Настройка узла Выборка
Окно настроек узла Выборка состоит из двух вкладок: Выбор строк и Общие. Последняя вкладка присутствует практически во всех узлах PolyAnalyst и позволяет задать имя и описание узла. Остановимся подробнее на вкладке Выбор строк.
Первым шагом при настройке вкладки Выбор строк является выбор метода создания выборки:
-
Случайные строки – определенное количество случайных записей из исходной таблицы данных включается в выходные данные.
-
1 из N строк – первая из каждых N исходных записей включается в выходные данные.
-
Выборочное подмножество – N записей исходной таблицы данных, начиная с указанной записи, включаются в выходные данные.
-
Первые N% – количество записей в процентах от начала набора данных (от первой строки).
-
Последние N% – количество записей в процентах от конца набора данных (от последней строки).
-
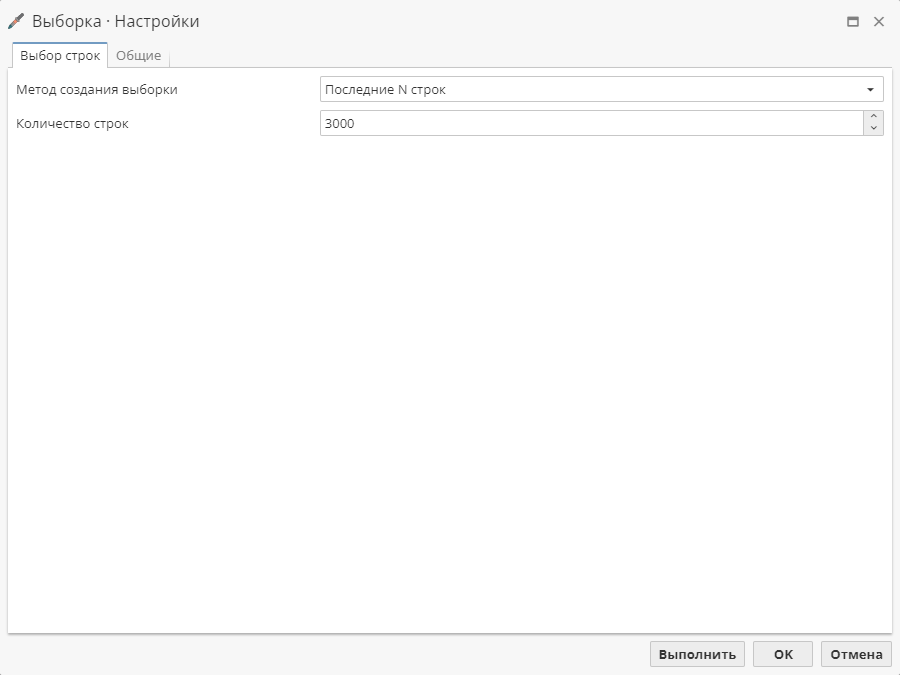
Последние N строк – количество записей с конца набора данных (от последней строки).
На скриншоте ниже выбран метод Случайные строки.
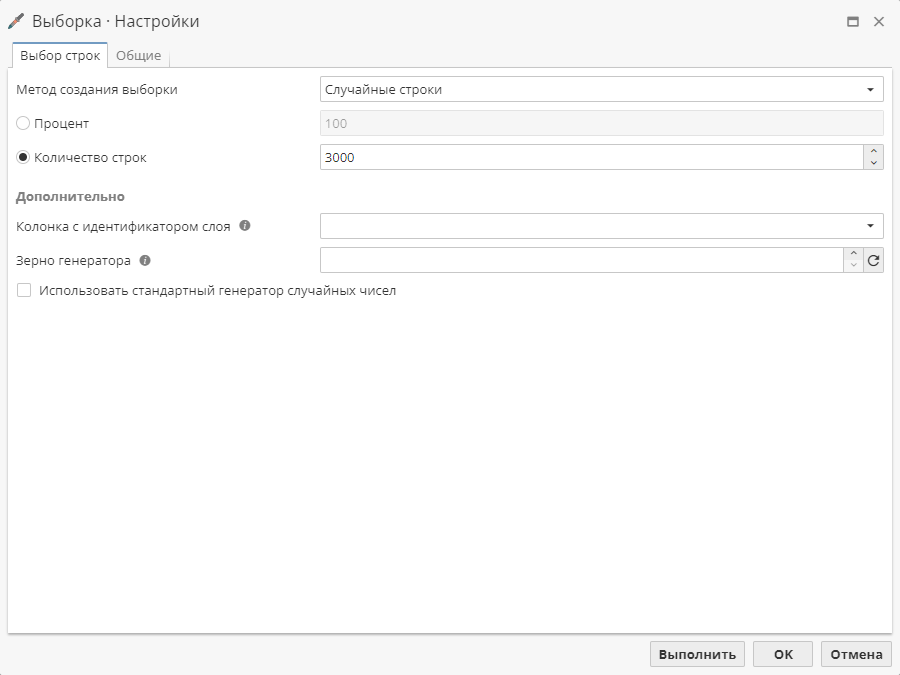
Для каждого метода выборки существует один или несколько дополнительных параметров. Для данного метода имеется несколько опций:
-
Процент – позволяет создать выборку, в которую входит указанный процент записей исходного массива данных. На рисунке выше в этом поле выставлено значение 50. Это означает, что выходные данные будут содержать 50% записей исходного массива данных.
