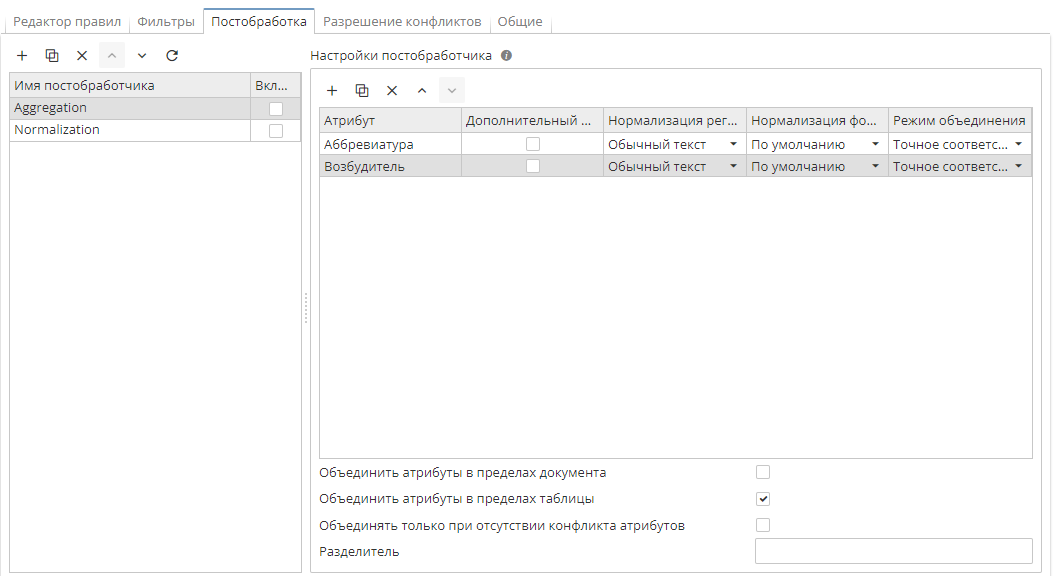
Сущности после агрегирования:
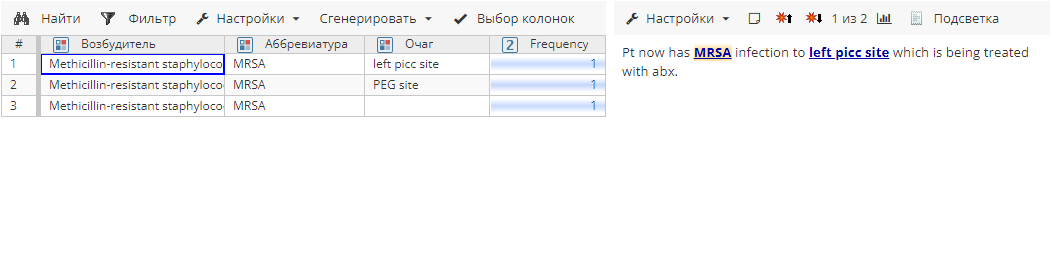
Постобработчик заполнил пустые поля Возбудитель и Аббревиатура без учета конфликтов в колонке Очаг.
Однако иногда необходимо выполнить агрегирование информации только при отсутствии конфликтов атрибутов.
(5) Пример 5:
Правило 3 извлекает упоминания людей и создает сущность с тремя атрибутами:
-
Имя
-
Фамилия
-
Атрибут
/* Пример правила XPDL, которое извлекает упоминания людей и атрибуты */
rule: Правило 3
{
query: {phrase(3,{orn("USA president",wife)}:attr,
{optional(dictword(HumanNames, "Type=first name"))}:first,
{dictword(HumanNames, "Type=surname")}:last)
}:m
result: Match = $m
attribute: Имя = $first
attribute: Фамилия = $last
attribute: Атрибут = $attr
}
Текст примера:
Правило 3 без выполнения постобработки находит следующие атрибуты сущностей:
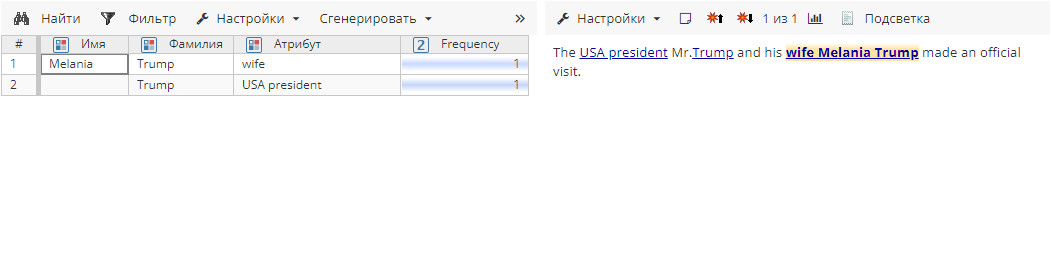
Если следовать логике Правила 1, необходимо выполнить агрегирование информации об обнаруженных сущностях, например, дополнить атрибуты сущностей при совпадении имен. Таким образом, в список в разделе Настройки постобработчика мы добавим атрибуты Имя и Фамилия, а выполнение агрегирования будет возможно только для тех сущностей, которые не имеют конфликтов по указанным атрибутам.
Сущности после агрегирования:
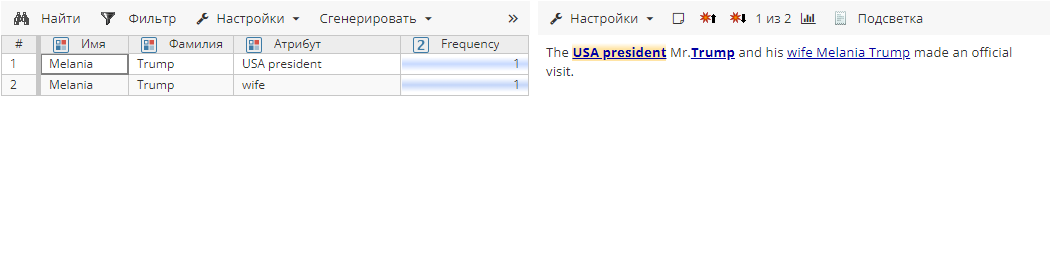
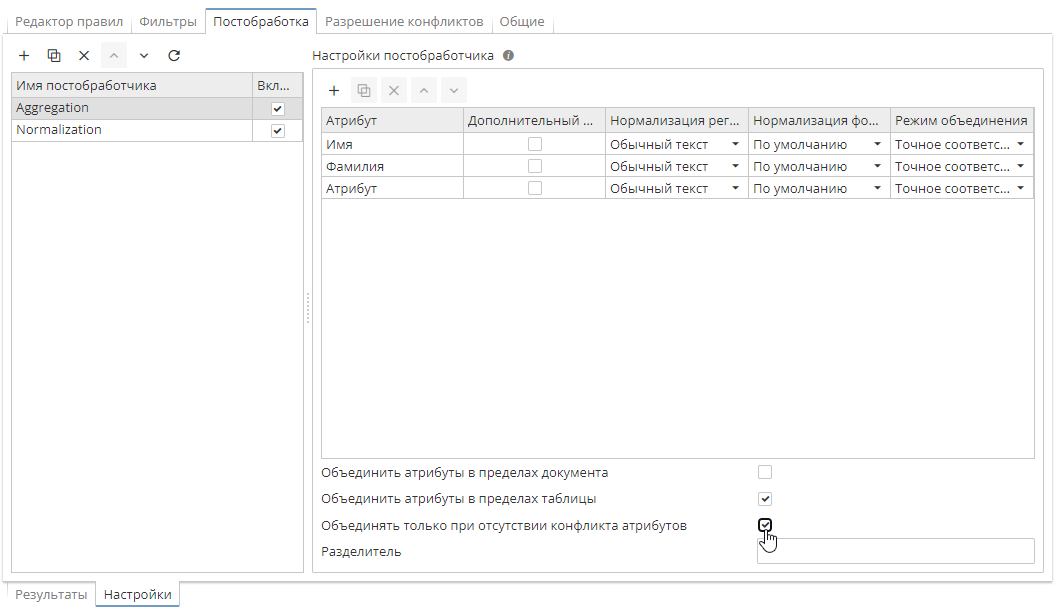
В данном случае USA president Trump и wife Melania Trump объединились в Melania Trump, USA president и Melania Trump, wife, поскольку имеют одинаковое значение атрибута Фамилия. Проблема заключается в том, что постобработчик Aggregation игнорирует атрибуты, не включенные в список. Во избежание подобных ошибок необходимо отметить галочкой опцию Объединять только при отсутствии конфликта атрибутов. В нашем случае при включении данной опции сущности не будут объединены по причине конфликта значений для колонки Атрибут.
Настройки агрегирования примера выглядят следующим образом:
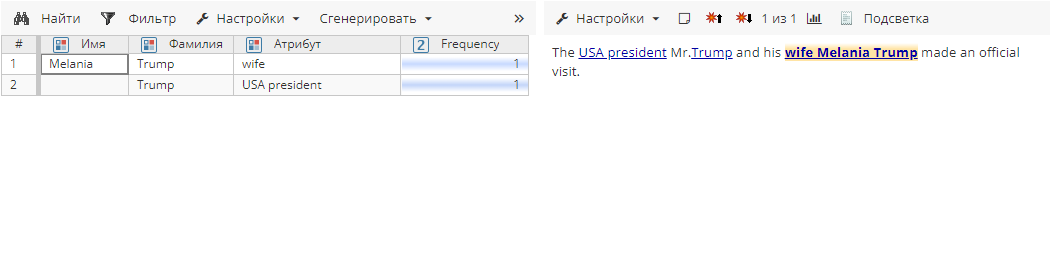
Сущности после агрегирования (с включенной опцией Объединять только при отсутствии конфликта атрибутов):
1.1.2 Дополнительный поиск
Дополнительный поиск позволяет объединить разные формы одного и того же атрибута в документе. Таким образом можно объединить атрибуты, которые изначально не были обнаружены правилом.
(6) Пример 6:
Используется то же правило, те же атрибуты и настройки агрегирования, что и в Примере 1.
Для атрибута Имя включен режим Дополнительный поиск:
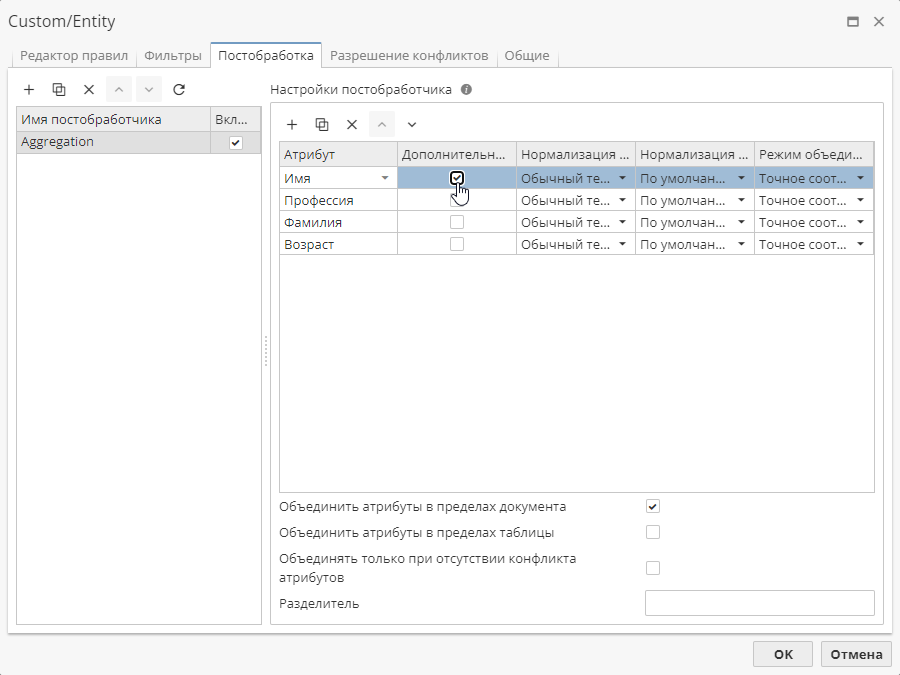
Текст примера:
Сущности до агрегирования:
Имя |
Фамилия |
Профессия |
Возраст |
Frequency (Частота) |
Albert |
Einstein |
German-born theoretical physicist |
1 |
Сущности после агрегирования:
Имя |
Фамилия |
Профессия |
Возраст |
Frequency (Частота) |
Albert |
Einstein |
German-born theoretical physicist |
2 |
Если Дополнительный поиск выключен, результат узла будет следующим:
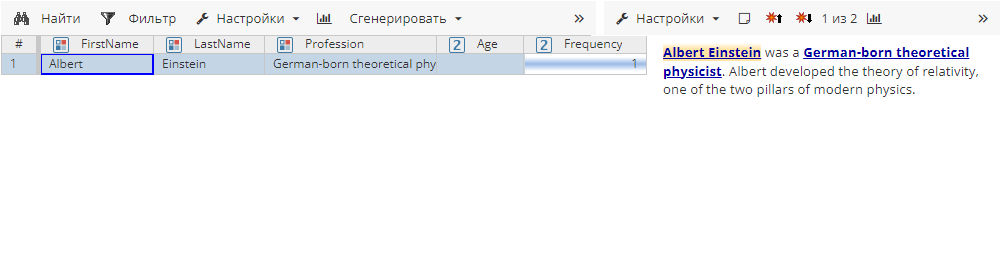
Если Дополнительный поиск включен, результат изменится:
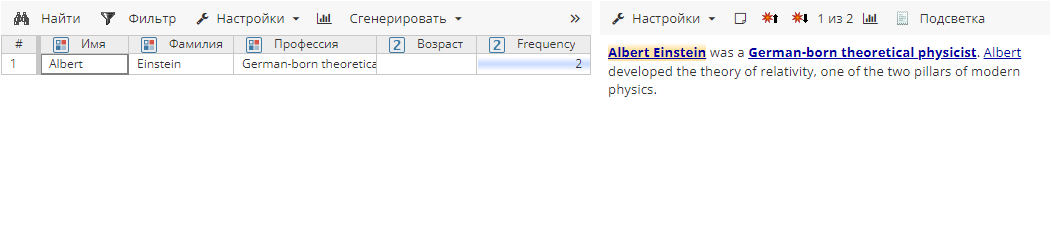
Таким образом, опция Дополнительный поиск используется для поиска случаев употребления значения атрибута, которые не были найдены с помощью правила.
1.1.3 Настройки нормализации регистра
Таблица Настройки постобработчика включает раздел Нормализация регистра, с помощью которого пользователи могут может выбрать стратегию нормализации регистра для каждого атрибута.
Доступные стратегии можно разделить на два вида – стандартные и специальные. Стандартные стратегии нормализации регистра имеют общий характер, в то время как специальные стратегии нормализации регистра предназначены для сущностей конкретного типа. Например, если атрибутом является имя компании, рекомендуется выбрать стратегию Companies в выпадающем списке. Нормализацию регистра для атрибута можно отключить, сохранив его исходную форму.
Ниже приводится описание стратегий нормализации регистра. Обратите внимание, что специальные стратегии нормализации регистра разработаны с учетом норм и особенностей конкретного языка. Приведенные примеры актуальны только для английского языка.
Стратегии нормализации регистра:
Стандартные стратегии нормализации регистра:
-
Начальные заглавные буквы – преобразует начальный символ значения атрибута в верхний регистр, например: canada → Canada;
-
Строчные буквы – преобразует значения атрибута в нижний регистр, например: President → president;
-
Заглавные буквы – преобразует значения атрибута в верхний регистр, например: u.s. → U.S.
Специальные стратегии нормализации регистра:
-
Заголовок – нормализация регистра, характерная для заголовков СМИ, например: Parliament backs a new constitution → Parliament Backs a New Constitution.
-
Обычный текст – нормализация регистра, характерная для обычного текста, например: Parliament backs a new constitution → Parliament backs a new Constitution.
-
Companies – нормализация регистра, характерная для названий компаний, например: Microsoft corp. → Microsoft Corp.
-
Organizations – нормализация регистра, характерная для названий организаций, например: AMERICAN ACADEMY OF NEUROLOGY → American Academy of Neurology.
-
People – нормализация регистра, характерная для имен людей, например: george bush → George Bush
-
GeoAdministrative – нормализация регистра, характерная для названий географических объектов и административных единиц, например: Olmsted county → Olmsted County.
-
Landforms – нормализация регистра, характерная для названий элементов ландшафта, например: Los Angeles harbor → Los Angeles Harbor.
-
Facilities – нормализация регистра, характерная для названий локаций и мест в городе, например: John F. Kennedy international airport → John F. Kennedy International Airport.
