Файлы-схемы CSV
Файлы-схемы позволяют сохранять настройки колонок. Пользователи могут сохранять настройки имен колонок, типов данных и информацию о парсинге в отдельный файл-схему. Данный файл в дальнейшем можно загрузить в узел Файлы CSV или Экспорт в файл для быстрой настройки.
Схемы крайне удобны при работе с большим количеством колонок, поскольку это позволяет избежать необходимости воспроизводить одни и те же настройки колонок по нескольку раз. Имейте в виду, что использовать файлы-схемы так же просто (а для некоторых пользователей даже проще и понятнее), как скопировать и вставить узел Файлы CSV при необходимости его повторного использования, или использовать узел Ссылка для того, чтобы сослаться на загруженные данные. Основное преимущество схем заключается в том, что они облегчают импорт CSV-файла, который был создан с помощью узла Экспорт в файл.
PolyAnalyst не знает о существовании файлов-схем и не управляет ими, они находятся исключительно в ведении пользователей. Рекомендуем продумать название папки, в которой будут сохраняться файлы-схемы.
По умолчанию опции конфигурации схемы не отображаются в диалоговом окне настроек узла, поскольку большинству пользователей это не нужно. Для отображения настроек схемы необходимо:
-
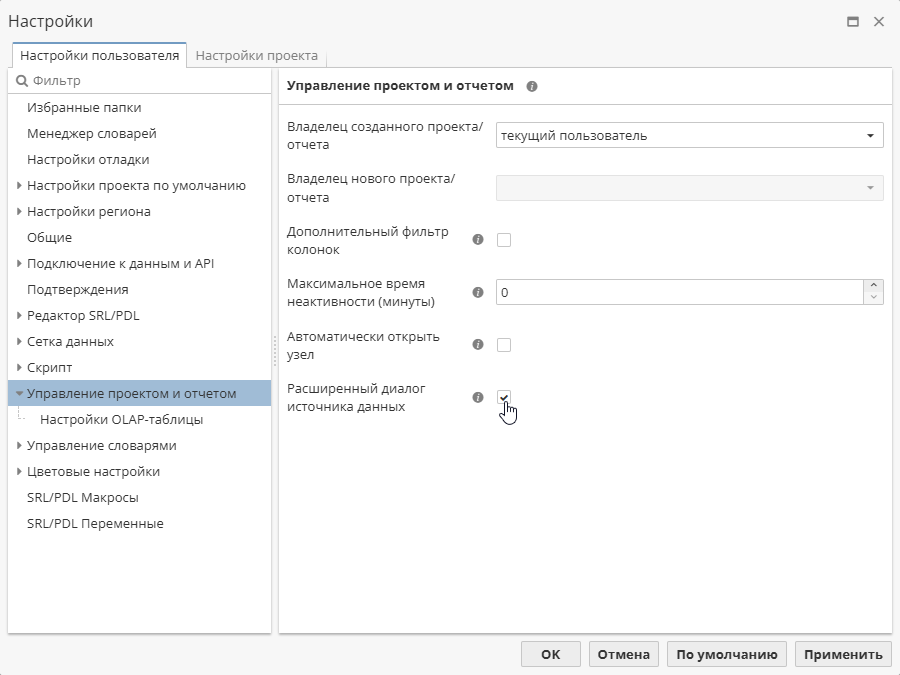
Открыть контекстное меню скрипта и выбрать Настройки проекта….
-
Переключиться на вкладку Настройки пользователя.
-
Выбрать раздел Управление проектом и отчетом.
-
Отметить галочкой опцию Расширенный диалог источника данных.
После этого на вкладке Выбор файла в окне настроек узла Файлы CSV появится новый раздел Схема:
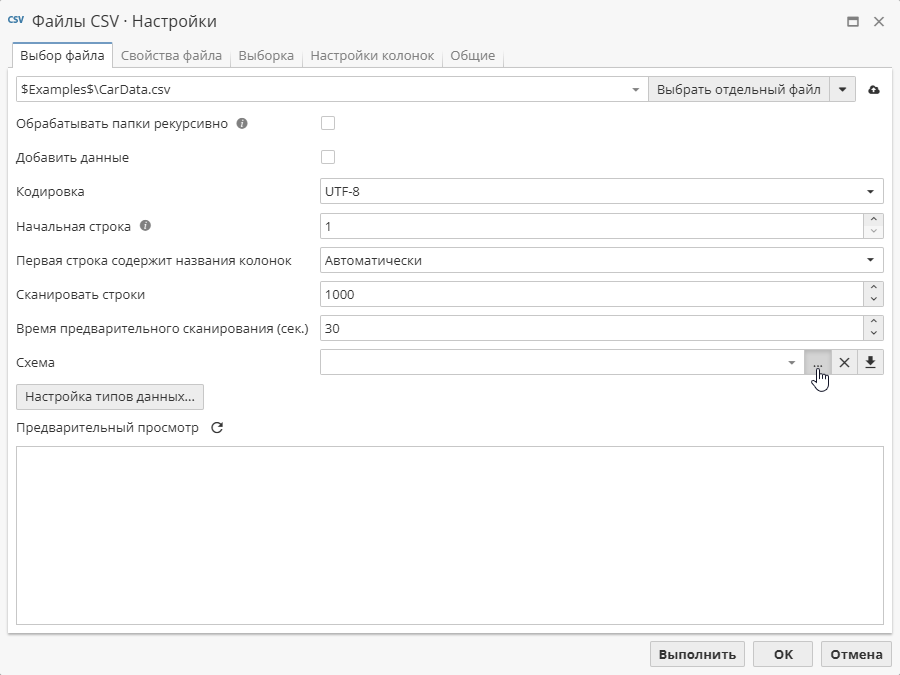
Нажмите соответствующую кнопку, чтобы добавить файл-схему.
| В процессе поиска файла-схемы или выбора места для сохранения нового файла вы находитесь в разделах компьютера, на котором запущен сервер PolyAnalyst, и который не всегда является тем же компьютером, на котором открыт Аналитический клиент PolyAnalyst. |
Файлы-схемы можно редактировать вручную в текстовом редакторе. Схема имеет стандартный формат ini-файлов. Это удобно, поскольку пользователи могут писать программы для автоматического создания файла-схемы, либо использовать команды пакетного редактирования в процессе обработки текста, что очень полезно при работе с тысячами колонок.