-
Количество строк – позволяет создать выборку, в которую входит указанное число записей. PolyAnalyst не проверяет, не превышает ли указанное число строк реальное количество строк в исходном массиве данных.
-
Зерно генератора – задает зерно (ключ) генератора.
-
Использовать стандартный генератор случайных чисел (ГСЧ) – создает случайную выборку, используя стандартный генератор на языке программирования Си. Вопрос о преимуществах собственного ГСЧ системы PolyAnalyst и стандартного подробно рассматривается ниже в разделе Генерирование случайных чисел.
-
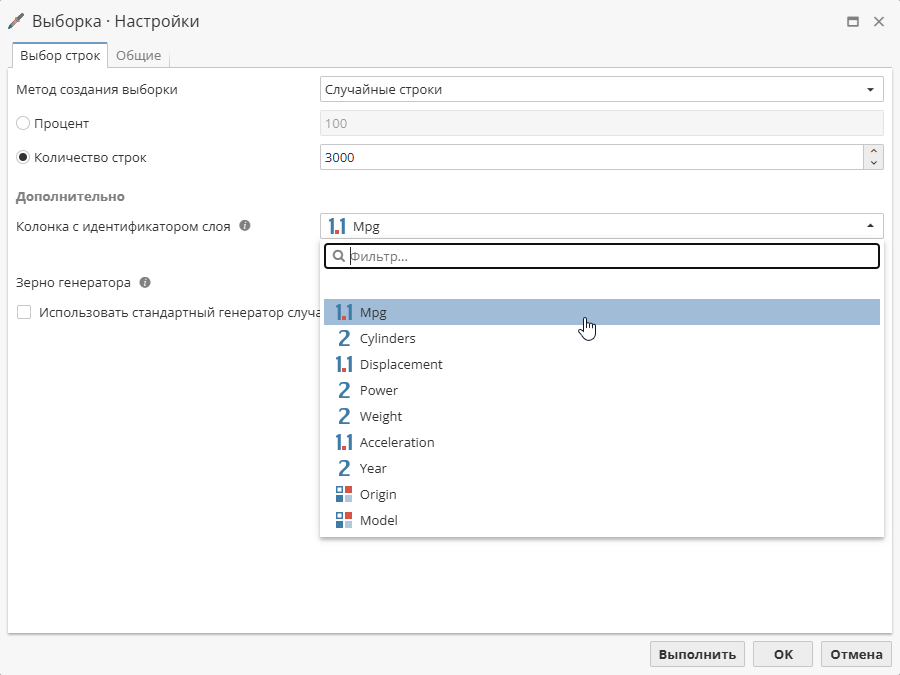
Колонка с идентификатором слоя – позволяет выбрать колонку, которая представляет идентификатор выборки. Данная опция подробно описана в разделе Создание стратифицированной выборки ниже.
В скриншоте ниже выбран метод 1 из N строк.