-
Technologies – нормализация регистра, характерная для обозначения технологий, патентов и технологических продуктов, например: bluetooth → Bluetooth.
-
Sentence– нормализация регистра как в предложениях: преобразует начальный символ первого слова в верхний регистр, например: canadian specialist → Canadian specialist.
Отключение нормализации регистра:
-
Без нормализации – сохраняется исходное форматирование.
1.1.4 Настройки нормализации формы
Нормализация формы преобразует найденные формы слов в исходном тексте в начальную форму. Например, во фразе "предложение Ивана" будет разумно преобразовать значение атрибута Имя в начальную форму "Иван", что облегчит последующий анализ.
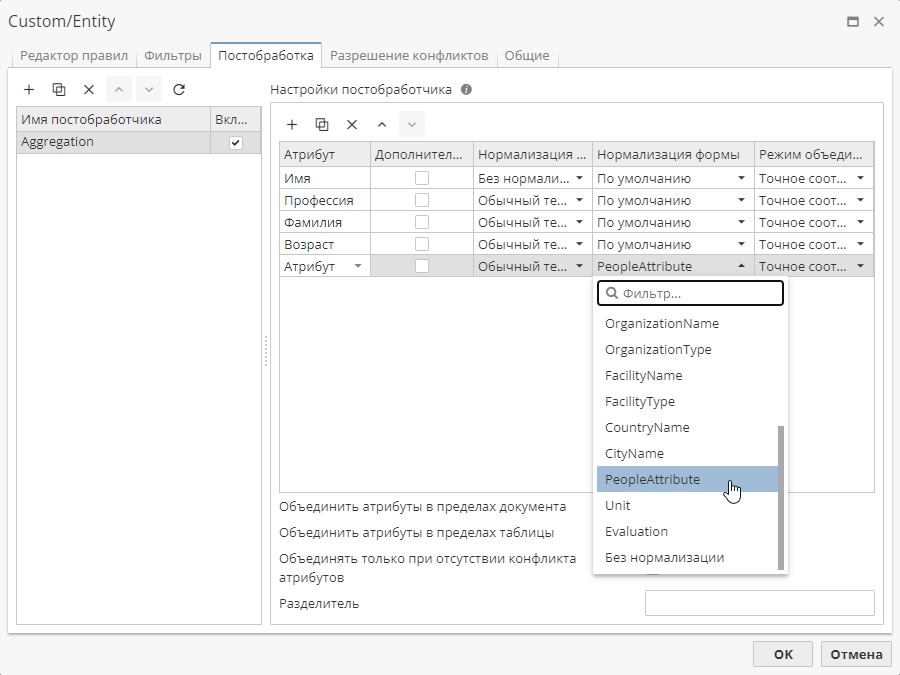
Для каждого типа атрибутов сущностей применяется своя стратегия нормализации формы. Так, например, название организации "Children’s of Alabama" не должно быть преобразовано в "Children of Alabama". Именно поэтому настройки нормализации формы предлагают ряд специальных стратегий в зависимости от типа сущностей. Прежде всего, все стратегии нормализации формы зависят от словарных статей, однако существуют и некоторые общие принципы. При необходимости можно полностью отключить нормализацию формы.
Ниже приводится описание стратегий нормализации формы. Обратите внимание, что настройки нормализации формы разработаны с учетом норм и особенностей конкретного языка. Приведенные ниже примеры и параметры актуальны только для английского языка.
Стратегии нормализации формы:
Люди
-
FirstName – сохраняется начальная форма существительного, например: John’s → John;
-
MiddleName – сохраняется начальная форма существительного, например: Anna Maria’s → Anna Maria;
-
LastName – сохраняется начальная форма существительного, например: Smiths → Smith;
-
PeopleAttribute – сохраняется исходная форма слова, например: Company’s CEO → Company’s CEO.
Компании
-
CompanyName:
-
Существительное: сохраняются формы множественного числа и притяжательного падежа
-
Прилагательное: сохраняется степень сравнения
-
Глагол: сохраняется форма глагола, например: John Wiley & Sons → John Wiley & Sons
-
-
CompanyType:
-
Существительное: сохраняются формы множественного числа и притяжательного падежа
-
Глагол: сохраняется форма глагола, например: Limited → Limited
-
Географические объекты и административные единицы
-
GeoAdministrative – сохраняется начальная форма существительного, например: Wisconsin’s → Wisconsin;
-
Landforms – сохраняется начальная форма существительного, например: Great Salt Lake’s → Great Salt Lake;
-
CountryName – притяжательный падеж существительных нормализуется, форма множественного числа сохраняется, например: Germany’s → Germany, United States → United States;
-
CityName – притяжательный падеж существительных нормализуется, форма множественного числа сохраняется, например: Bristol’s → Bristol, Athens → Athens.
Объекты
-
FacilityName – форма множественного числа существительных нормализуется, притяжательный падеж сохраняется, например: St. Peter’s Square → St. Peter’s Square;
-
FacilityType – сохраняется начальная форма существительного, например: streets → street.
Организации
-
OrganizationName:
-
Существительное: сохраняются формы множественного числа и притяжательного падежа
-
Глагол: сохраняется форма глагола, например: Children’s Hospital of Philadelphia → Children’s Hospital of Philadelphia.
-
-
OrganizationType: сохраняется начальная форма существительного, например: hotels → hotel.
Отключение нормализации и нормализация формы по умолчанию
-
Без нормализации – сохраняется исходная форма слова;
-
По умолчанию – сохраняется начальная форма.
1.1.5 Настройки режима объединения
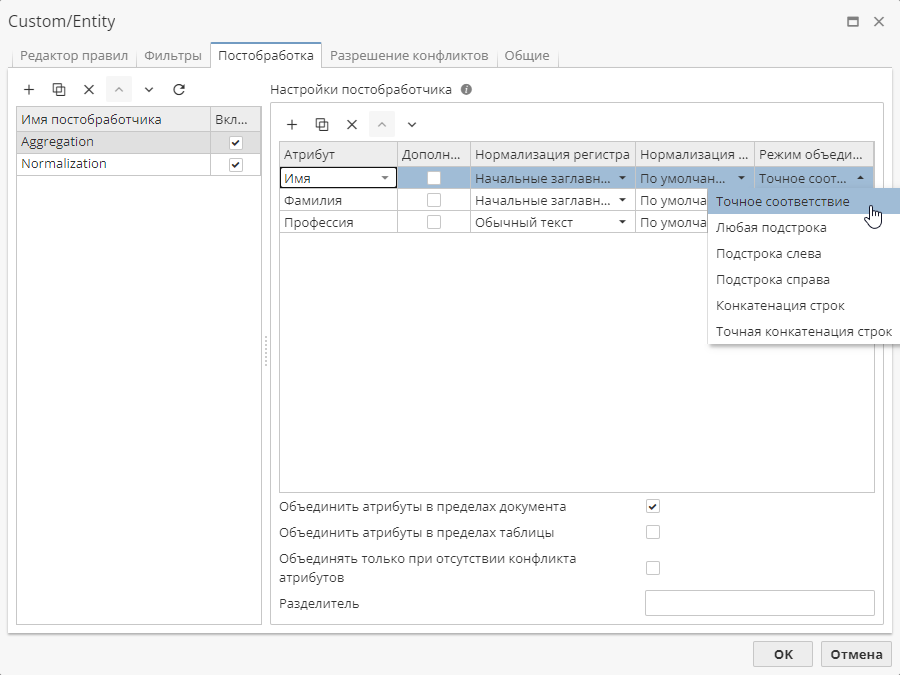
Поле Режим объединения используется для указания условия сравнения атрибутов. Нажмите на текущее значение для отображения списка доступных опций:
-
Точное соответствие – объединение происходит в случае, если имеется точное соответствие значений атрибутов (например, "President" и "President");
-
Любая подстрока – объединение происходит в случае, если одно значение атрибута является подстрокой другого атрибута (например, "President" и "the President of the USA");
-
Подстрока слева – объединение происходит в случае, если одно значение атрибута является подстрокой другого атрибута с левой стороны (например, "President" и "President of the USA");
-
Подстрока справа – объединение происходит в случае, если одно значение атрибута является подстрокой другого атрибута с правой стороны (например, "President" и "the President");
-
Конкатенация строк – при объединении выполняется конкатенация только совпадающих значений атрибутов (например, "Trump, politician" + "Trump, president" → "Trump, politician; president");
-
Точная конкатенация строк – при объединении выполняется конкатенация всех значений атрибутов (например, "Company; Car manufacturer" → "Company, car manufacturer").
| Обратите внимание, что мы сняли флажок со колонки Match в меню Выбор колонок. |
(7) Пример 7
Правило 4 извлекает упоминания людей и создает сущность с тремя атрибутами:
-
Имя
-
Фамилия
-
Профессия
/* Пример XPDL-правила, которое извлекает имена людей и атрибуты */
rule: Правило 4
{
query: {phrase(0, {optional(the)}:prof,{orn(President, Politician)}:prof, {optional("of the USA")}:prof,
{optional("Donald")}:first, {"Trump"}:last)
}:m
result: Match = $m
attribute: Имя = $first
attribute: Фамилия = $last
attribute: Профессия = $prof
}
Настройки агрегирования примера выглядят следующим образом:
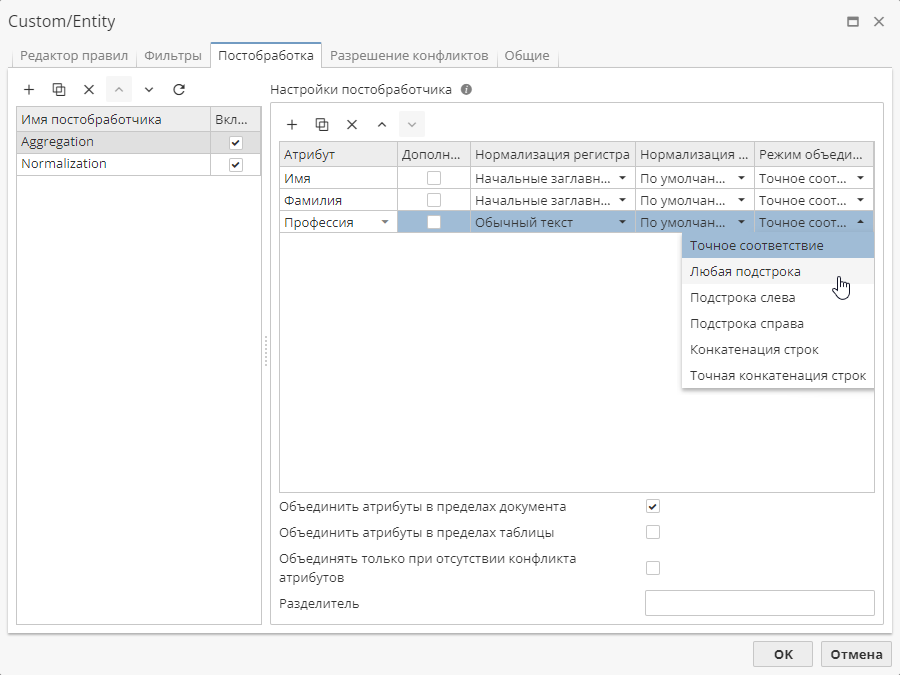
Атрибуты Имя, Фамилия и Профессия добавлены в таблицу Настройки постобработчика. Для атрибутов Имя и Фамилия выбран режим режим Точное соответствие, а для атрибута Профессия – Любая подстрока. Следовательно, если одно значение атрибута Профессия является подстрокой другого значения, а между атрибутами Имя и Фамилия нет конфликта, эти сущности будут объединены.
Текст примера:
Сущности до агрегирования:
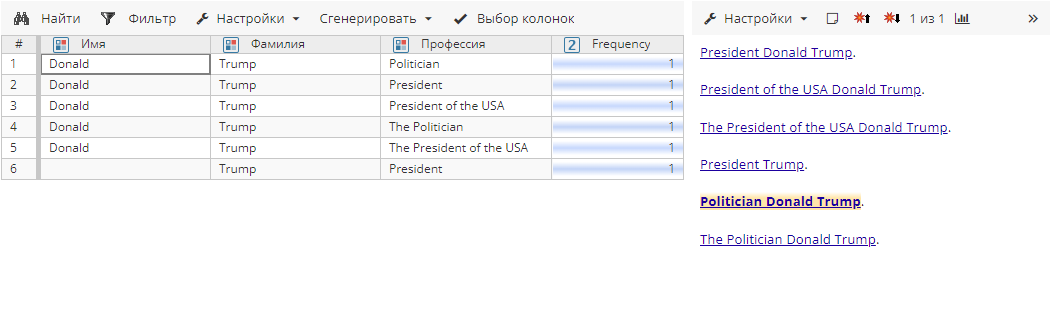
Сущности после агрегирования в режиме Точное соответствие для атрибута Профессия:
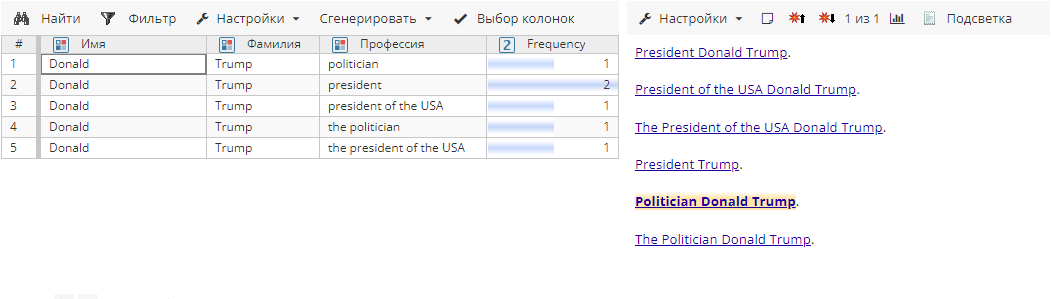
Сущности после агрегирования в режиме Любая подстрока для атрибута Профессия:
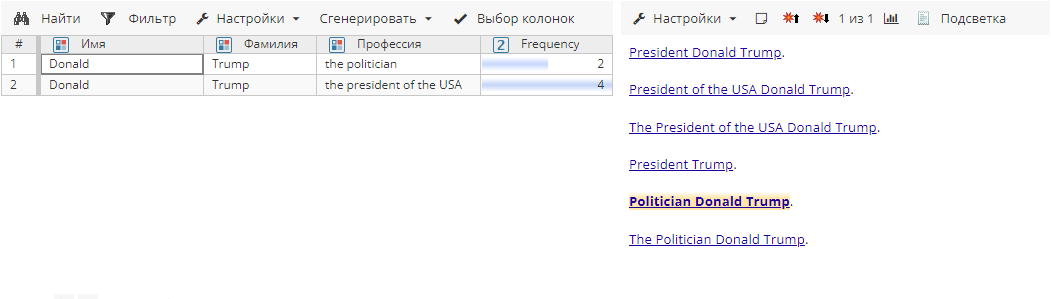
Сущности после агрегирования в режиме Подстрока слева для атрибута Профессия:
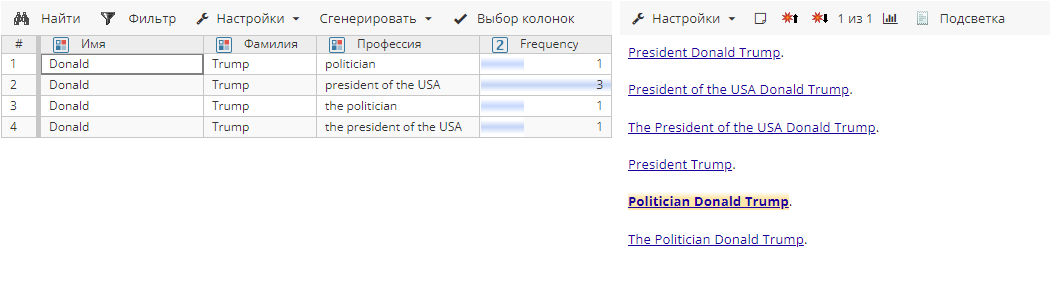
Сущности после агрегирования в режиме Подстрока справа для атрибута Профессия:
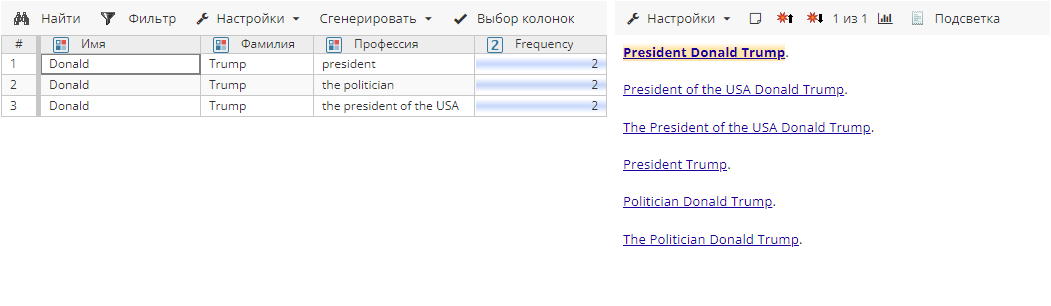
Сущности после агрегирования в режиме Конкатенация строк для атрибута Профессия:
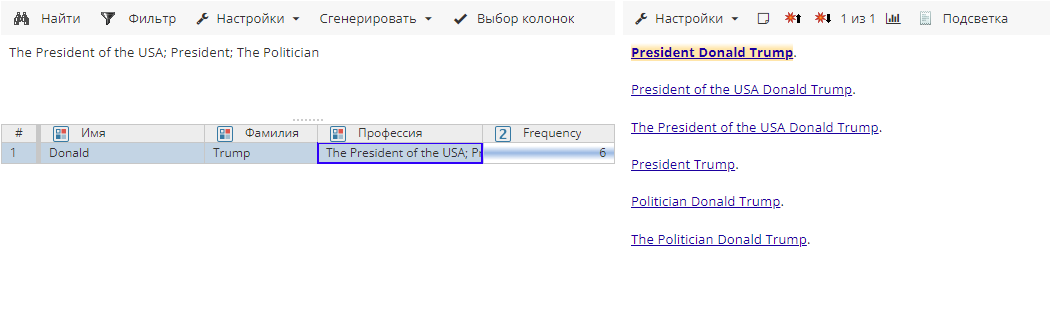
Обратите внимание, что необходимо установить разделитель в соответствующем поле настроек постобработчика: в примерах выше и ниже мы используем точку с запятой и пробел в качестве разделителя.
