Итерация скрипта Python для обработки нескольких исходных таблиц
| Данный узел или опция доступны, только если они включены в лицензии PolyAnalyst Server. |
Как говорилось выше, узел Python может быть соединен с несколькими родительскими узлами. Вы можете настроить итерацию скрипта Python для обработки нескольких родительских таблиц.
Например, с помощью узла Python вы можете свести в единую таблицу статистические данные из нескольких исходных таблиц, которые вы планируете использовать в ходе дальнейшего анализа.
Предположим, вы работаете с тремя источниками данных:
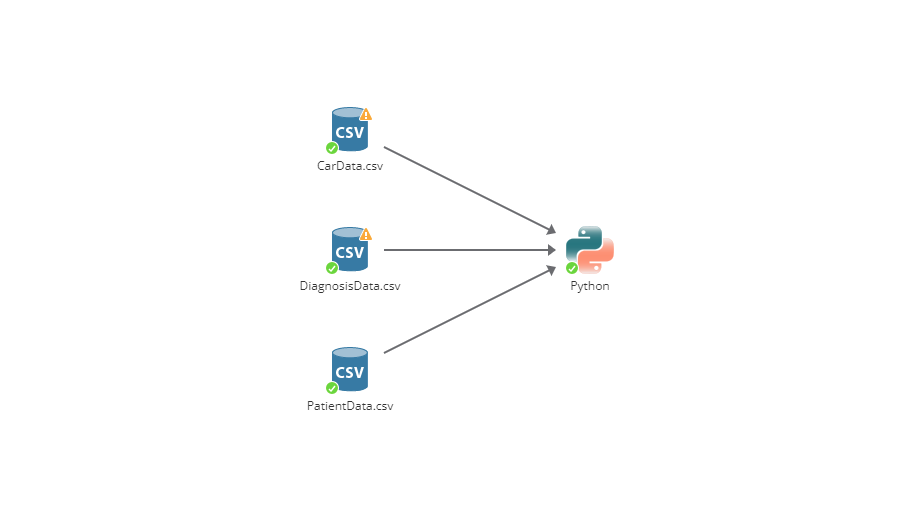
В настройках узла появятся три дополнительные вкладки: по одной на каждую исходную таблицу данных.
Используемый в данном случае скрипт будет сложнее, чем в предыдущих примерах.
Структура данных (DataFrame) в библиотеке pandas представляет собой полноценную таблицу, состоящую из колонок и строк.
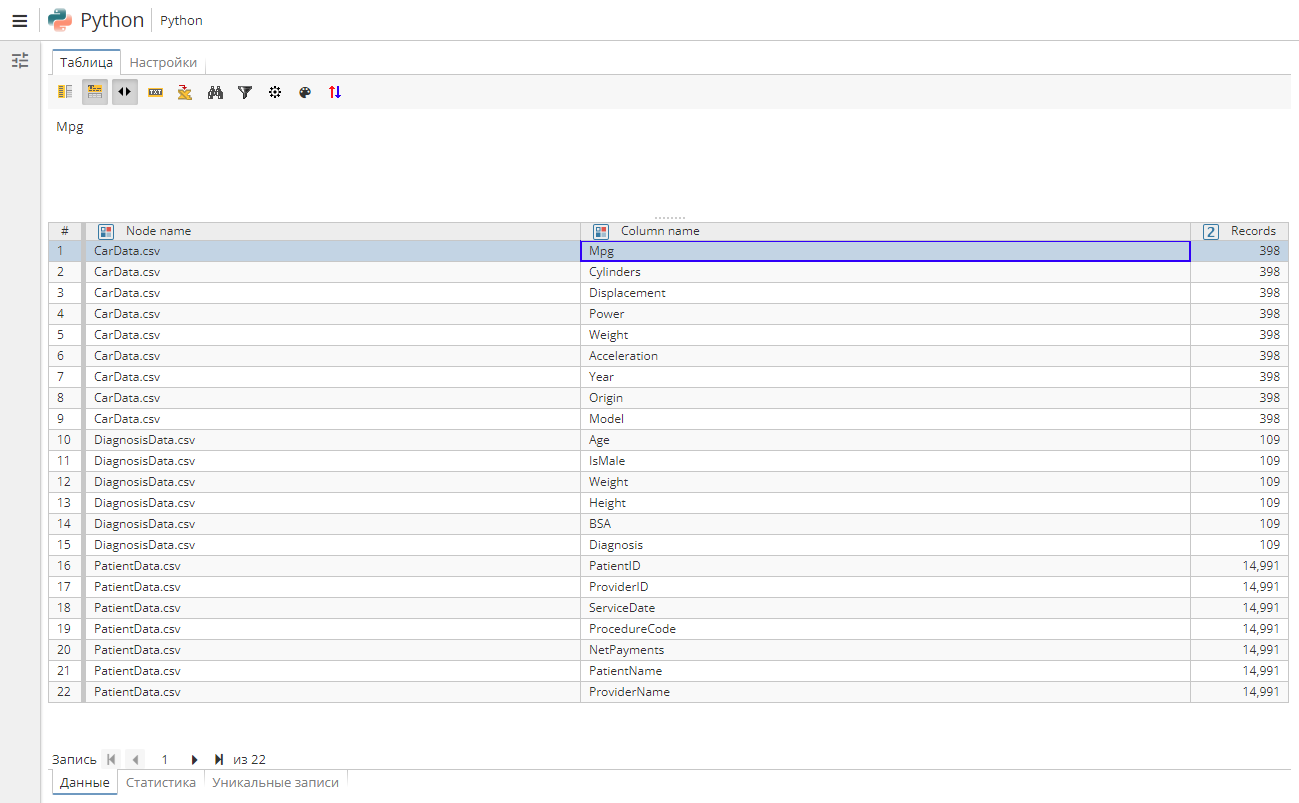
