Загрузка таблиц данных в формате CSV с помощью узла R
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
| Как было сказано до этого, данная документация не содержит подробной информации о языке R. Узел R в PolyAnalyst представлен для удобства тех пользователей, которые уже знакомы с языком R и хотят интегрировать пользовательские R-скрипты в PolyAnalyst. |
Узел R можно использовать для импорта таблиц данных в PolyAnalyst с целью их дальнейшей обработки с помощью других узлов.
Основная идея использования узла R для импорта таблиц данных заключается в понятии data.frame.
Исходная таблица (например, CSV-файл), которая была интерпретирована через узел R в PolyAnalyst, рассматривается в скрипте языка R в качестве объектов таблицы данных data.frame. Являясь одним из объектов языка R, data.frame используется для хранения таблиц данных в виде списка векторов одинаковой длины.
Как работать с узлом СSV, используя узел R:
-
Добавьте узел R на скрипт.
-
Откройте свойства узла.
-
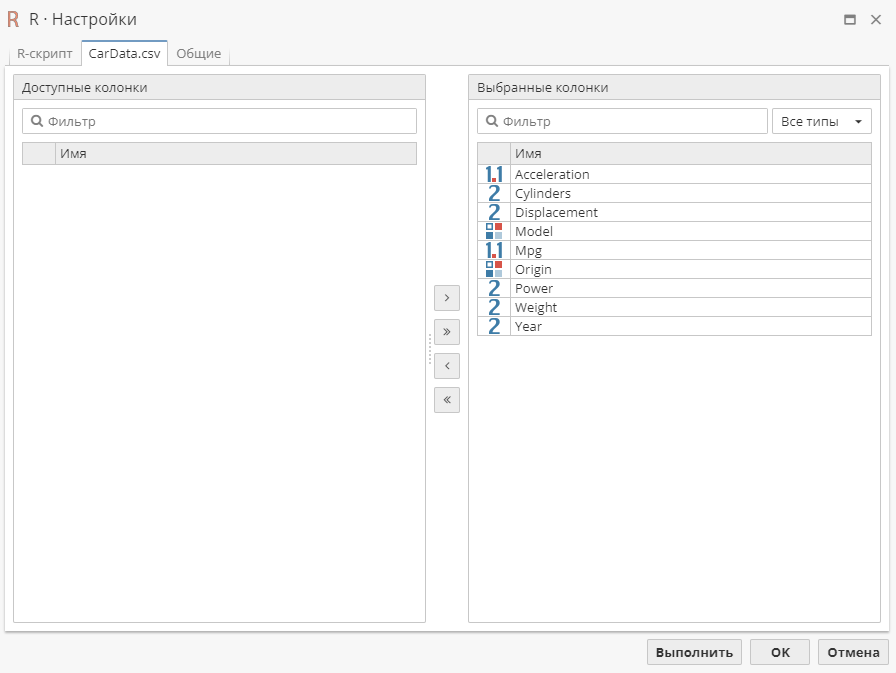
Перейдите на вторую вкладку (CarData.csv в нашем примере).
-
Выберите столбцы, с которыми вы хотите работать.
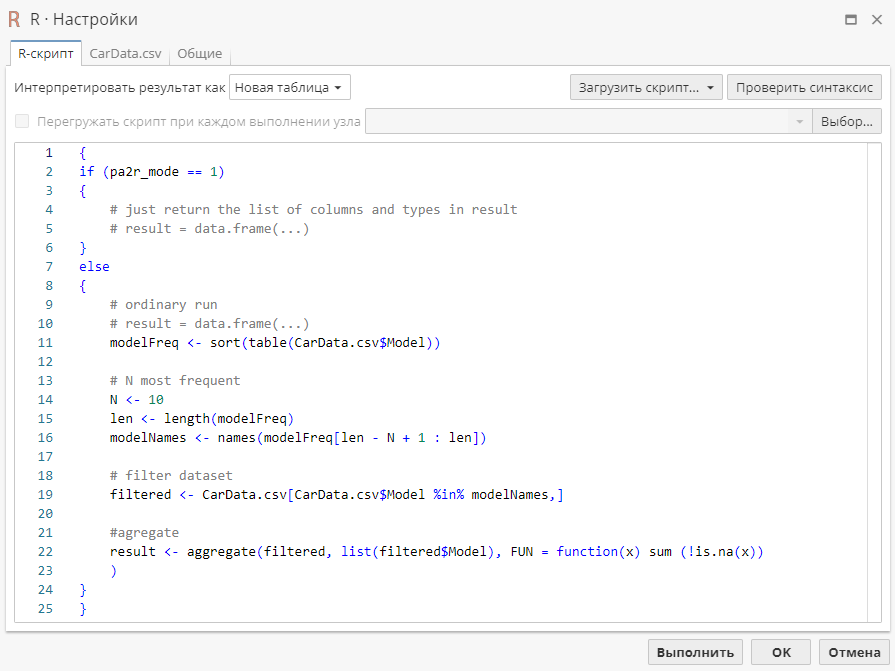
Затем перейдите на первую вкладку, чтобы вставить скрипт, который вы хотели бы использовать. В качестве примера введите в текстовом поле следующий скрипт для поиска 10 наиболее часто встречающихся моделей автомобилей из импортированного файла:
{
if (pa2r_mode == 1)