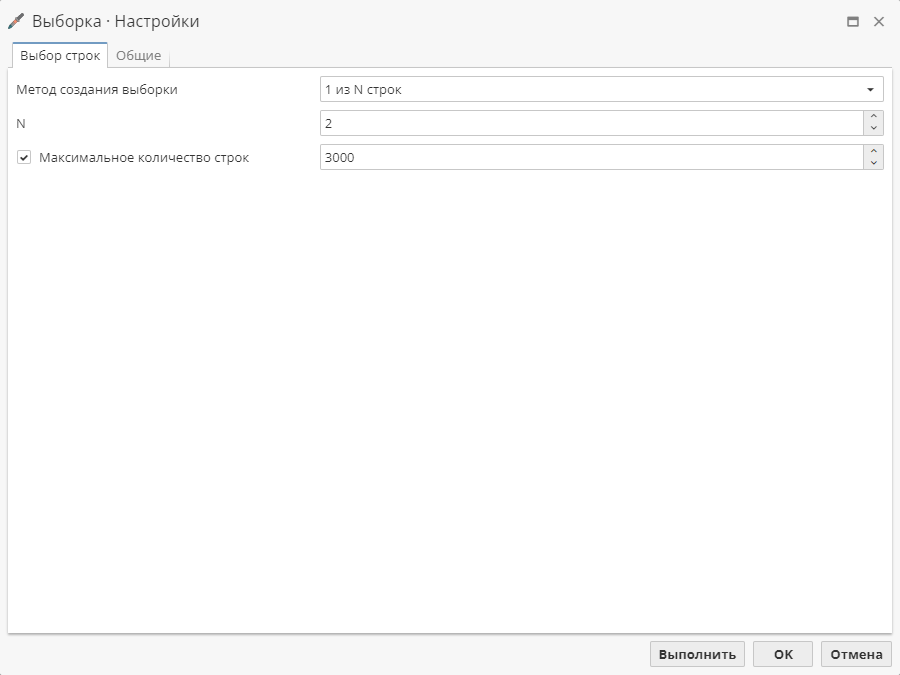
Для этого метода имеется один обязательный параметр – "N", где "N" – количество исходных записей, из которых первая попадет в выходную таблицу. Введите целое число в поле "N". В ходе выполнения узла PolyAnalyst будет последовательно оценивать исходные записи и сохранит первую из N записей в выходном массиве данных.
Опция Максимальное количество строк позволяет пользователям при необходимости указать верхний лимит по количеству строк, которые будут включены в выходные данные. Это позволяет ограничить количество записей в выходной таблице. Для установки данной опции поставьте галочку в соответствующем чекбоксе и введите количество строк. Обратите внимание, что в выходной таблице записей может быть меньше, чем указанное вами максимальное число. Это может произойти, если в исходной таблице записей меньше, чем указанное вами максимальное количество строк.
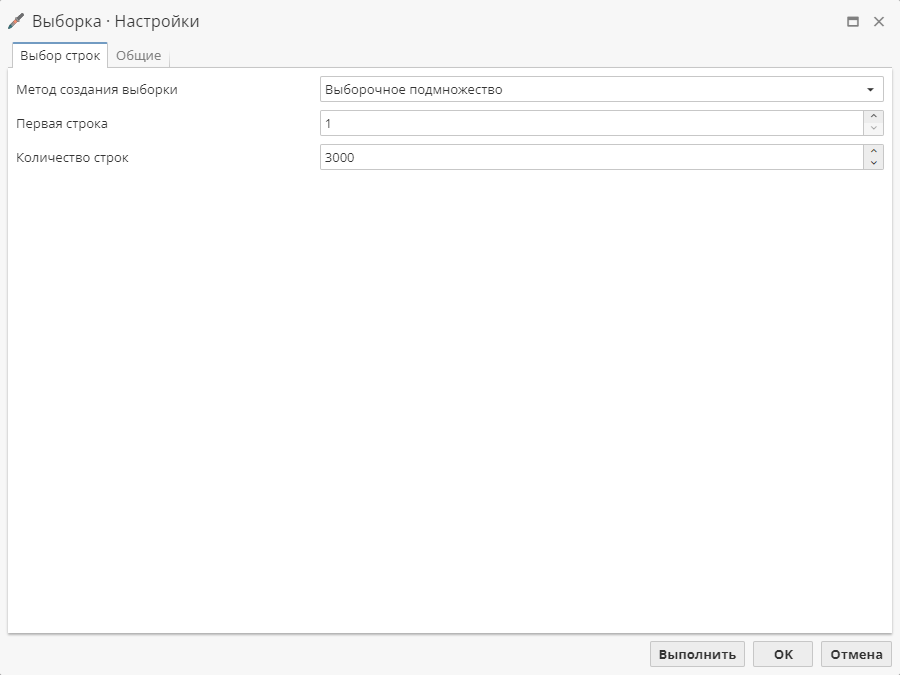
Опция Выборочное подмножество, имеет два обязательных для настройки параметра: Первая строка и Количество строк. Например, если ввести 1 в поле первой строки и 30 в поле количества строк, узел создаст выборку из первых 30 записей. Если указать 5 строку в качестве первой, сохранив при этом желаемое количество записей, узел включит в выборку записи с 5 по 35 включительно. Обратите внимание, что, если в исходных данных строк меньше, чем указанное число строк, в выходных данных узла строк будет меньше.
Опции Первые N% и Последние N% позволяют указать количество процентов для выборки из исходного набора данных.