По определению файл-схема всегда содержит раздел schema. Данный раздел начинается с имени раздела в квадратных скобках [schema] на отдельной строке. Далее следуют различные параметры, представленные парой name и value. Сам синтаксис достаточно прост. Рассмотрим два примера:
Пример 1
Пример 2
При открытии файла CSV PolyAnalyst сначала ищет файл в той же папке под тем же именем, но с расширением *.sch. Если подобный файл существует, PolyAnalyst считывает из него определение схемы. Единого формата определения схемы CSV не существует. PolyAnalyst использует собственный формат.
SCH-файл – это файл, который может быть создан в любом текстовом редакторе, например, в Блокноте. Файлы SCH имеют следующую структуру:
Каждое общее свойство CSV указывается на отдельной строке. Это пара значений, разделенных знаком "=", подобно любому ini-файлу Windows. PolyAnalyst принимает следующие свойства:
Параметр |
Возможные значения |
Описание |
DateTimeFormat |
mm/dd/yyyy или dd/mm/yyyy |
В качестве значения выступает любая комбинация символов "y" (год), "m" (месяц) и "d" (день), при этом регистр не имеет значения. Обратите внимание: системе PolyAnalyst важна только последовательность компонентов даты (разделители будут проигнорированы). |
TimeFormat |
12 или 24 |
При использовании 12-часового формата после любого значения времени должны присутствовать обозначения AM/PM. По умолчанию используется 24-часовой формат. |
DateTimeSequence |
DT/TD |
Определяет, что следует первым – дата (Date) или время (Time). По умолчанию используется последовательность "TD" (время-дата). |
Format |
CSVDelimited или Fixed |
Тип CSV-файла: с разделителем или с фиксированной шириной. По умолчанию выбрано значение "CSVDelimited" (с разделителем). |
Delimiter |
Любой символ |
Разделитель CSV. По умолчанию выбрана запятая (","). |
RowsToSkip |
Любое число |
Количество строк, которые необходимо пропустить до парсинга файла CSV. |
Currency |
Текст |
Символ валюты. |
Months |
Текст |
Названия месяцев, разделенные "\n". Например, "Jan\nFeb\nMar\nApr…" |
dblf |
Комбинация символов "i", "f" и "s" |
Строка числового формата, где "i" обозначает целое число, "f" – дробную часть, а "s" – знак числа (для обозначения положительных и отрицательных чисел). Например, строковый формат "iiiiiiifffs" применительно к строке "0000030000-" дает числовое значение "-30". |
NAN |
Текст |
Список нулевых значений, разделенных "\n". |
Yes |
Текст |
Список элементов с логическим значением "да", разделенных "\n". |
No |
Текст |
Список элементов с логическим значением "нет", разделенных "\n". |
DOW |
Текст |
Список названий дней недели, разделенных "\n". |
FirstRow |
0, 1 или 2 |
0 – первая строка не содержит имен колонок, 1 – первая строка содержит имена колонок, 2 – имена колонок определяются автоматически. |
schemapropsep |
TAB (табуляция), SPACE (пробел) или любой другой символ |
Символ, используемый для разграничения частей списка определений колонок. По умолчанию используется TAB (табуляция). |
Определение каждой колонки в файле CSV дается в отдельной строке текста. Определение колонки имеет следующий формат:
[~]COLxxx=<имя> <тип> <аргументы>,
где все части (<имя> <тип> <аргументы>) разделены символом табуляции. Первый необязательный символ "~" обозначает, что данная колонка должна быть пропущена при импорте.
-
"xxx" указывает на номер колонки;
-
<имя> – имя колонки;
-
<тип> – тип колонки. PolyAnalyst различает следующие типы данных: "char" (символьный), "float" (число с плавающей запятой), "integer" (целое число) и "date" (дата);
-
<аргументы> – любые дополнительные аргументы колонки. Они образуют список из пар, разделенных ";". Каждая пара состоит из имени и значения аргумента, которые разделяются ":". Например:
COL1=Количество FLOAT dblf:iiiiiiifffs;size:11
В настоящее время PolyAnalyst различает следующие дополнительные аргументы колонки:
Аргумент |
Возможные значения |
Описание |
size |
Число |
Размер колонки в символах. Применимо только к CSV-файлам с фиксированной шириной колонок. |
dblf |
Комбинация символов "i", "f" и "s" |
Строка числового формата, где "i" обозначает целое число, "f" – дробную часть, а "s" – знак числа (для обозначения положительных и отрицательных чисел). Например, строковый формат "iiiiiiifffs" применительно к строке "0000030000-" дает числовое значение "-30". |
case |
0 или 1 |
Если указано значение "1", то список, указанный в параметре NAN рассматривается с учетом регистра, в противном случае регистр не учитывается. |
trim |
0 или 1 |
Если указано значение "1", то начальные и конечные пробелы в строковых значениях колонки будут пропущены. |