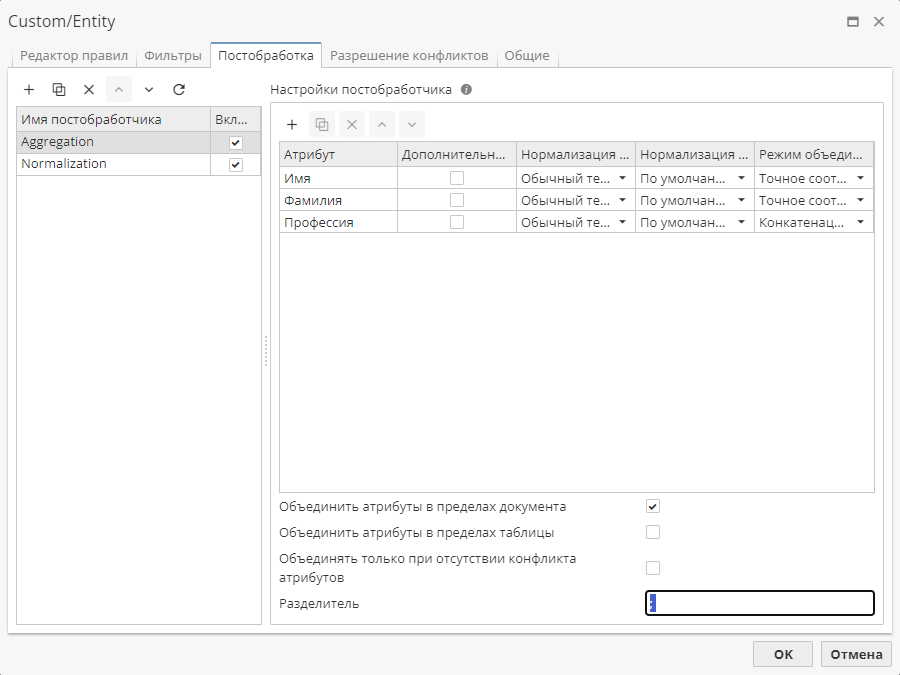
Сущности после агрегирования в режиме Точная конкатенация строк для атрибута Профессия:
2. Normalization (Нормализация)
Постобработчик Normalization (Нормализация) позволяет изменять форматирование атрибутов сущностей в отчете узла. Данный постобработчик характеризуется следующими параметрами: Атрибут, Настройки нормализации и Описание настроек.
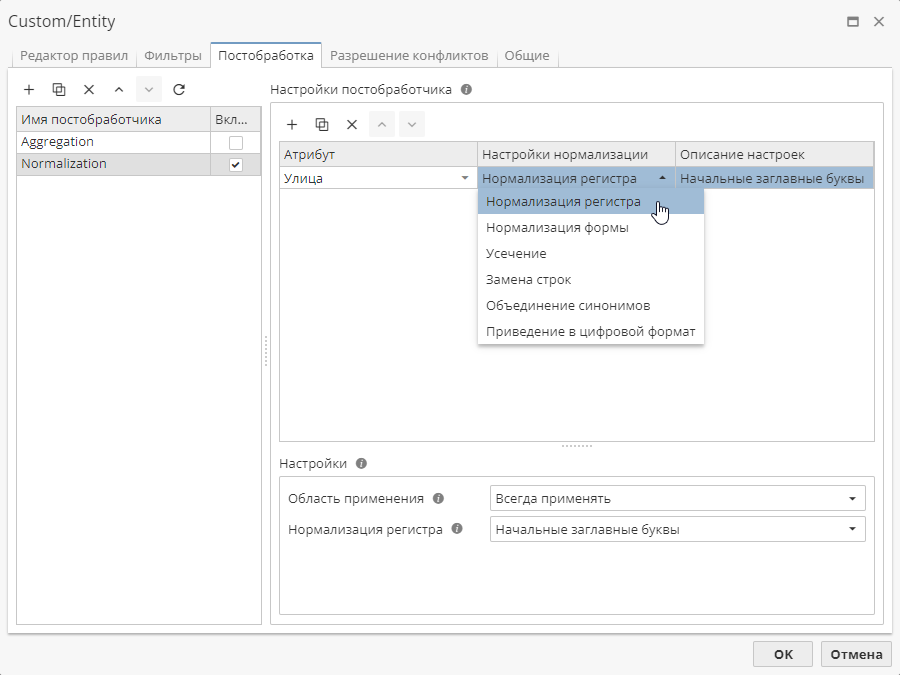
В поле Атрибут содержатся имена атрибутов сущностей, которые были обнаружены правилом. Необходимое значение можно выбрать в выпадающем списке.
В поле Настройки нормализации укажите режим нормализации: Нормализация регистра (см. здесь), Нормализация формы (см. в данном разделе), Усечение (см. раздел 2.1.1), Замена строк (см. раздел 2.1.2), Приведение в цифровой формат (см. раздел 2.1.3), Объединение синонимов (см. раздел 2.1.4).
| Настройки Нормализации регистра и Нормализации формы могут быть установлены либо с помощью постобработчика Агрегирования, либо с помощью постобработчика Нормализация. |
Поле Описание настроек заполняется автоматически в зависимости от выбранных опций нормализации и используется в справочных целях.
2.1.1 Настройки усечения
Усечение позволяет удалять символы, принадлежащие к конкретным категориям, из результатов работы правила. Всего доступно пять категорий: Пробел (пробелы между токенами), Пунктуация (знаки пунктуации), Цифра (числовые символы), Буква (алфавитные символы) и StopList (слова и фразы, представленные в соответствующем словаре). Усечение применяется только к атрибутам строкового типа. Часть строки, подлежащая усечению, определяется с помощью привязки. Доступны следующие типы привязки:
-
Слева – удаляет символы указанной категории в начале строки, например: 1107 Broad St → Broad St;
-
Справа – удаляет символы указанной категории в конце строки, например: Broad St 028648360 → Broad St;
-
Слева и справа – удаляет символы указанной категории в начале и в конце строки, например: 1107 Broad St 028648360 → Broad St;
-
Строка целиком – удаляет символы указанной категории в рамках целой строки, например: 1501 Main Street, Suite 17 Tewksbury, MA 01876-2061 → Main Street, Suite Tewksbury, MA -.
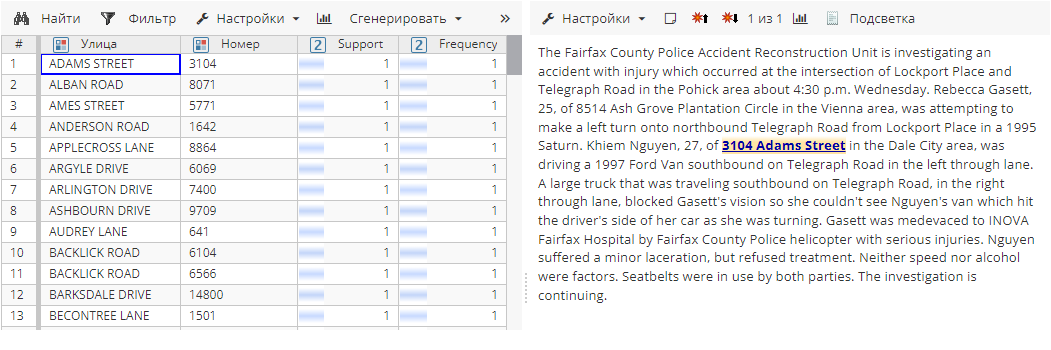
Пример результатов усечения цифровых символов с использованием опции усечения Слева представлен на скриншоте ниже:
2.1.2 Настройки замены строк
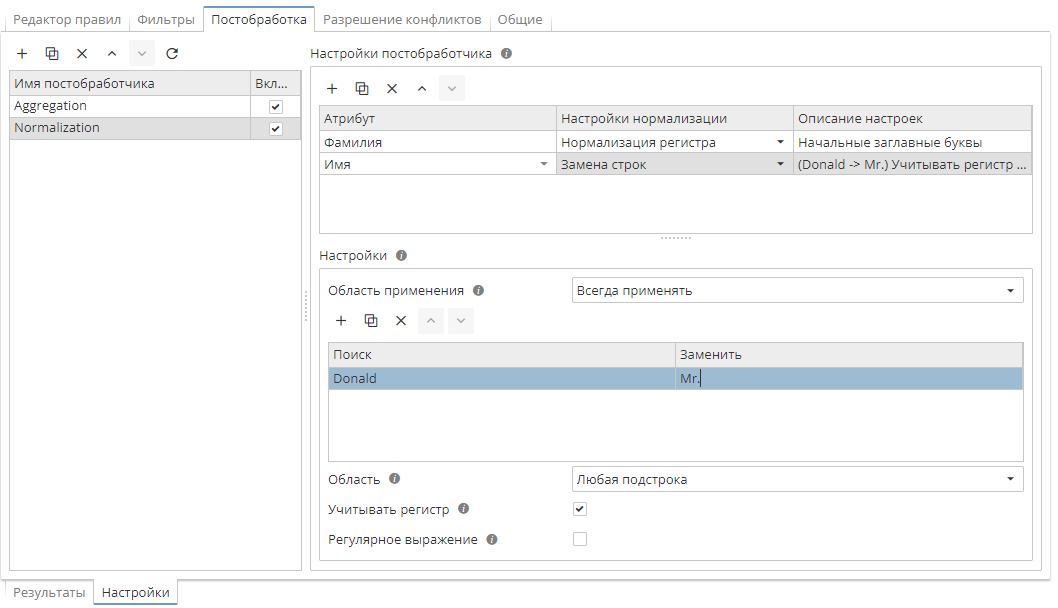
Замена строк позволяет использовать замены для выбранного атрибута. Данная опция также поддерживает использование регулярных выражений.
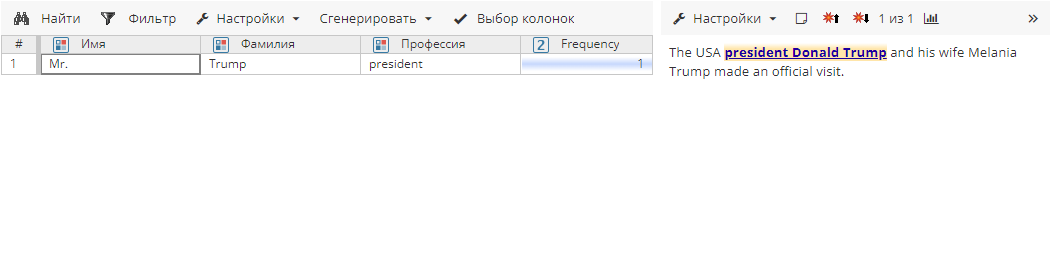
Пример замены строки представлен на скриншоте ниже:
2.1.3 Настройки приведения в цифровой формат
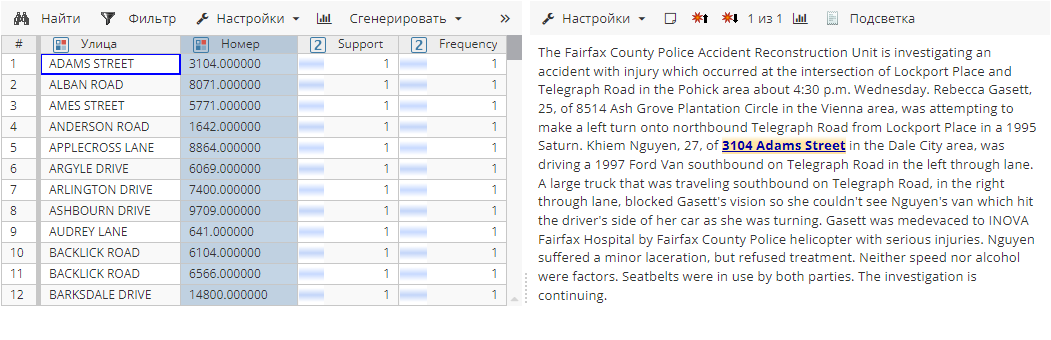
Приведение в цифровой формат преобразует числовые значения в цифровой формат, например: four million → 4000000:
2.1.4 Настройки объединения синонимов
Объединение синонимов позволяет объединить атрибуты сущностей на основе их семантического сходства, позволяя обобщить результаты для целого класса объектов. Атрибуты могут быть объединены при условии, что они принадлежат к одному классу в словаре синонимов.
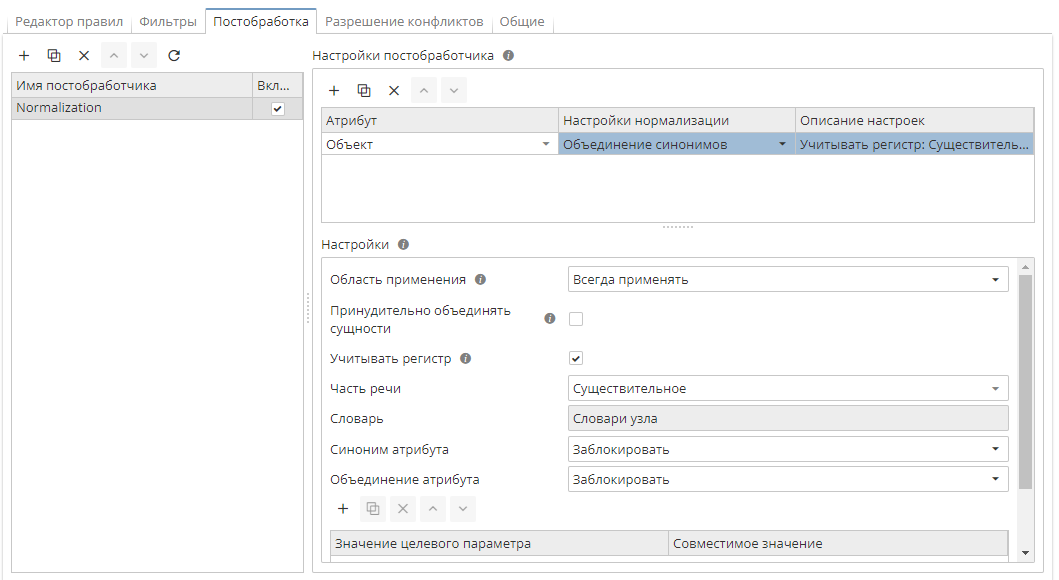
Для корректной работы режима Объединение синонимов убедитесь в том, что узел настроен на использование словаря синонимов (в окне настроек узла выберите вкладку Словари).