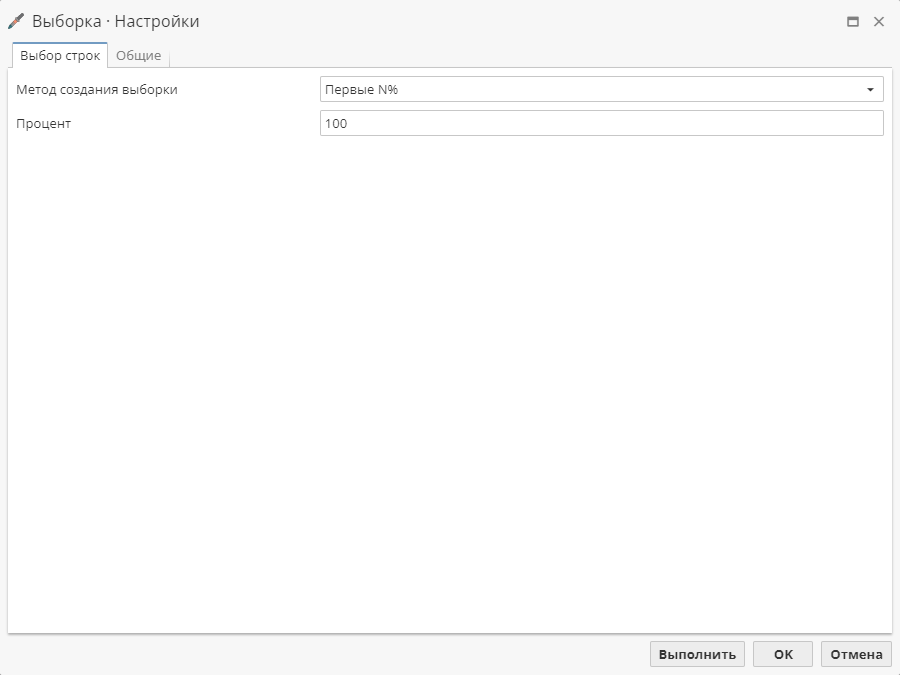
Опция Последние N строк позволяет указать количество строк для выборки начиная с последней строки исходного набора данных.
Генерирование случайных чисел
Существует много способов симуляции создания случайного числа с помощью компьютерной программы.
Если указано зерно (ключ), то случайное число генерируется на основе этого зерна. При наличии зерна последовательность созданных случайных чисел всегда одна и та же. Числа являются псевдослучайными, а результат всегда детерминирован исходным ключом.
Определение зерна имеет смысл в тех случаях, когда необходима случайность выборки, но эту случайность нужно воспроизвести при последующем выполнении узла (например, при обучении моделей или при создании таблицы с выборкой данных).
Когда зерно не задано, PolyAnalyst использует другие автоматические методы создания случайного числа, например, текущее время (точный момент времени в микросекундах, в который внутренняя функция выборки запросила новый случайный номер). Когда зерно генерируется таким образом, например, при использовании времени, то можно гарантировать, что оно не будет использовано дважды, что повышает случайность выборки.
Если включена опция Использовать стандартный генератор случайных чисел (ГСЧ) (метод создания выборки – Случайные строки), PolyAnalyst использует стандарт языка программирования Cи. Такой метод генерирования случайных чисел используется во многих программных инструментах. Однако, некоторые пользователи отрицают возможность создания выборки с высокой степенью случайности при использовании метода ГСЧ с помощью стандарта Cи. Если эта опция отключена, PolyAnalyst использует собственный ГСЧ.
В целом, отметим, что выбор между собственным ГСЧ и стандартом Си не имеет критического значения. Возможность использования альтернативного ГСЧ предусмотрена в данном узле на тот случай, если в ходе изучения выходных данных пользователь обнаружит, что выборка является недостаточно случайной, и решит использовать другой подход. Такая ситуация возникает редко.
Создание стратифицированной выборки
Стратифицированная (или послойная) выборка предполагает разделение таблицы данных, представляющих всю популяцию, на подгруппы, с последующей выборкой из каждой из этих подгрупп.
Чтобы использовать стратифицированную выборку, выберите колонку в соответствующем выпадающем меню:
Послойная выборка является более предпочтительной в тех случаях, когда необходимо улучшить репрезентативность выборки из всей таблицы данных, сократив вероятность погрешности. Послойная выборка может создать среднее взвешенное значение, которое является менее вариативным по сравнению со средним арифметическим значением простой случайной выборки на основе всей таблицы данных.
Каждое подмножество, или подгруппа данных исходной таблицы, называется слоем (или стратой). Слои должны взаимно исключать и взаимно дополнять друг друга, чтобы каждый элемент совокупности (каждая запись) относился к одному и только одному слою, и ни один элемент не остался за пределами слоев.
