Применение моделей
Одним из главных достоинств узла Применение моделей является возможность применения модели к набору данных, отличному от тех данных, на которых модель была обучена. Например, один набор узлов загружает обучающие данные, готовит их и создает модель регрессии. Другой набор узлов загружает производственные данные, затем используется узел Применение моделей, и полученная модель регрессии применяется к производственным данным предприятия. Модели могут быть применены к любому количеству таблиц данных.
Выходные данные узла Применение моделей – новая колонка, содержащая прогнозируемые значения, которые могут быть входными данными для другой модели. Таким образом, модели могут быть подготовлены на выходных данных предыдущих моделей.
Узел Применение моделей используется в комбинации с узлом моделирования для того, чтобы применить модель к другому набору данных. Применение моделей происходит очень быстро, так как нет необходимости помещать модель в протокол третьей стороны. Вместо этого она хранится в PolyAnalyst, за счет чего к ней всегда обеспечен быстрый доступ. Более того, это также позволяет применять модель к данным внутри системы PolyAnalyst. Недостатком является то, что данные для применения модели должны быть загружены в PolyAnalyst. Это означает, что сервер должен находиться на мощной машине, которая сможет хранить большой объем информации, который может достигать нескольких гигабайт. Это значит, что нагрузка на аппаратные средства пользователя будет существенной, если учесть, что приходится использовать специальное оборудование также и для хранения баз данных и прочих систем.
Для применения модели к другим таблицам необходимо убедиться в том, что колонки исходной таблицы имеют такие же названия и содержат тот же тип данных, что и модель. Иначе модель будет бесполезной, или будет обрабатывать значения неверно. В связи с этим, вместе с узлом Применение моделей часто используется узел Производные колонки для того, чтобы создать нужные типы колонок.
Во время такого анализа большинство пользователей сначала создают узел, который будет обучать, тестировать и оценивать модель. Это подразумевает загрузку и разбиение данных, прочие необходимые приготовления, а также ввод данных в модель. Когда модель получена, следующим шагом будет создание новой таблицы данных для применения модели, а также создание узла Применение модели, с последующим соединением таблицы, модели и узла Применение моделей. Помните, что выход узла Применение моделей – данные, к которым применена модель. Узел Применение моделей при желании можно соединить с тем же данным, на которых была обучена модель. Затем полученные данные могут быть использованы в качестве исходных данных для другого алгоритма. Таким образом, пользователи могут соединить несколько последующих алгоритмов, каждый из которых подготовлен с помощью выходных данных предыдущей модели. В этом состоит одно из преимуществ скрипта PolyAnalyst, который дает возможность варьировать сочетания различных узлов и шагов в разном порядке.
Другая часто применяющаяся комбинация – это загрузка обучающих данных, применение модели, затем соединение обработанных данных с узлом Экспорт в файл или Экспорт в ODBC. Таким образом пользователи могут постоянно опробовать модель на новых данных, не меняя настройку скрипта, и работать с экспортируемыми данными в различных приложениях, так как теперь они хранятся во внешней базе данных.
Если узел моделирования, соединенный с узлом Применение модели, не содержит действенной модели, в выходе узла Применение модели может быть представлена только исходная таблица данных без дополнительной колонки. Это также будет отражено в окне просмотра результатов узла моделирования. Некоторые узлы моделирования в PolyAnalyst могут быть выполнены, но при этом не создать действенной модели.
Почти все узлы моделирования в PolyAnalyst используются в комбинации с узлом Применение модели. Сначала модель обучается на тренировочных данных, при этом создается, настраивается и выполняется один из узлов моделирования, например, Линейная регрессия. Чтобы применить модель к другой таблице данных, создайте узел Применение моделей (операция с колонками), и соедините импортированную тестовую таблицу и узел моделирования с узлом Применение моделей. Затем выполните узел Применение моделей. Выходными данными узла Применение моделей является таблица данных, которая кроме исходных колонок содержит одну или несколько колонок с результатами применения модели к каждой записи. Результаты узла Применение моделей можно экспортировать, используя один из нескольких методов экспорта данных в PolyAnalyst, например, узел Экспорт в файл и узел Экспорт в ODBC, либо с помощью кнопки Экспорт данных на панели инструментов в окне просмотра результатов узла Применение моделей. Как все проекты и узлы, его можно настроить на работу по расписанию с помощью Планировщика задач. Таким образом, вы можете повторно применять одну и ту же модель к новым импортированным данным.
Обратите внимание, что каждый раз при запуске узла-источника данных, который импортирует обучающие данные, вы будете также запускать тот узел, который обучает прогностическую модель. Это может привести к тому, что результаты будут изменяться каждый раз при применении модели к новым данным. Организуйте свой скрипт так, чтобы вам не пришлось повторно обучать модель. В разделе по заморозке узлов вы найдете информацию о том, как заблокировать узлы, чтобы обученная модель не обновлялась при повторном запуске узла. На обучение некоторых моделей может уйти до нескольких часов, что недопустимо, если перед пользователем стоит задача быстро применить модель к новым данным.
В данный момент PolyAnalyst не позволяет применять модели к данным, которые не были импортированы в систему с помощью одного из узлов-источников данных. Это гарантирует эффективность и скорость применения моделей, а также дает возможность применить модели к источникам данных любого формата (например, к любым базам данных, совместимым с ODBC) без необходимости создания частной модели для каждого проекта.