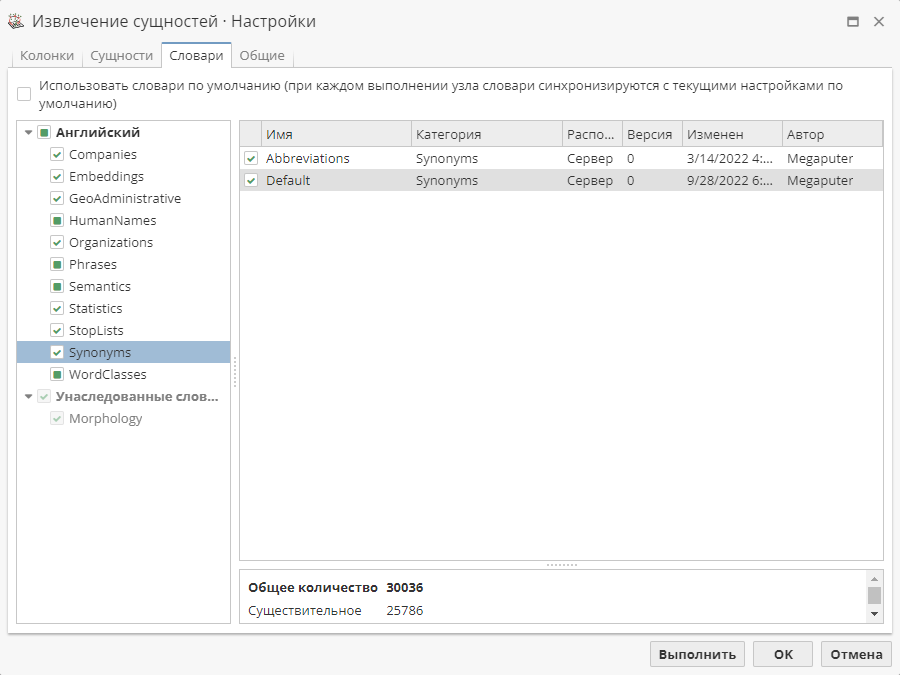
(8) Пример 8
В словаре синонимов слова car и motorcar зарегистрированы как синонимы.
Текст примера:
До объединения синонимов:
Объект |
Frequency (Частота) |
Car |
1 |
Motorcar |
1 |
После объединения синонимов:
Объект |
Frequency (Частота) |
Car |
2 |
Например, правило может найти следующие атрибуты:
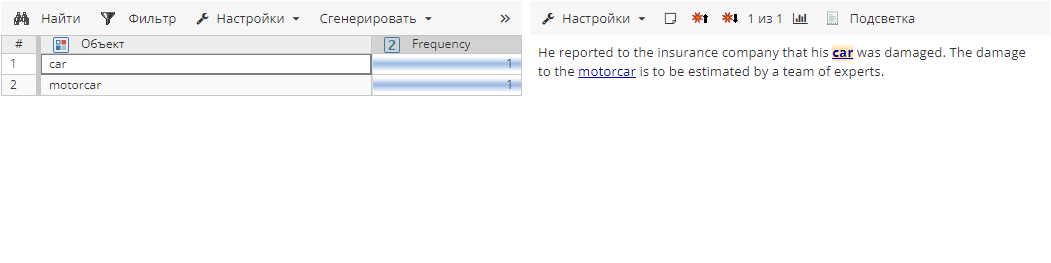
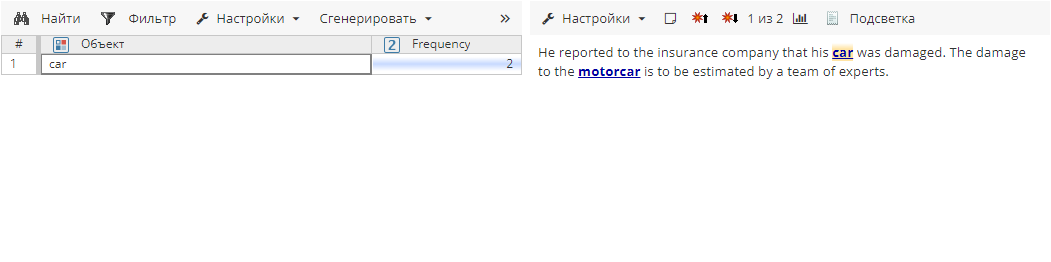
Если Объединение синонимов включено, результат будет другим:
3. StopList (Список стоп-слов)
Постобработчик StopList (Список стоп-слов) позволяет отфильтровать ненужные слова и фразы, например, слова, не имеющие самостоятельного лексического значения (артикли, предлоги и др.) или любой другой "шум", который может не относится к атрибуту сущности.
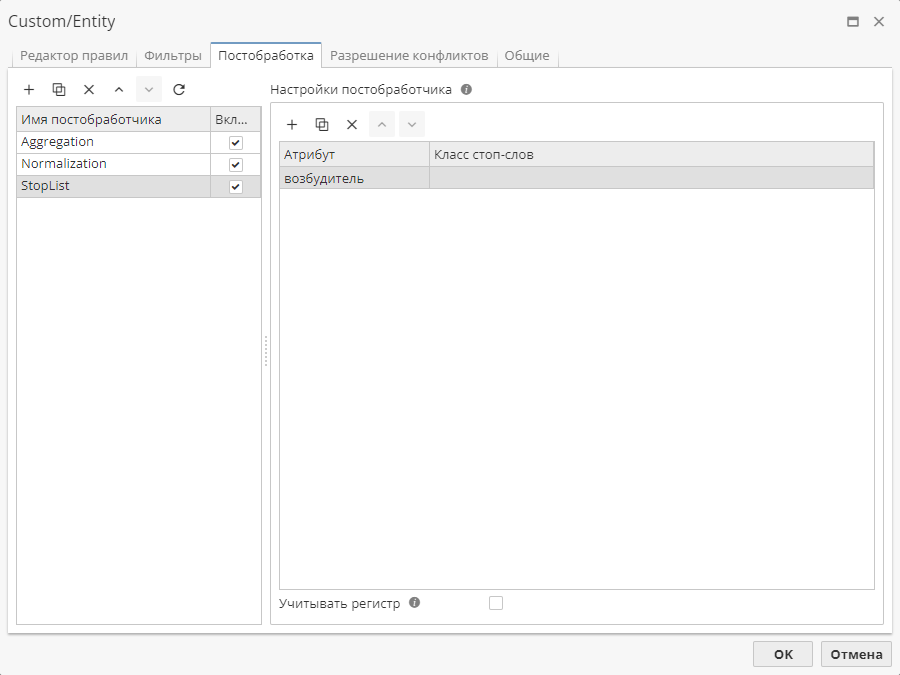
Окно настройки постобработчика StopList включает два поля: Атрибут и Класс стоп-слов. В поле Атрибут указываются имена атрибутов сущностей, найденных правилом. Необходимое значение можно выбрать в выпадающем списке. В поле Класс стоп-слов укажите имя класса слов из словаря StopLists.
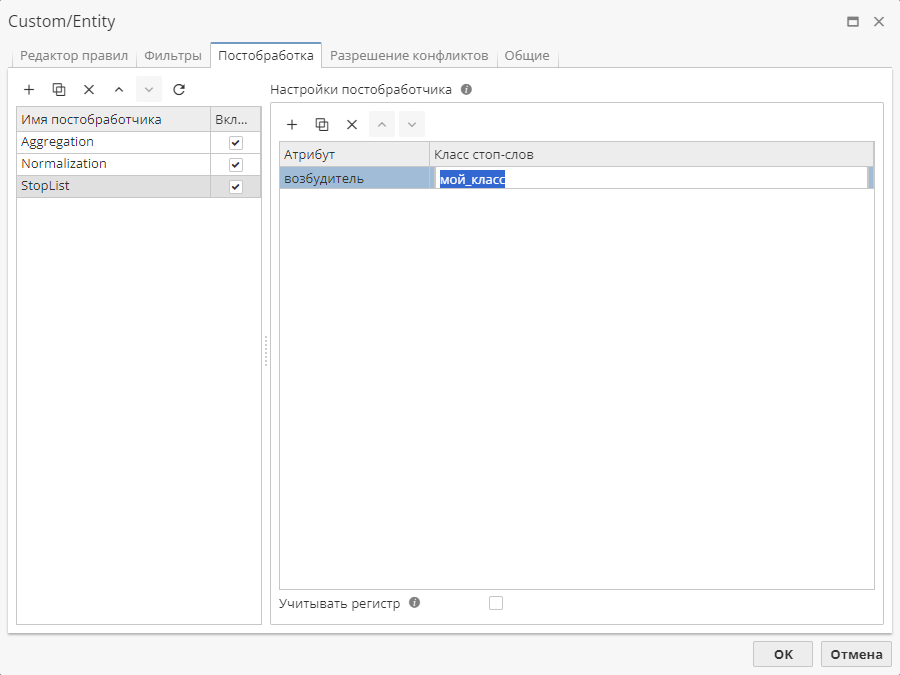
Для одного атрибута можно добавить несколько классов слов, отделив их друг от друга запятой. Если найденный атрибут относится к указанному классу слов, сущность будет исключена из отчета узла.
Для корректной работы постобработчика StopList убедитесь в том, что узел настроен на использование словаря StopLists (в окне настроек узла выберите вкладку Словари).
Списки стоп-слов – это удобный инструмент, позволяющий исключать лишние слова из результатов. При работе с таблицей данных, которая содержит очевидные ложноположительные результаты, наиболее эффективной мерой будет добавление новых позиций в список стоп-слов вместо редактирования исходного правила. Например, при работе с текстами медицинской тематики названия бактерий, болезней и микроорганизмов часто извлекаются как имена людей, поэтому целесообразно будет создать отдельный класс в словаре StopLists с наиболее часто встречающимися названиями.
(9) Пример 9:
Правило находит сущность с двумя атрибутами:
-
FirstName
-
LastName
Класс слов Medical в словаре StopLists включает следующие статьи:
-
Escherichia;
-
Mycobacterium;
-
Dysrhythmia.
Текст примера:
Без использования постобработчика StopList:
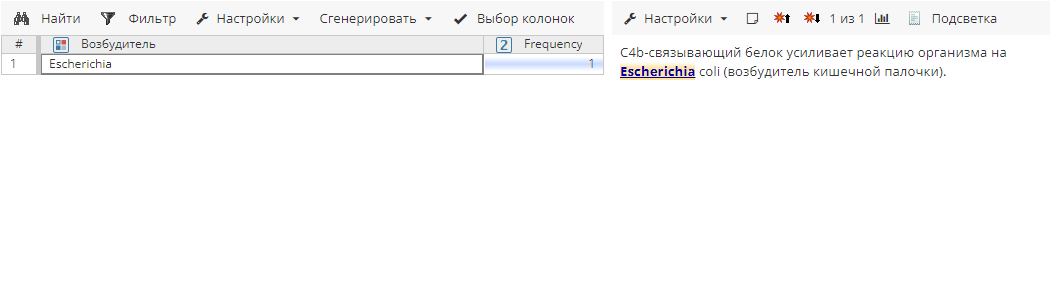
Извлеченные сущности:
FirstName |
LastName |
Escherichia |
При включении постобработчика StopList нежелательные слова исключаются из результатов:
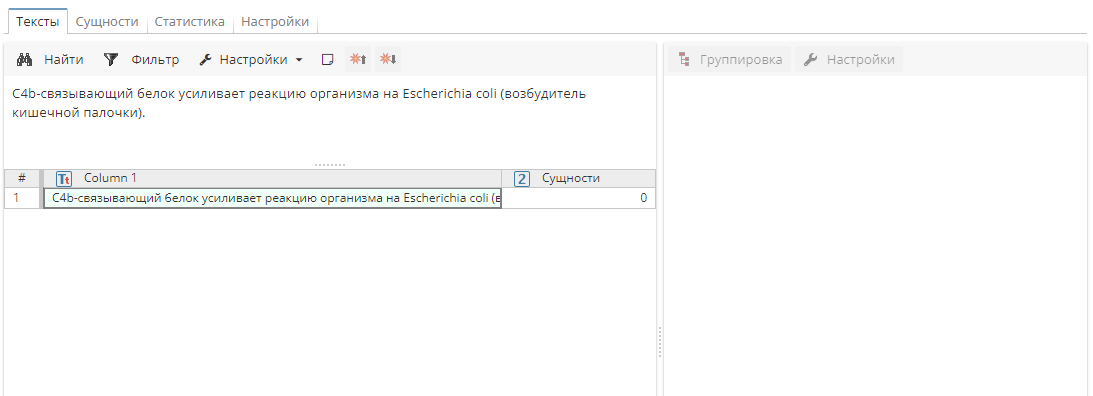
Извлеченные сущности:
FirstName |
LastName |
- |
- |
Пользователи могут добавлять новые классы слов в словарь StopLists через Менеджер словарей, либо напрямую через настройки постобработчика StopList. В последнем случае необходимо указать имя класса слов в поле Класс стоп-слов, а затем вручную добавить в него любые слова прямо из окна просмотра результатов узла, как показано ниже.
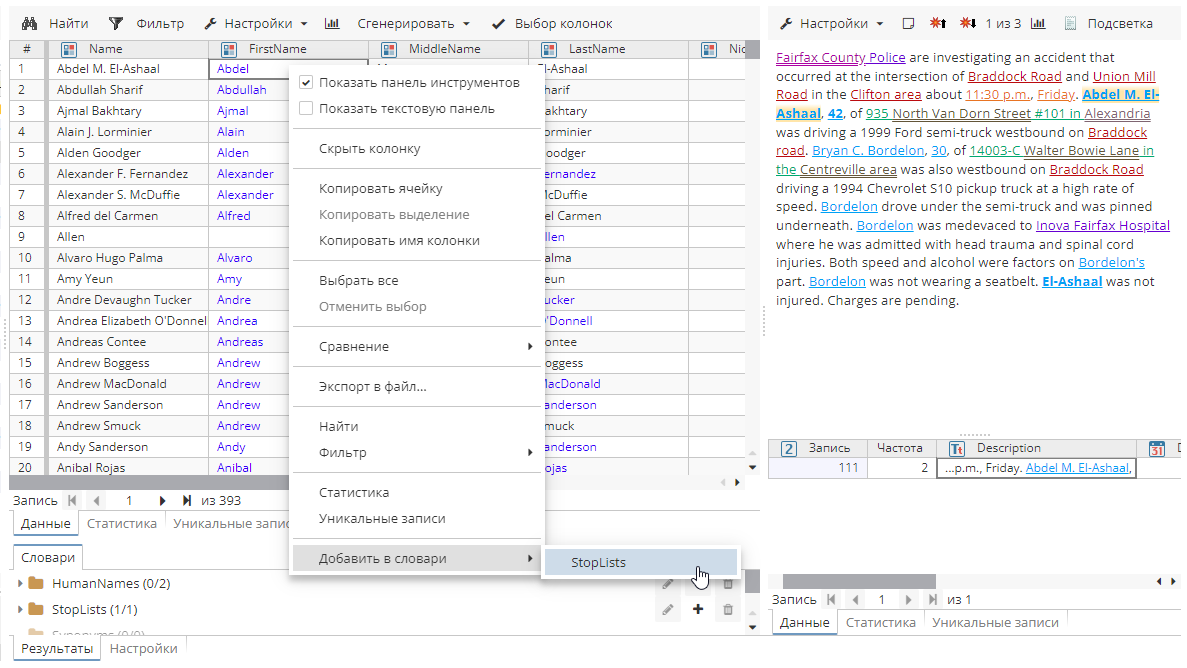
В отдельном диалоговом окне укажите часть речи и нажмите OK.
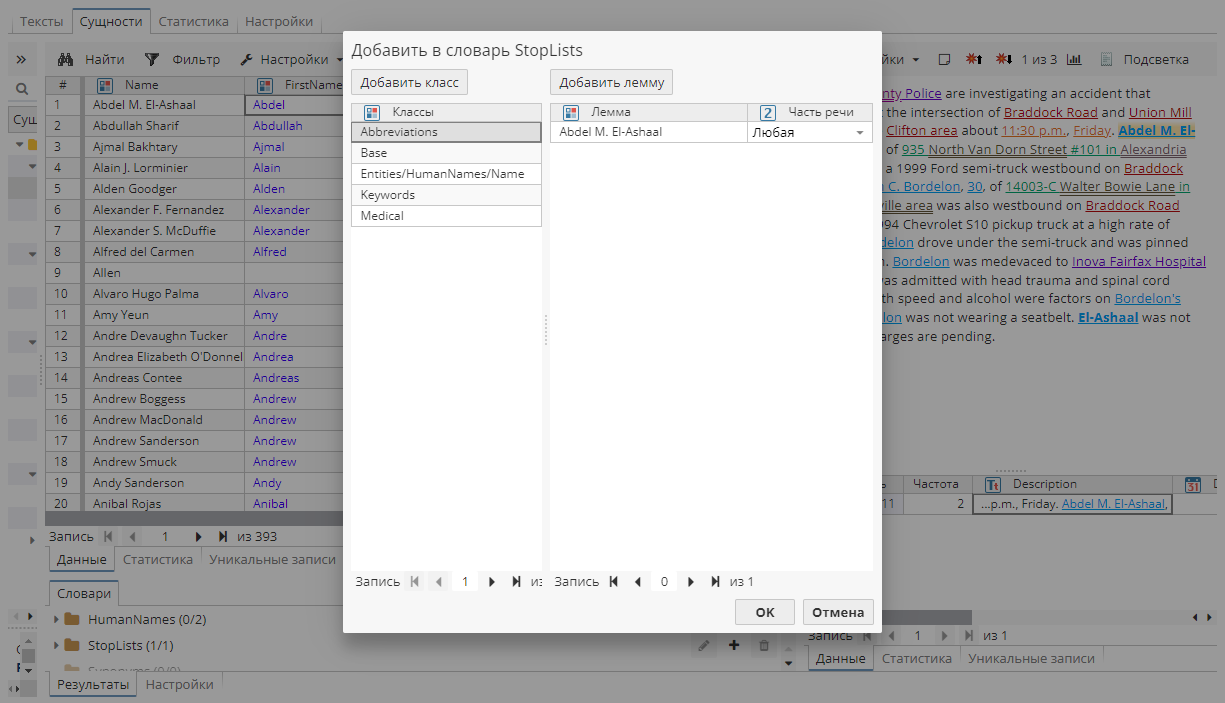
После повторного выполнения узла словарь StopLists будет дополнен соответствующими статьями.