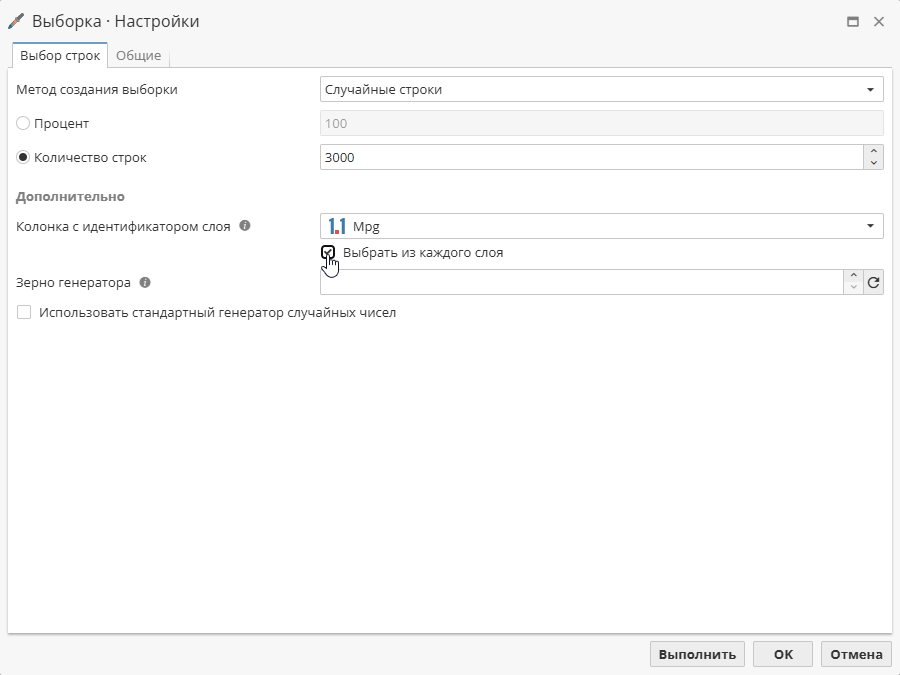
Чтобы выбрать записи из каждого слоя, установите соответствующий флажок:
Обратите внимание, что использование опции возможно только при использовании метода Количество строк:
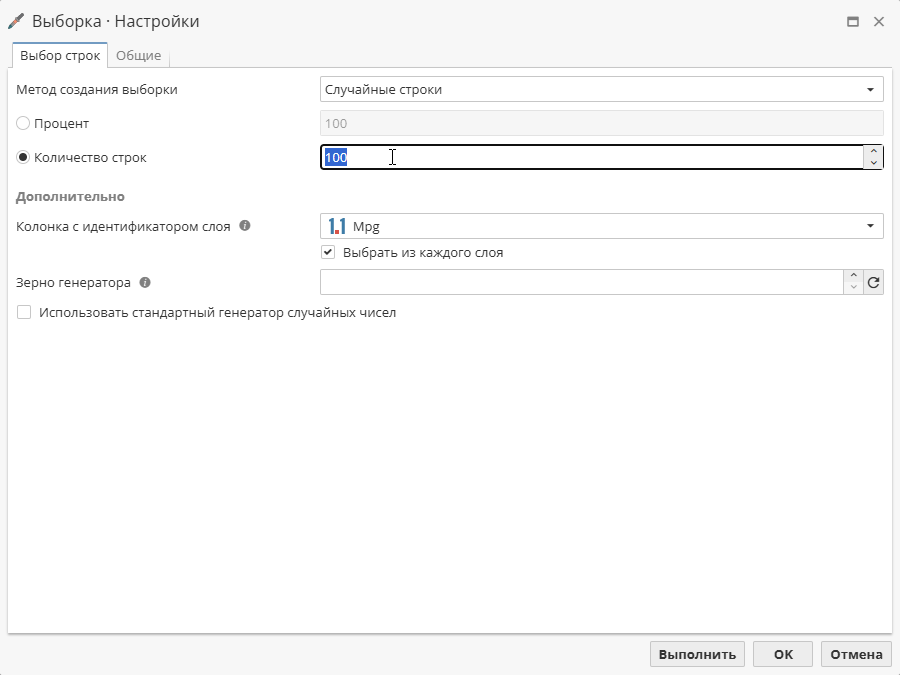
В этом случае в поле Количество строк указывается количество значений, которые необходимо получить из каждого слоя.
| Создание послойной выборки незначительно влияет на производительность и масштабируемость узла Выборка. |
Если не указать колонку с ID слоя, узел создаст простую случайную выборку.