Согласно скрипту, каждая запись в создаваемой узлом таблице должна представлять собой объект, чьи свойства описаны в полях Node name (название узла), Column name (название колонки) и Records (записи). Эти поля используются для именования колонок в выходной таблице узла.
В скрипте также используется переменная parents, которая позволяет узлу последовательно обращаться ко всем родительским таблицам данных.
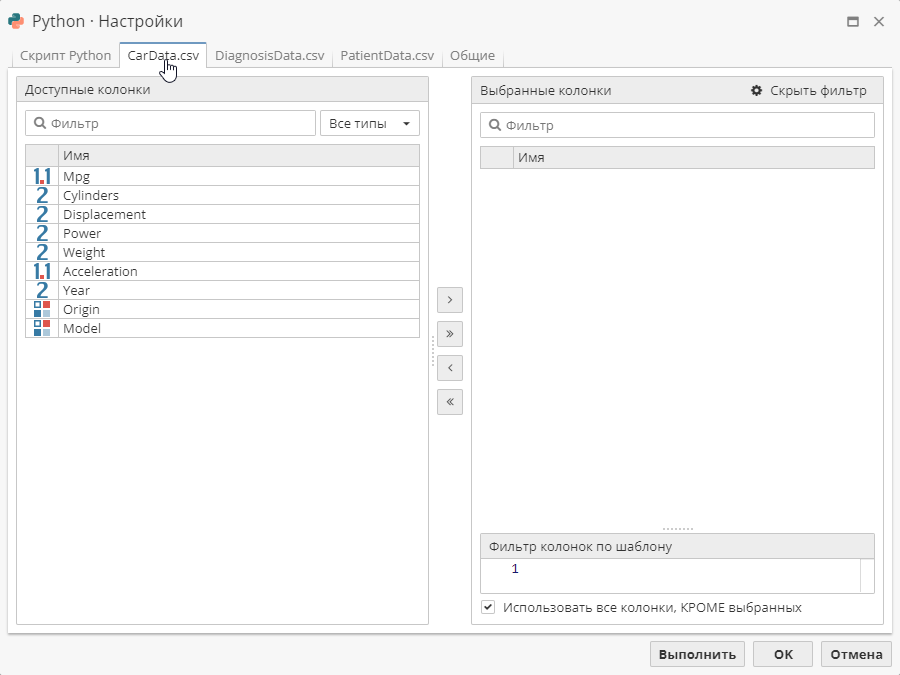
На вкладках для выбора колонок переместите все колонки из списков доступных колонок в выбранные – это необходимо для решения нашей задачи по созданию своего рода реестра колонок и строк из всех исходных таблиц.
| При необходимости снимите флажок Использовать все колонки, КРОМЕ выбранных. |
В результате итеративного выполнения скрипта узел Python создаст таблицу данных из трех колонок:
-
Node name (Имя узла) – колонка с названиями родительских узлов;
-
Column name (Имя колонки) – колонка с названиями всех колонок из всех родительских таблиц;
-
Records (Записи) – колонка с количеством записей в родительских таблицах.