4. Semantic Links (Семантические связи)
Постобработчик Semantic Links (Семантические связи) позволяет находить слова (синсеты), связанные с аргументами определенным типом отношений. Информация об отношениях между объектами содержится в словарях группы Semantics. В качестве примера мы будем использовать словарь Default.
Для получения корректных результатов:
-
Словарь Semantics должен включать необходимый аргумент и иметь выбранный тип отношений.
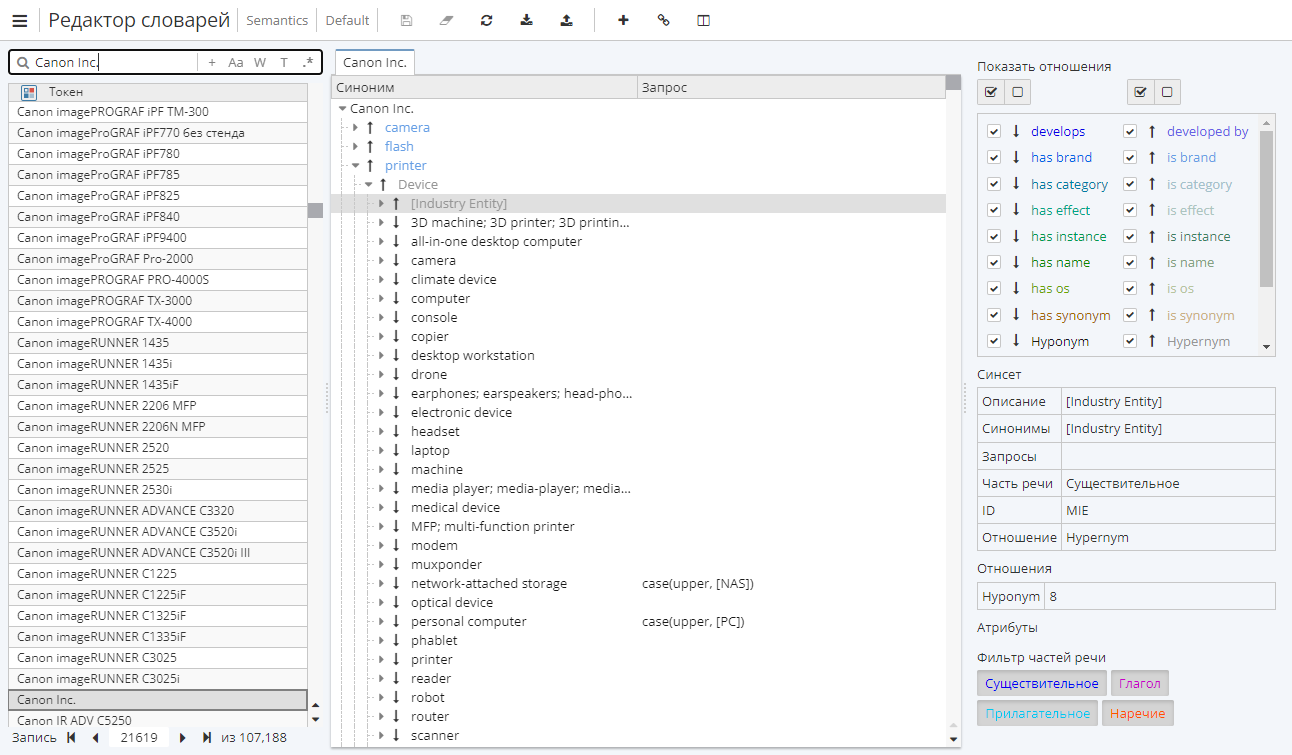
-
Убедитесь, что узел настроен на использование соответствующего словаря (в окне настроек узла выберите вкладку Словари).
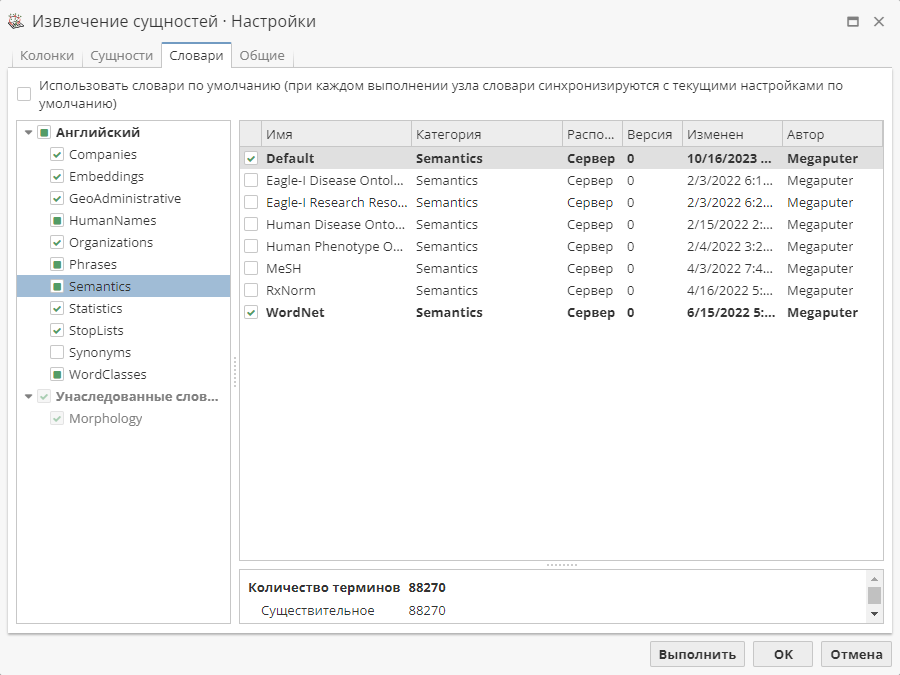
4.1 Настройка постобработчика Semantic Links
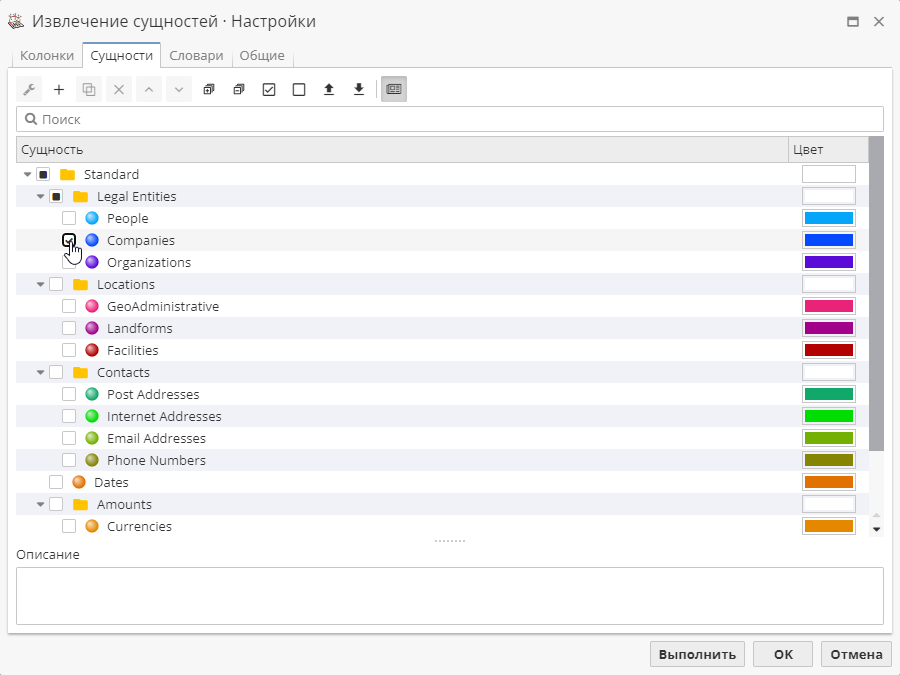
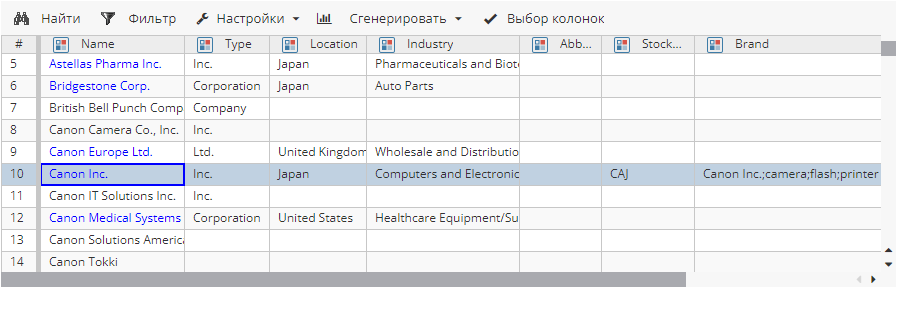
В качестве примера мы выполним поиск отношений для компании "Canon Inc.". Для лучшего понимания в окне настроек узла Извлечение сущностей на вкладке Сущности включите только одну стандартную сущность Companies.
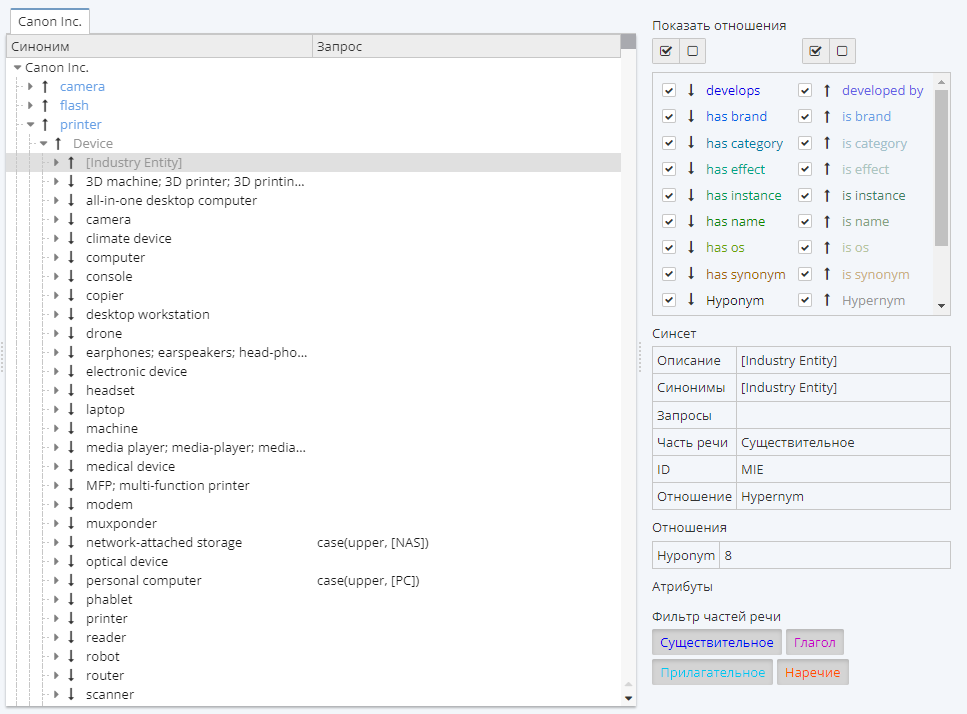
Наша цель – представить в отчете узла информацию о том, для каких устройств компания является брендом.
"Canon Inc." – один из брендов фотографического оборудования. В словаре Default группы Semantics "Canon Inc." имеет отношение is brand и характеризуется тремя синсетами: camera (камера), flash (вспышка) и printer (принтер).
Нажмите дважды на имя сущности и перейдите на вкладку Постобработка для добавления и настройки постобработчика Semantic Links.
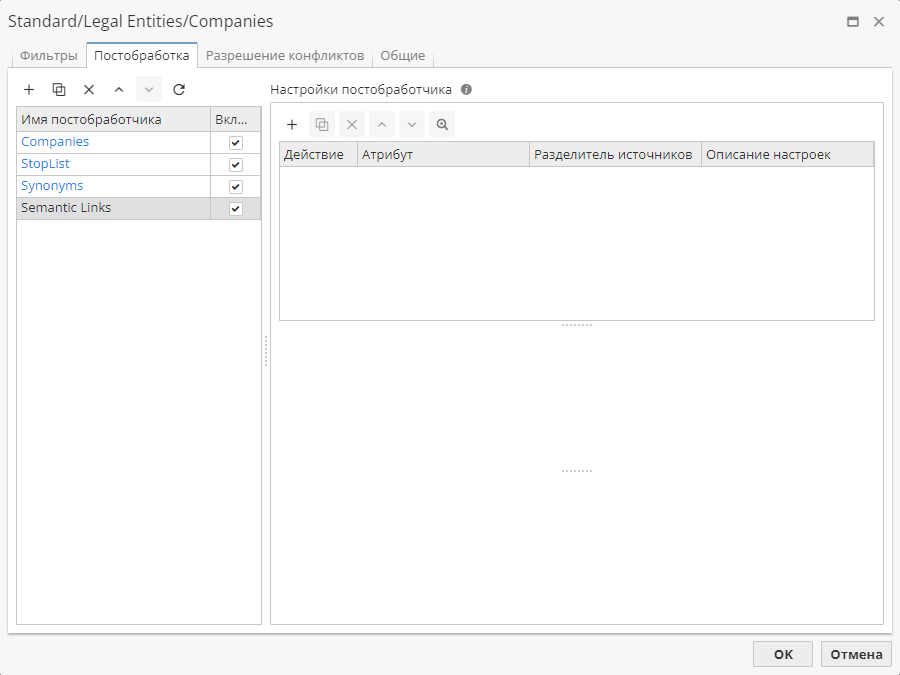
Процедура настройки постобработчика выполняется поэтапно, сверху вниз.
-
Атрибут – имя исходной колонки, где содержатся аргументы. В нашем случае мы выбираем колонку с сущностью "Canon Inc." (Name).
-
Разделитель источников – если в строке колонки представлено несколько сущностей, укажите символ, который отделяет одну сущность от другой (запятая, точка с запятой и т.д.). Поскольку мы работаем только с одной сущностью, выберите Нет.
-
Описание настроек – содержит сведения о текущих настройках постобработчика.
В разделе Настройки действия выберите один или несколько словарей, в которых будет осуществляться поиск синсетов. Как уже было обозначено ранее, мы используем только словарь Default группы Semantics.
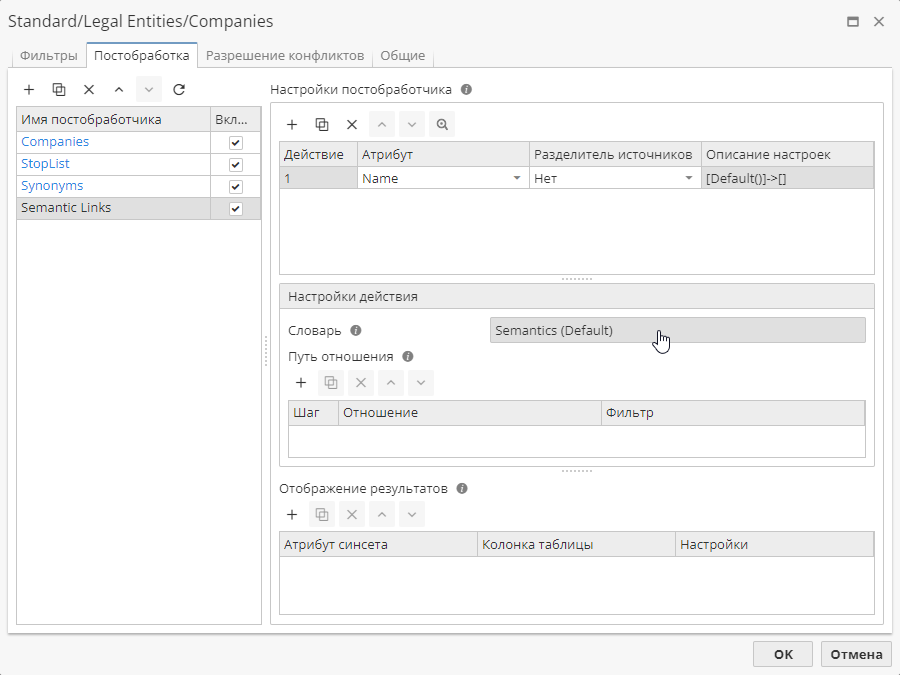
После выбора необходимых словарей перейдите к заполнению таблицы Путь отношения.