{
# just return the list of columns and types in result
# result = data.frame(...)
}
else
{
# ordinary run
# result = data.frame(...)
modelFreq <- sort(table(CarData.csv$Model))
# N most frequent
N <- 10
len <- length(modelFreq)
modelNames <- names(modelFreq[len - N + 1 : len])
# filter dataset
filtered <- CarData.csv[CarData.csv$Model %in% modelNames,]
#agregate
result <- aggregate(filtered, list(filtered$Model), FUN = function(x) sum (!is.na(x))
)
}
}
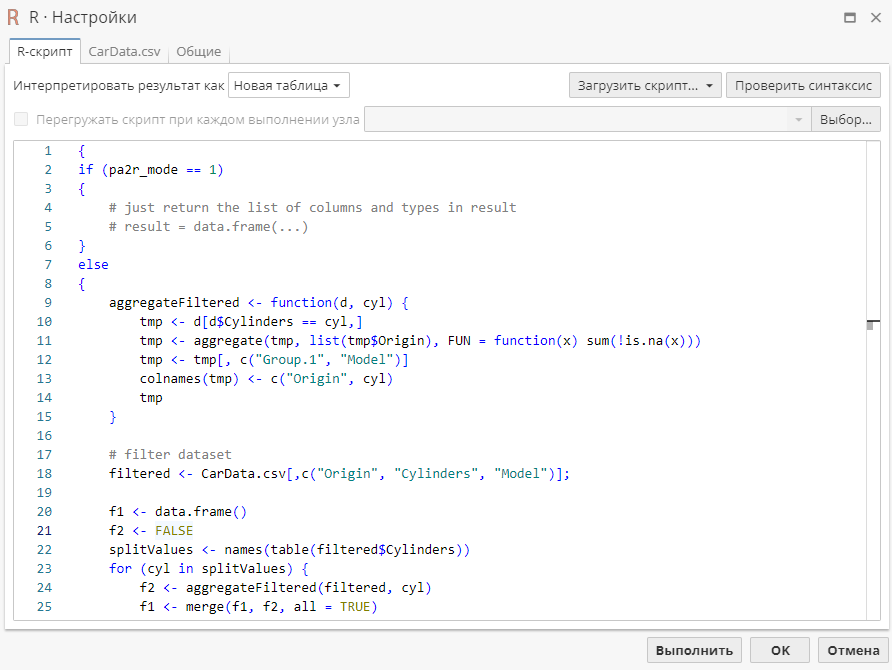
Второй пример - это скрипт, который позволит показать страну производства автомобилей в соответствии с типом цилиндров, которые в них используются:
{
if (pa2r_mode == 1)
{
# just return the list of columns and types in result
# result = data.frame(...)
}
else
{
aggregateFiltered <- function(d, cyl) {
tmp <- d[d$Cylinders == cyl,]
tmp <- aggregate(tmp, list(tmp$Origin), FUN = function(x) sum(!is.na(x)))
tmp <- tmp[, c("Group.1", "Model")]
colnames(tmp) <- c("Origin", cyl)
tmp
}
# filter dataset
filtered <- CarData.csv[,c("Origin", "Cylinders", "Model")];
f1 <- data.frame()
f2 <- FALSE
splitValues <- names(table(filtered$Cylinders))
for (cyl in splitValues) {
f2 <- aggregateFiltered(filtered, cyl)
f1 <- merge(f1, f2, all = TRUE)
}
result <- f1
}
}
R скрипт возвращает объект data.frame, который называется «результат» (result). В зависимости от параметров узла R такой объект должен являться новой таблицой. Эта таблица содержит только новые столбцы, которые добавляются в набор столбцов родительского узла. В случае, если объект data.frame содержит один столбец c индексом строки (начиная с 0), то такой data.frame должен быть отфильтрован из родительского узла.