PolyAnalyst может применять модели только к тем таблицам данных, которые импортированы в один проект, за исключением тех случаев, когда с помощью узла Ссылка вы ссылаетесь на таблицы данных в других проектах.
Одна и та же модель может быть применена к нескольким контрольным таблицам данных. При этом каждая таблица данных должна быть правильно соединена с узлом Применение моделей. Вам не нужно каждый раз создавать новую модель, вы можете повторно использовать тот же узел, содержащий обученную модель, для каждого узла Применение моделей. На следующем скриншоте 3 отдельных обучающих таблицы используют одну и ту же прогностическую модель. Каждая таблица импортируется, к ней применяется модель, затем она экспортируется, но при этом все таблицы используют одну и ту же модель.
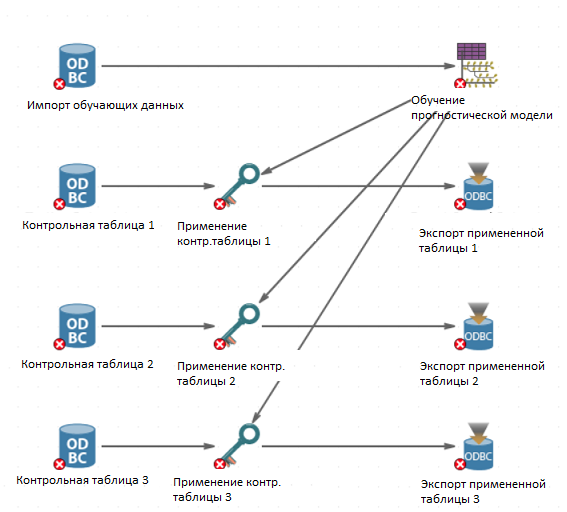
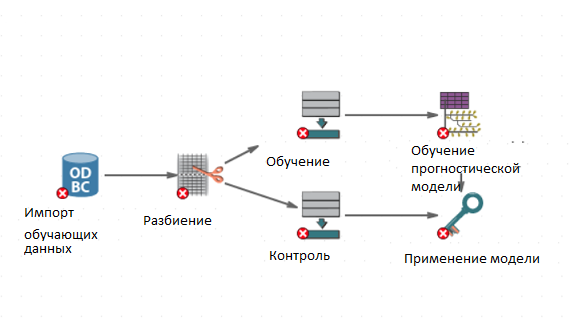
Если в одной и той же таблице данных хранятся и обучающие, и контрольные данные, то у вас есть несколько вариантов действий. Если вам известно некоторое логическое условие, которое разделит данные на две таблицы, вы можете создать два узла Фильтрация строк, один из которых сохраняет только обучающую таблицу, а другой – ее дополнение (контрольную таблицу данных). Вы также можете использовать узел Разбиение, который предназначен именно для этой цели (разбиение таблицы на части, которые в свою очередь называются подмножествами). При этом узел Разбиение добавляет новую колонку с идентификатором, означающим, к какому подмножеству принадлежит запись; этот идентификатор затем может использоваться как часть выражения в узлах Фильтрация строк. Например, вы можете сохранить в отдельной таблице только те записи, которые входят в Подмножество Х. На следующем скриншоте изображено такое разбиение исходных данных на обучающую и контрольную таблицы. Модель отрабатывается на обучающем подмножестве, а затем применяется к контрольным данным.
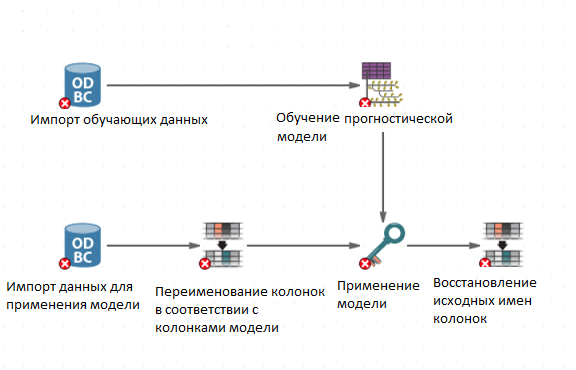
Узел Применение моделей будет выполняться некорректно, если исходная таблица данных содержит колонки, имена и тип данных в которых отличаются от колонок модели. Чтобы устранить эту проблему, используйте узел Модификация колонок для переименования и выбора нужных типов данных для соответствующих колонок в таблице. Вы можете восстановить исходные имена колонок позже, добавив второй узел Модификация колонок после узла Применение моделей. Изменения колонок происходят очень быстро даже в больших таблицах; проблем производительности не возникает.
Выходные данные узла Применение моделей зависят от модели, которая была применена, следовательно, формат выходных данных описывается в каждой модели. Узел Применение моделей не имеет настраиваемых свойств. Поведение узла Применение моделей зависит от того, с какой моделью он соединен. Сама модель определяет способ ее применения. Во многих моделях имеется вкладка, на которой вы можете настроить способ применения моделей. Эти настройки не влияют на саму модель, они лишь управляют тем, как узел Применение моделей будет функционировать при работе с данной моделью.