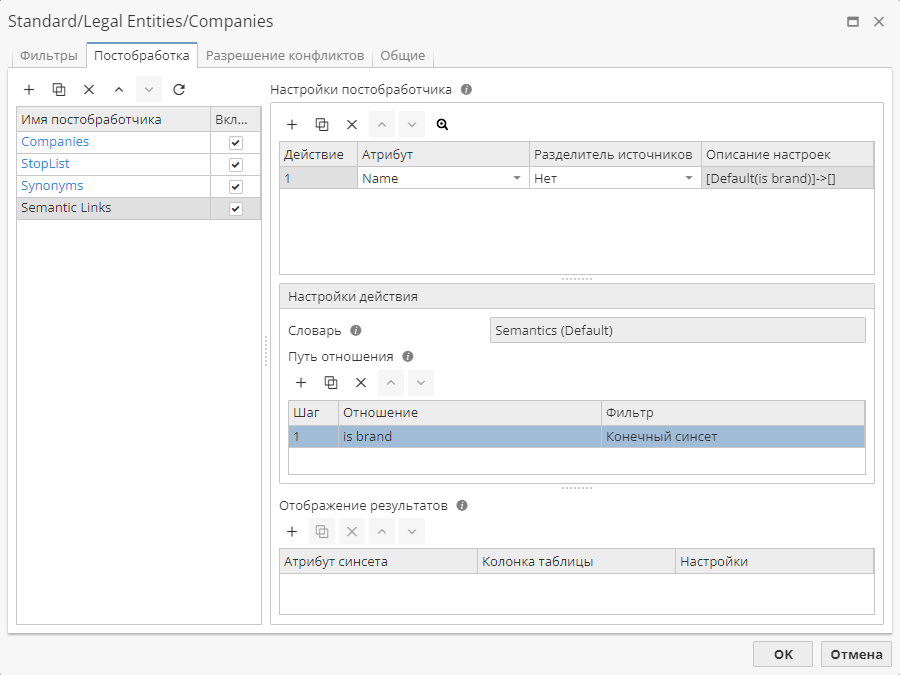
Для этого нажмите на кнопку с изображением плюса, добавьте новый элемент в таблицу и щелкните на поле "Отношение":
-
Уровень – позволяет исключить из отчета синсеты, находящиеся на расстоянии менее N от аргумента. По умолчанию используется значение "0", при котором также возвращается сам исходный аргумент. При выборе значения "1" возвращаются все связанные с аргументом синсеты, кроме самого аргумента. В нашем примере мы используем интервал по умолчанию.
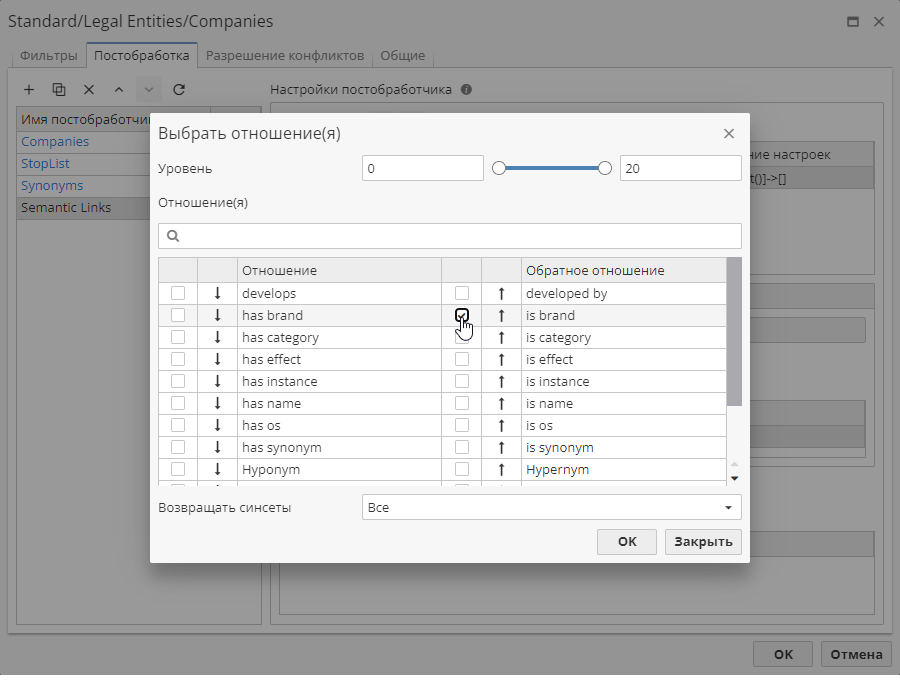
-
Отношение – отметьте галочкой типы отношений, по которым будет производиться поиск в словаре Semantics. нашем примере мы используем обратное отношение is brand.
-
Возвращать синсеты – используется для определения синсетов, которые должны быть получены из выбранного словаря:
-
Все – возвращает синсеты всех уровней.
-
Последнее значение – возвращает только синсеты самого нижнего уровня при поиске нижележащих понятий (гипонимы, меронимы), либо только синсеты самого верхнего уровня при поиске вышележащих понятий (гиперонимы, холонимы).
-
При необходимости вы также можете настроить поле Фильтр в таблице Путь отношения. Среди доступных режимов фильтрации:
-
EndSynset – только к конечному синсету (выбран по умолчанию);
-
StartSynset – только к начальному синсету;
-
StartAndEndSynsets – только к начальному и конечному синсету;
-
AllSynsets – ко всем синсетам.
| При работе с таблицей Путь отношения обратите внимание на то, что в колонке Шаг на Шаге 1 используется колонка, указанная для строки Действие в таблице выше. Для последующих шагов (Шаг 2, Шаг 3 и т.д) в качестве исходных будут выступать данные, полученные в результате выполнения предыдущего шага. |
В таблице Отображение результатов:
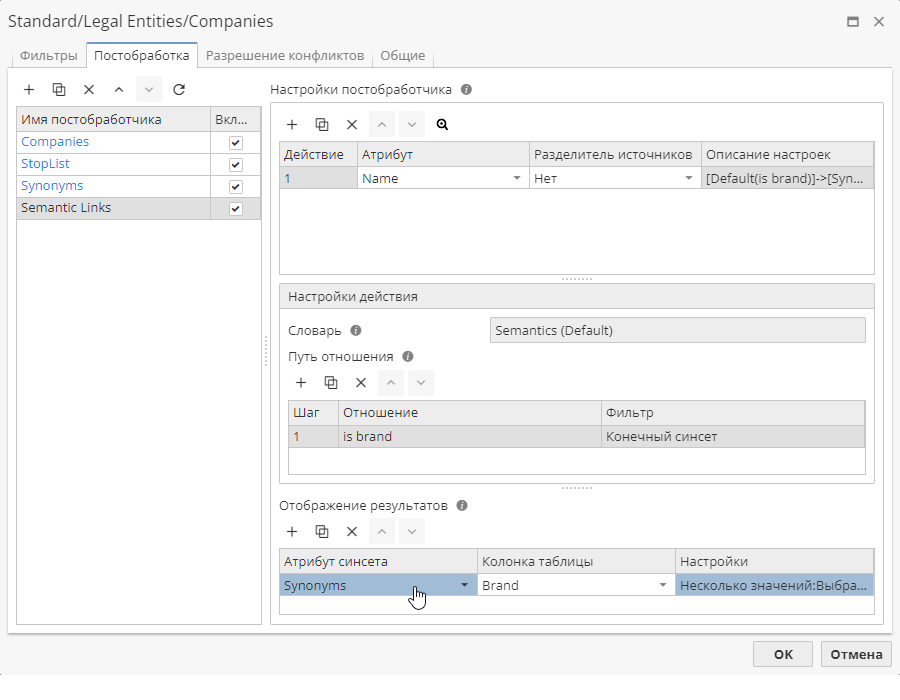
-
Атрибут синсета – атрибут выходного синсета, т.е. колонка в соответствующем словаре, данные из которой будут добавлены в выходную таблицу. Как вы можете видеть на скриншоте выше, мы используем атрибут Synonyms.
-
Колонка таблицы – колонка выходной таблицы данных, в которой будут отображены данные атрибута синсета. Пользователь может выбрать колонку из списка или ввести имя новой колонки, которая будет добавлена в выходную таблицу. В нашем случае мы добавим новую колонку (Бренд) в выходную таблицу данных.
После того, как узел будет выполнен, в колонке Бренд для сущности "Canon Inc." отобразятся следующие синсеты: camera;flash;printer. Для данных синсетов "Canon Inc." является брендом. У остальных компаний в словаре Semantics не указан искомый вид отношений, поэтому их значения в этой колонке пустые.
5. Dictword (Дополнение из словарей)
Постобработчик Dictword (Дополнение из словарей) позволяет дополнить сущности аргументами, которые содержатся в выбранных словарях.
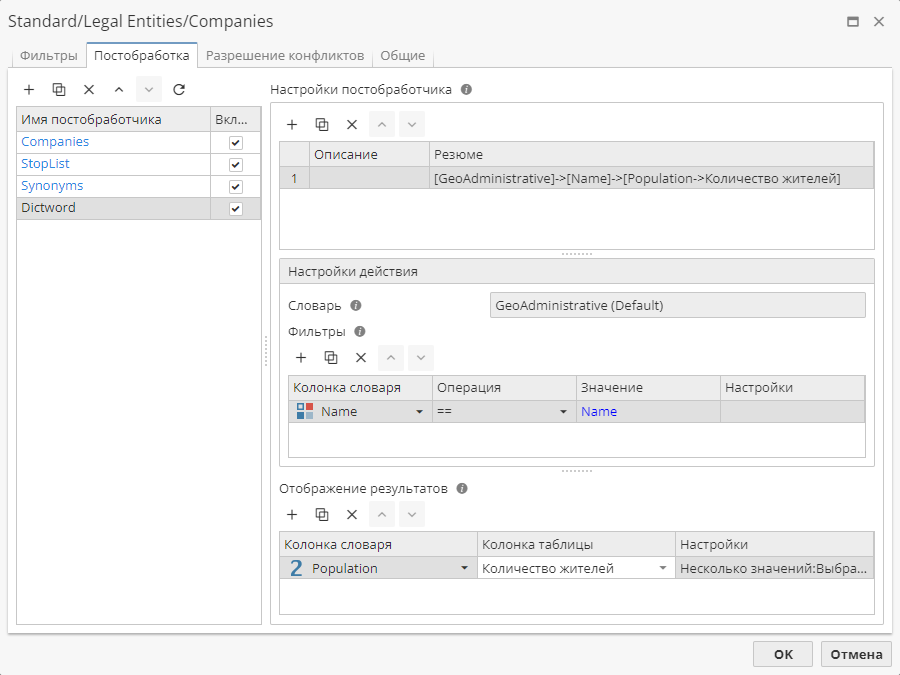
Начните с добавления новой строки в таблицу Настройки постобработчика. Поле Описание можно оставить пустым – оно не является обязательным для заполнения. Содержимое поля Резюме обновляется автоматически по мере изменения настроек.
Щелкните по полю Словарь в разделе Настройки действия и выберите словарь, по которому будет выполняться поиск.
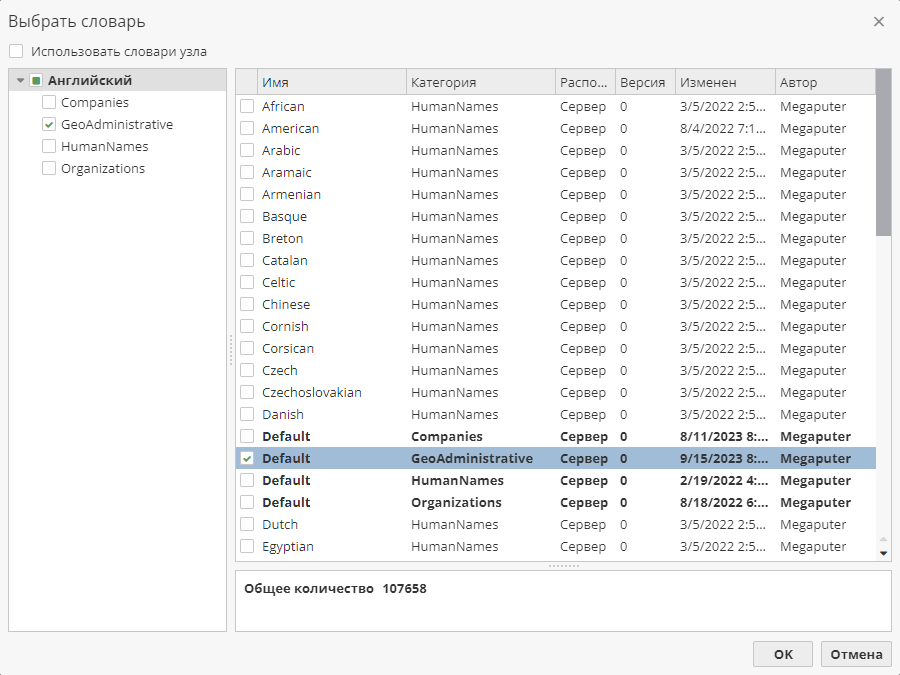
Обратите внимание, что в списке будут представлены только те словари, которые были включены на вкладке Словари в окне настроек узла.
После выбора необходимых словарей, перейдите к таблице Фильтры. Фильтры используются для определения колонки выбранного словаря, с которой необходимо сопоставить найденную сущность.
Добавьте новую строку в таблицу Фильтры:
-
Колонка словаря – укажите колонку словаря, которая будет использована в качестве фильтра.
-
Операция – выберите отношение между колонкой словаря и значением.
-
Значение – укажите выражение фильтра, которое будет сопоставлено со значением в словаре. В качестве выражения может выступать значение атрибута, константа, домен или константа регулярного выражения.
-
Настройки:
-
Применить при наличии значения – при включении данной опции операция сопоставления значений будет проигнорирована в случае, если какой-либо из аргументов имеет пустое значение.
-
Нечеткое соответствие – при включении данной опции применяется алгоритм нечеткого соответствия. Использование алгоритма нечеткого соответствия позволяет находить соответствия, которые отдаленно напоминают искомые значения, но пригодны для дальнейшего анализа.
-
Порог достоверности – показатель того, насколько алгоритм нечеткого соответствия уверен в правильности предлагаемого соответствия. Измеряется по шкале от 0 до 100, которая становится активной при включении опции Нечеткое соответствие.
-
В разделе Отображение результатов:
-
Колонка словаря – укажите колонку соответствующего словаря.
-
Колонка таблицы – укажите колонку выходной таблицы данных, где будут сохранены результаты. Пользователь может выбрать текущую колонку из списка, либо указать имя новой колонки, которая будет добавлена в отчет.
-
Настройки – содержит дополнительные настройки отчета.
Для доступа к дополнительным опциям нажмите на поле Настройки:
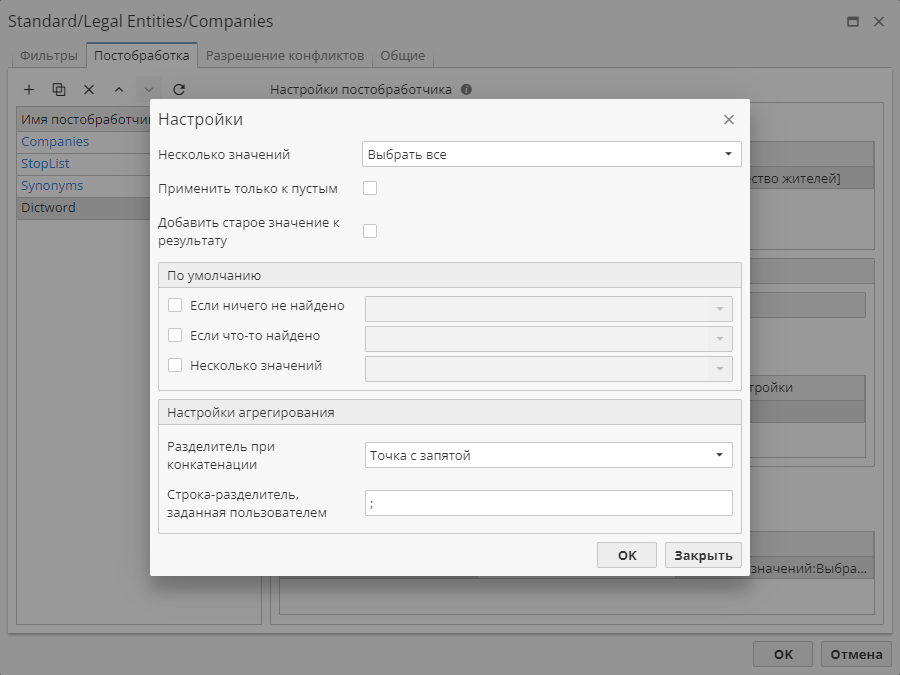
Несколько значений – определяет поведение постобработчика при обнаружении более одного совпадения.
Выпадающий список Несколько значений содержит следующие позиции:
1) Отменить выбор – если найдено несколько значений, ни одно из них не будет выбрано:
2) Выбрать первые – если найдено несколько значений, будет выбрано только первое соответствие:
3) Выбрать все – если найдено несколько значений, будут выбраны все соответствия:
4) Выбрать по умолчанию – выбрать одно или несколько значений по умолчанию. При выборе данного режима станут доступны опции раздела По умолчанию:
-
Если ничего не найдено – укажите значение по умолчанию, которое будет отображено в результатах узла в случае, если не было найдено соответствий.
-
Несколько значений – укажите несколько значений по умолчанию, которые будут отображены в результатах узла в случае, если не было найдено соответствий.
5) Применить только к пустым – настройки применяются к пустому значению в результатах извлечения:
Если данная опция отключена, настройки применяются ко всем результатам независимо от того, являются ли они пустыми или содержат значение:
6) Добавить старое значение к результату – определяет, должно ли старое значение (которое уже имеется в результатах) появляться в результатах узла:
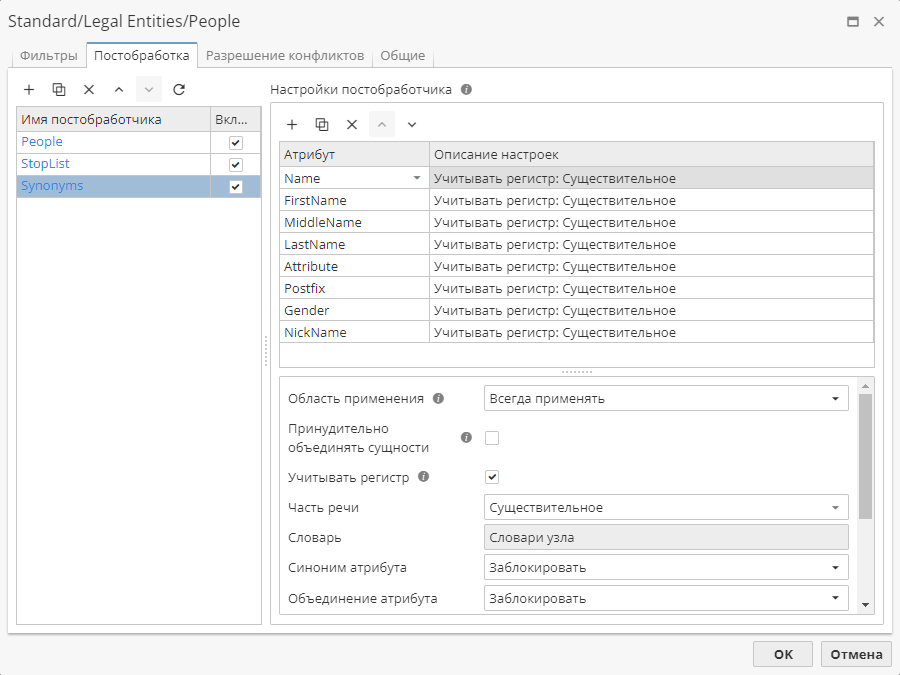
6. Synonyms (Синонимы)
Постобработчик Synonyms (Синонимы) позволяет объединить сущности, между атрибутами которых имеется семантическое подобие. Атрибуты объединяются только в том случае, если они входят в одну группу слов в словаре синонимов.
Рассмотрим следующий пример:
Text 1:
Text 2:
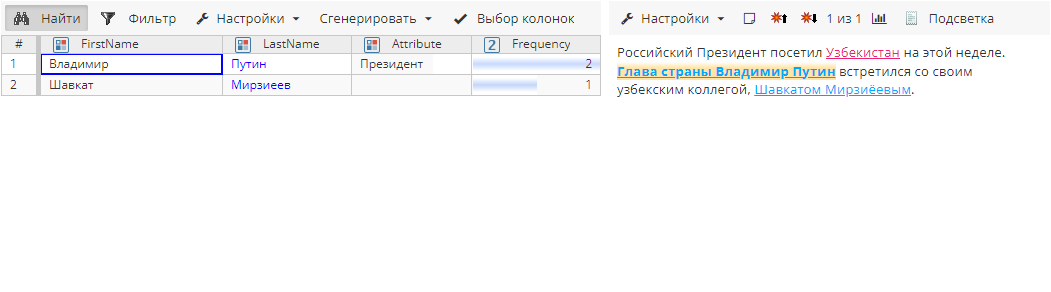
Сущности до агрегирования:
FirstName |
LastName |
Attribute |
Frequency |
Шавкат |
Мирзиёев |
коллега |
1 |
Владимир |
Путин |
Глава страны |
1 |
Владимир |
Путин |
Президент |
2 |
Без какой-либо постобработки мы увидим следующие атрибуты сущности:
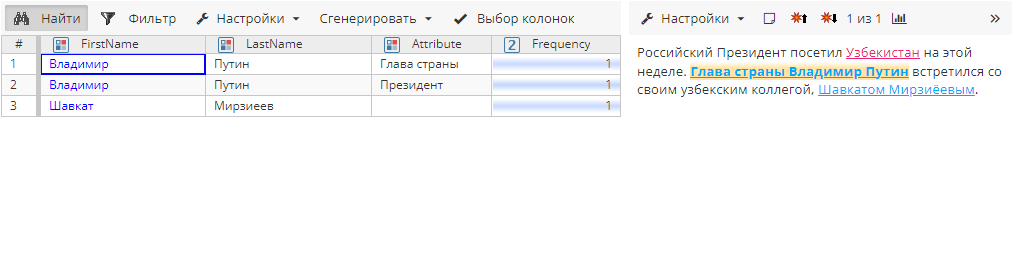
Обратите внимание, что мы добавили слова "президент" и "глава страны" в Словарь синонимов заранее.
Также необходимо подключить словарь в настройках узла.
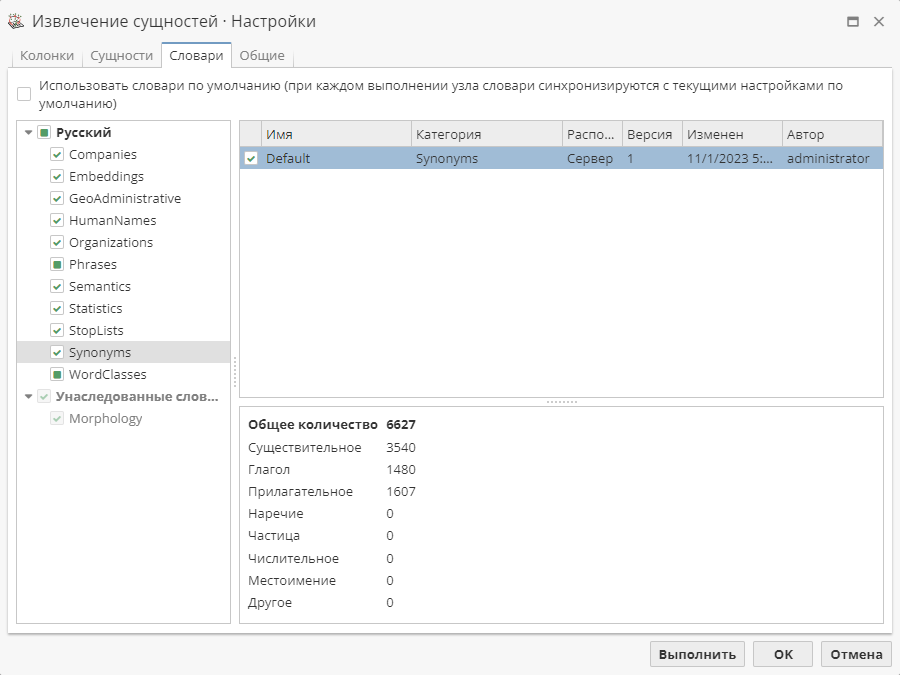
Если один из атрибутов не является первым словом в предложении и, следовательно, пишется со строчной буквы, снимите флажок Учитывать регистр в настройках постобработчика.
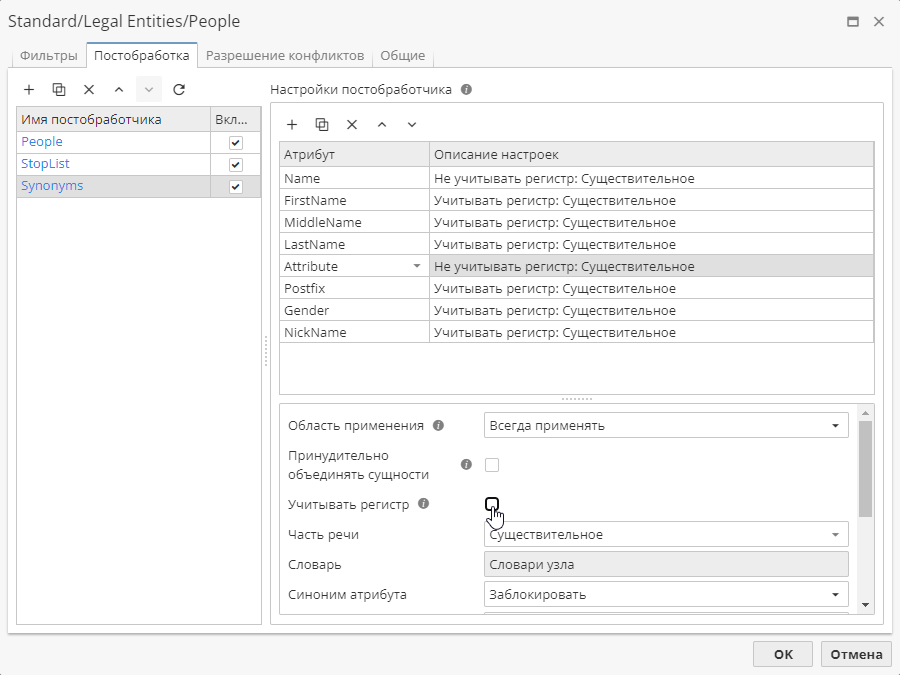
Сущности после агрегирования:
FirstName |
LastName |
Attribute |
Frequency |
Шавкат |
Мирзиёев |
коллега |
1 |
Владимир |
Путин |
Президент |
2 |
Если постобработчик включен, то атрибуты сущностей объединяются:
7. Tables (Таблицы)
Постобработчик Tables (Таблицы) распределяет сущности по ячейкам выходной таблицы, предоставляет дополнительную информацию о них (имя строки, имя столбца, имя таблицы и т.д.), а также способен распознавать использованные в таблице единицы измерения.
Данный постобработчик используется при работе с текстовыми файлами, которые содержат таблицы. Поддерживаются следующие форматы файлов:
-
pdf;
-
docx;
-
doc;
-
pptx;
-
ppt;
-
html;
-
odt;
-
ppt;
-
rtf.
| Обратите внимание, что в данный список не входят CSV-файлы. |
Для импорта соответствующих документов в PolyAnalyst используйте следующие узлы: Файлы, Интернет, FTP, RSS или SharePoint.
Порядок работы с постобработчиком Tables:
-
Выполните импорт одного или нескольких файлов с таблицами, используя один из вышеупомянутых узлов.
-
(Необязательно) Добавьте дочерний узел Индекс и выполните его для ознакомления с результатами.
-
Добавьте узел Извлечение сущностей и создайте новую пользовательскую сущность с соответствующим правилом. Например:
rule: Извлечение таблиц { query: {table(number:=1)}:m result: TablePart = $m } -
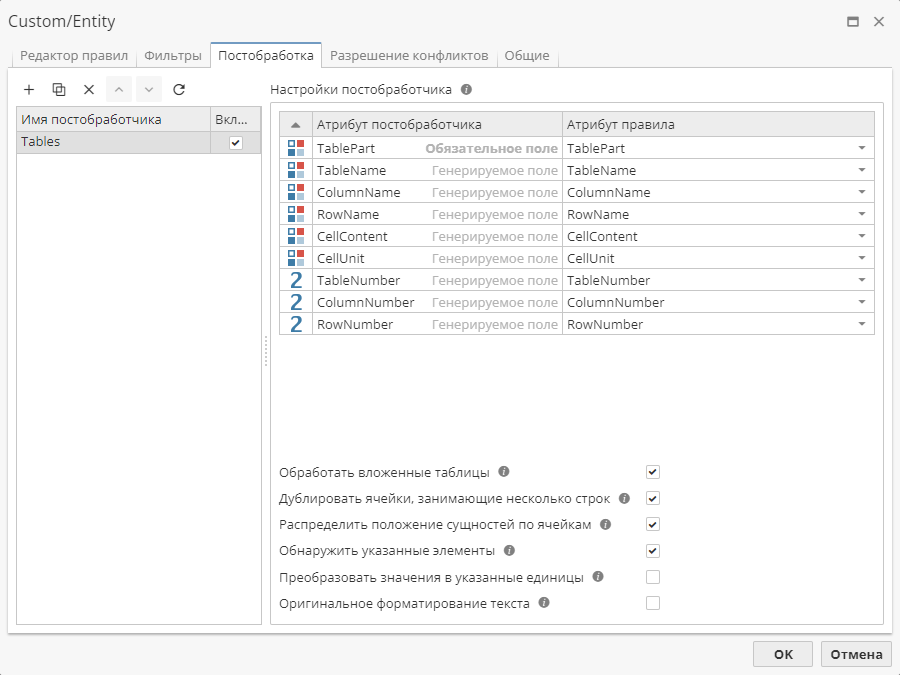
Переключитесь на вкладку Постобработка для добавления и настройки постобработчика Tables:
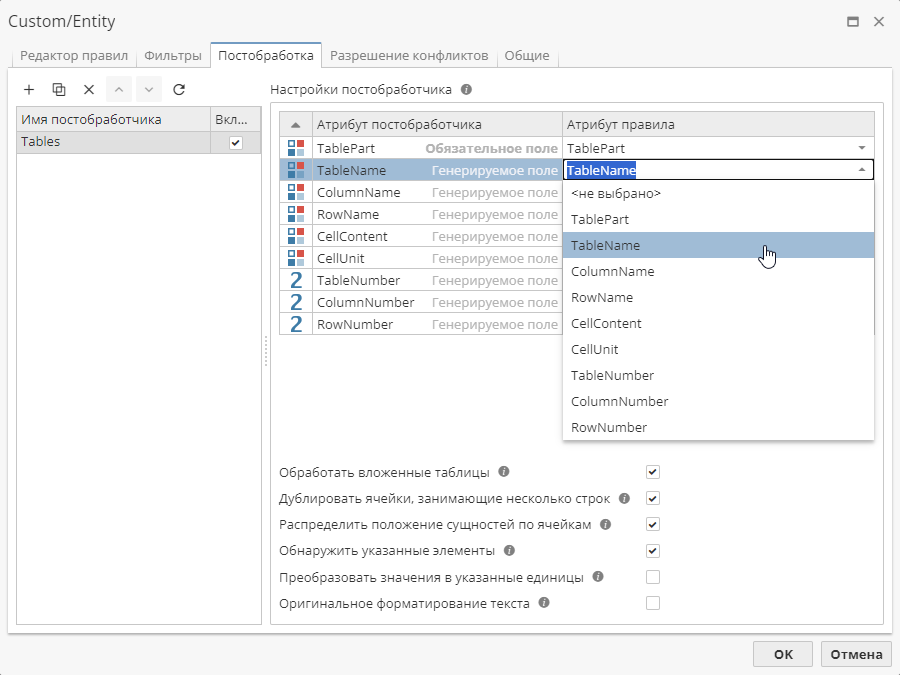
-
В поле Атрибут правила укажите имя выходной колонки. Вы можете выбрать значение в выпадающем списке, либо ввести новое имя.
-
Для разграничения сущностей, которые были извлечены во вложенных таблицах, и тех, что относятся к основной таблице, отметьте галочкой опцию Обработать вложенные таблицы.
-
Если одно значение распространяется сразу на несколько ячеек, отметьте галочкой опцию Дублировать ячейки, занимающие несколько строк для отображения соответствующего значения в каждой строке/колонке.
-
Во избежание конфликтов между сущностями, отметьте галочкой опцию Распределить положение сущностей по ячейкам. При этом позиция каждой сущности будет соответствовать конкретной ячейке.
-
Для того, чтобы узел выполнил поиск единиц измерения в именах колонок/строк, отметьте галочкой опцию Обнаружить указанные элементы. Обнаруженные единицы измерения будут добавлены в колонку CellUnit.
-
Для приведения значений в соответствие с обнаруженными единицами измерения, отметьте галочкой опцию Преобразовать значения в указанные единицы.
-
Для сохранения исходного форматирования (включая имена колонок/строк и специальные символы), отметьте галочкой опцию Оригинальное форматирование текста.
-
-
Выполните узел Извлечение сущностей. В отчете узла сущности будут распределены по таблице:
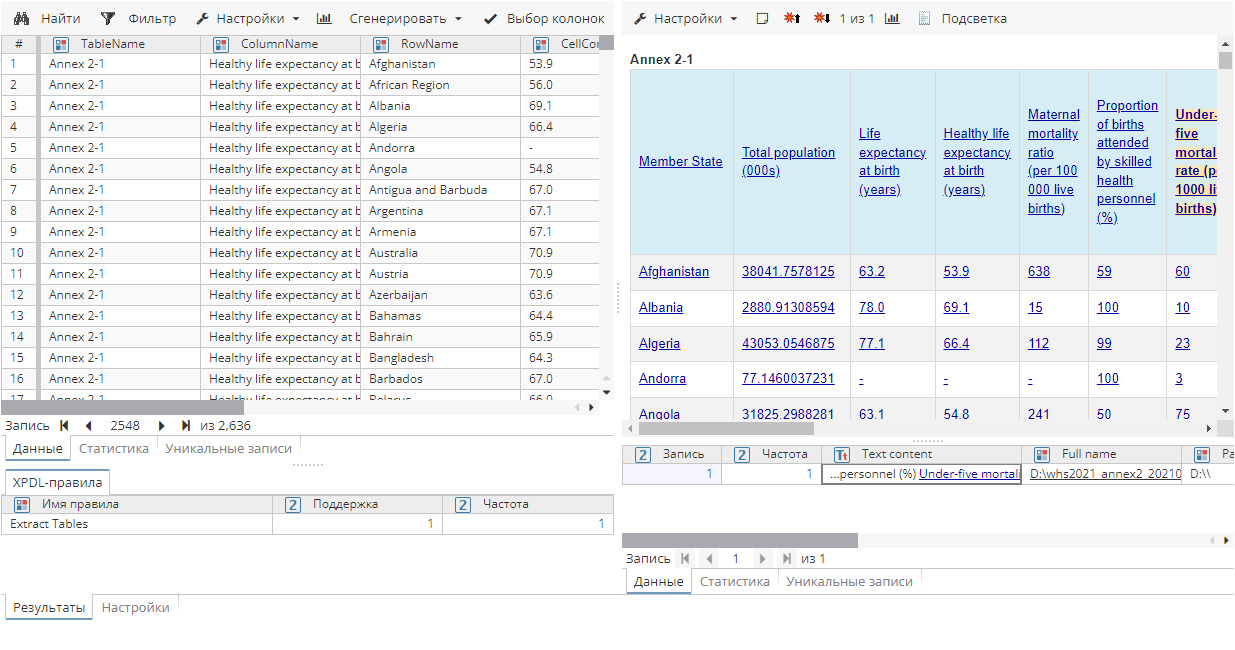
8. Derive (Производные колонки)
Постобработчик Derive (Производные колонки) позволяет добавить дополнительную колонку к выводимым данным так же, как это делается с использованием узла Производные колонки.
Откройте параметры сущности и добавьте постобработчик Derive
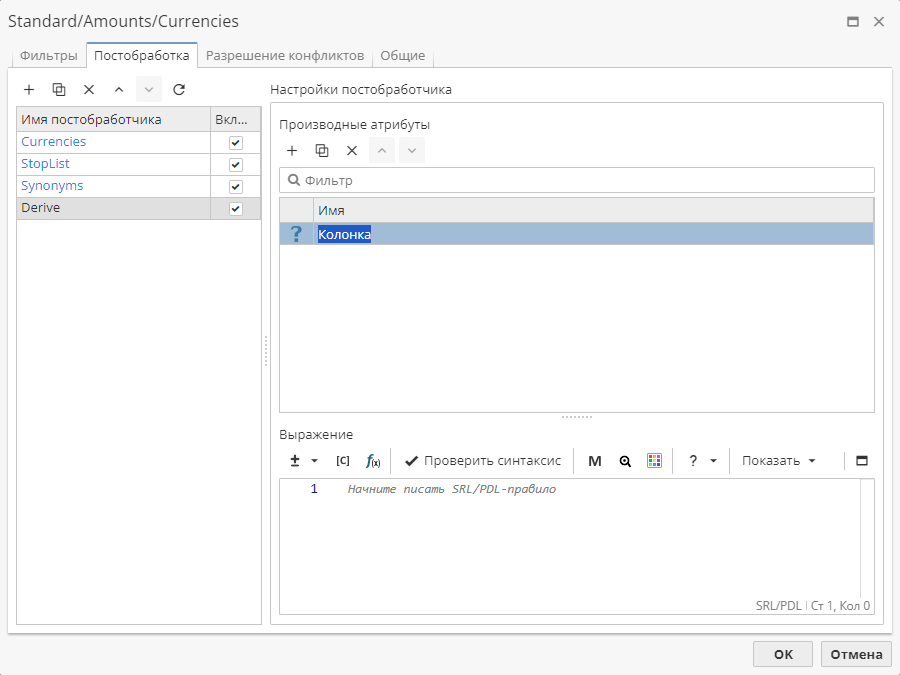
Нажмите на кнопку с изображением плюса, чтобы добавить колонку. Затем введите SRL-правило.
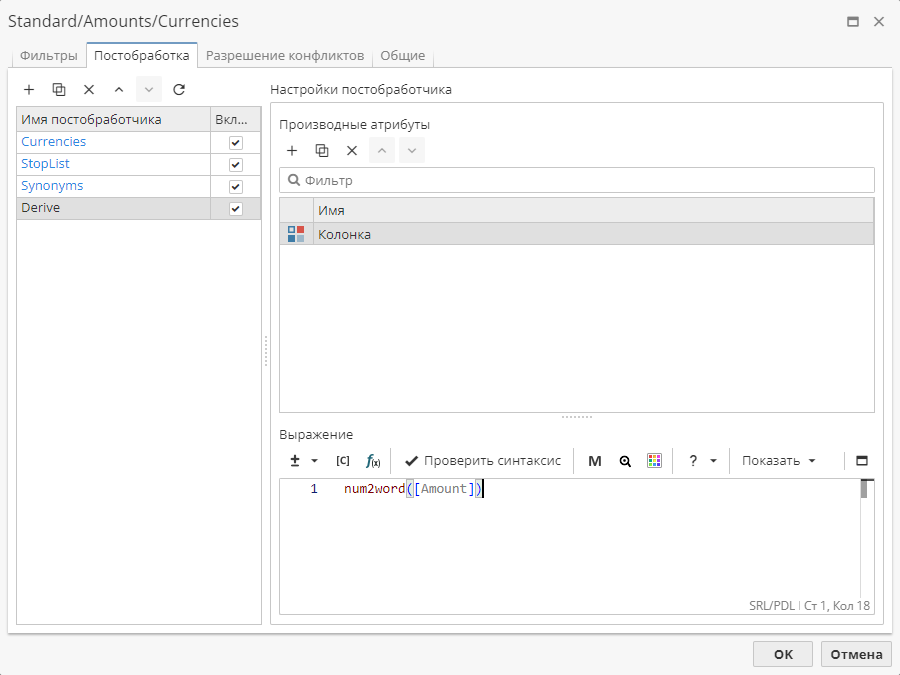
Выполните узел и откройте окно просмотра результатов узла. В выходной набор данных будет добавлена новая колонка.
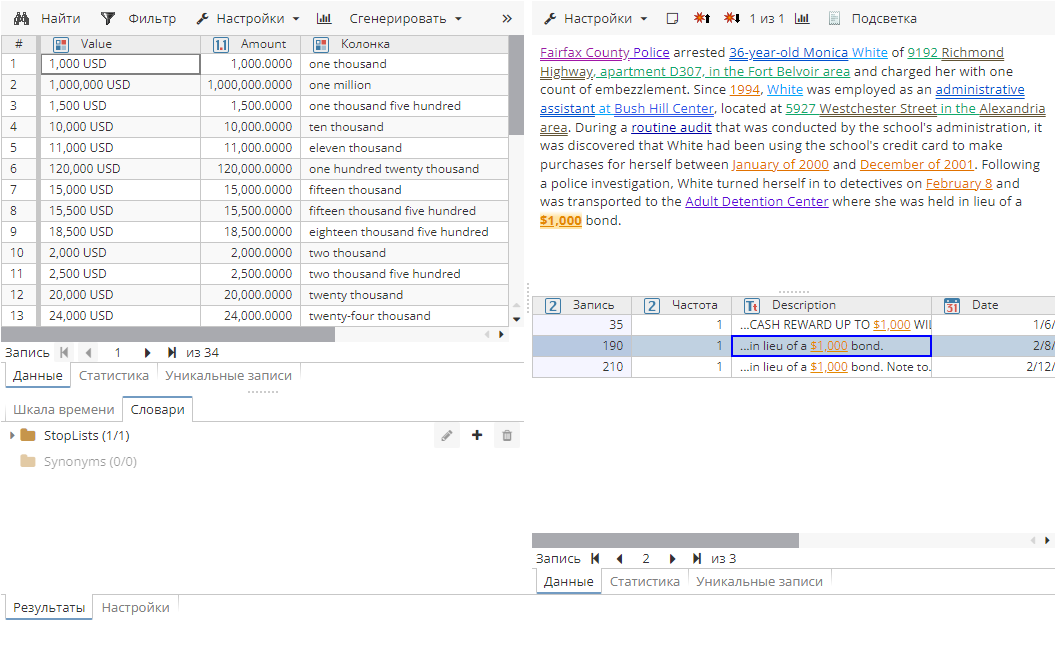
8. Special (Специальный постобработчик)
Постобработчик Special (Специальный постобработчик) позволяет агрегировать информацию о сущностях выбранного класса, находить сущности, пропущенные правилом, а также изменять форматирование выходных данных. Данный постобработчик можно использовать в том случае, когда результаты работы какого-либо правила не являются удовлетворительными.
Начните с добавления правила для вашей сущности – для получения дополнительной информации см. Редактирование XPDL-правил для пользовательских сущностей. В качестве примера мы изменим настройки стандартной сущности Companies. Отключив все предварительно настроенные постобработчики, мы получим следующие результаты:
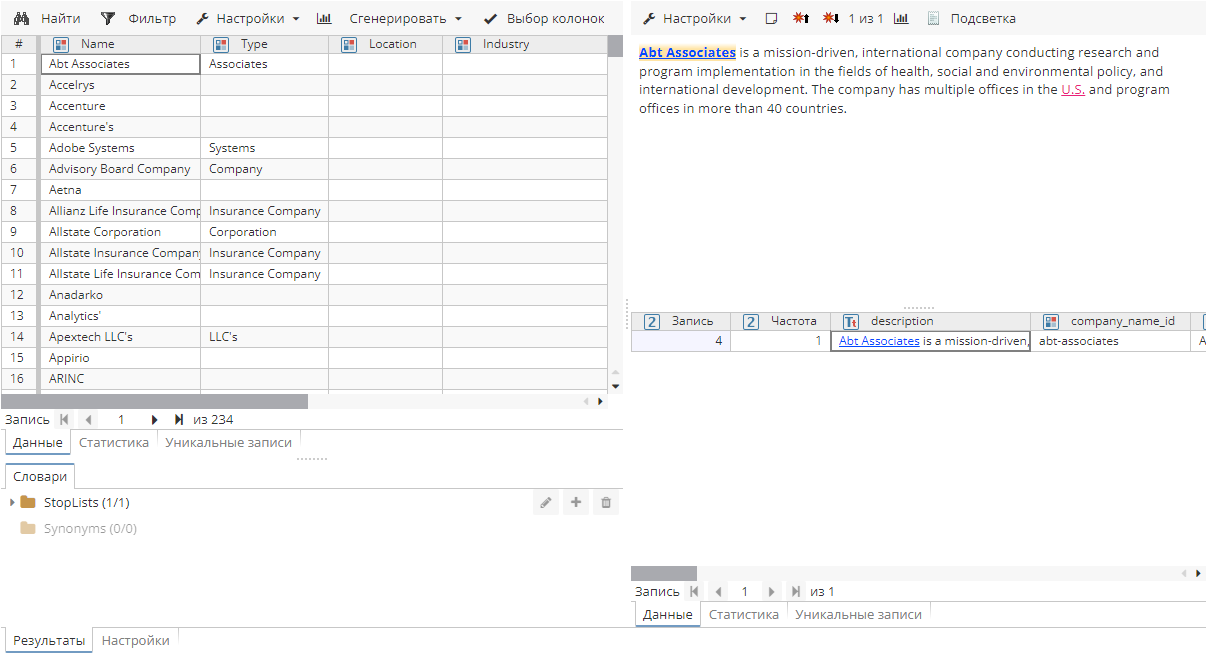
Как можно заметить, сущности были успешно извлечены, но большая часть колонок атрибутов содержит пустые значения. Для повышения качестве результатов включим постобработчик Companies:
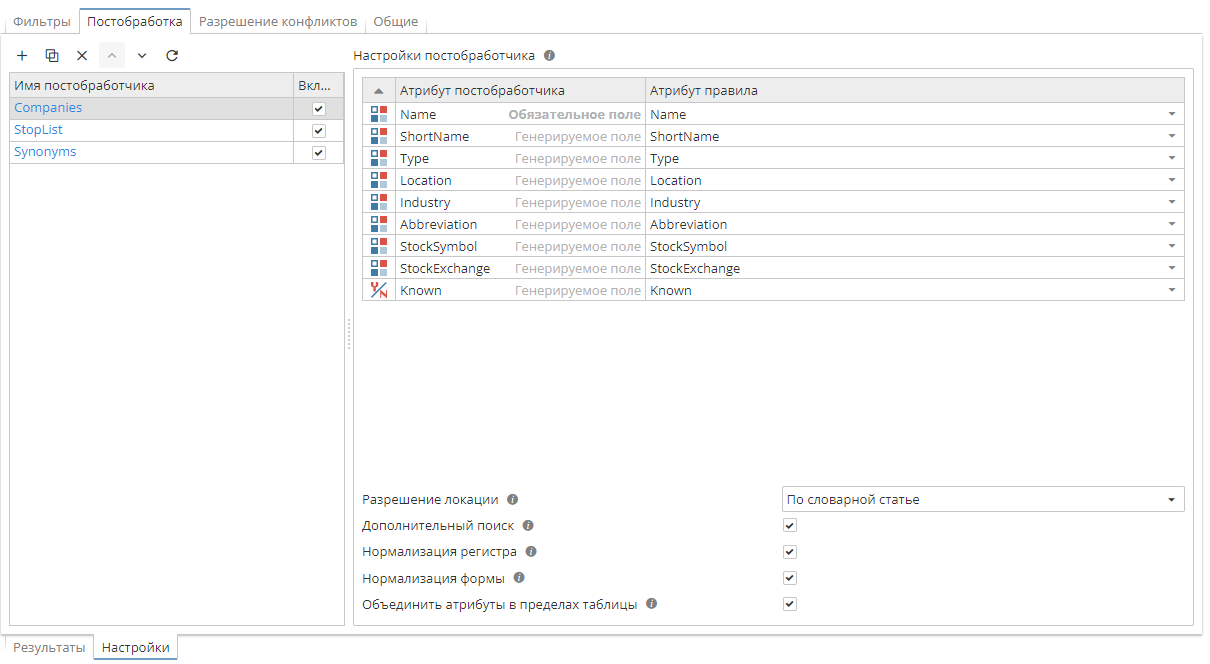
Все постобработчики группы Special имеют таблицу соответствий:
-
Атрибут постобработчика – содержит тип атрибута сущности, который определяется постобработчиком.
-
Атрибут правила – содержит имя выходной колонки. Вы можете выбрать значение в выпадающем списке, либо ввести новое имя.
Под таблицей соответствий размещаются дополнительные опции, набор которых зависит от выбранного постобработчика.
С включенным постобработчиком Companies отчет узла будет выглядеть следующим образом: