Добавление узлов на скрипт
Для того, чтобы добавить узел в аналитический проект, необходимо выбрать узел в Палитре узлов. По умолчанию палитра отображается в левой части окна Аналитического клиента PolyAnalyst.
Панель палитры может быть скрыта и изменена в размере. Если она скрыта, нажмите на кнопку Палитра узлов  в левом верхнем углу.
в левом верхнем углу.
Узлы в палитре организованы по категориям в зависимости от функции, выполняемой каждым узлом:
-
Источник данных: узлы для импорта данных.
-
Манипуляции с данными: узлы для изменения колонок и строк в таблице данных.
-
Анализ текстов: узлы для моделирования текстовых неструктурированных данных.
-
Анализ данных: для моделирования и изучения структурированных данных.
-
Визуализация: узлы для создания различных типов визуализации данных.
-
Экспорт данных: узлы для экспорта данных.
-
Вспомогательные узлы: узлы для получения различного рода дополнительной информации, например, просмотра журнала ошибок, отслеживание событий и т. д.
Поиск узла в палитре по имени
Для того, чтобы найти нужный узел в палитре, начните вводить название нужного узла в окне поиска, расположенном над палитрой узлов. Список узлов сократится до возможных вариантов, которые будут подсвечены.
Как правильно выбрать узел
Для того, чтобы научиться быстро выбирать нужные узлы, необходима практика. Пользователь всегда имеет возможность выбора из нескольких узлов. Сначала необходимо сузить поиск до определенной категории узлов, постараться по названиям узлов определить, что именно нужно вам для решения конкретной аналитической задачи.
Если вам сложно выбрать узел из палитры, возможно, в этот момент вам не хватает способности абстрагироваться, т.е. вы пытаетесь найти слишком специфический узел. В этой ситуации вам может понадобится два узла вместо одного.
И наоборот, возможно, вы пытаетесь подобрать узел для выполнения одной очень узкой, частной задачи.
Кроме того, подумайте, как можно назвать нужную вам операцию.
Вы также можете использовать Cправочник по узлам системы PolyAnalyst. Прочитайте вводные разделы по каждому узлу, чтобы понять, какую операцию выполняет тот или иной узел, с тем, чтобы определить, какой именно узел нужен вам.
Выбор подхода к анализу
Иногда недостаточно просто выбрать нужный узел. Возможно, вам также придется выбирать между несколькими возможными вариантами решения одной аналитической задачи.
В этом случае ни один из способов не является более предпочтительным, или более правильным. Критерии, которые повлияют на ваше решение, будут зависеть от ситуации. Возможно, один из способов является более масштабируемой операцией, или он более эффективен, более гибок или в меньшей степени предрасположен к ошибке.
Положение узлов
Расположение узлов на скрипте не влияет на порядок, в котором узлы обрабатывают данные. Порядок обработки данных определяется только направлением соединений.
Возможно, для вас наиболее предпочтительным окажется расположение узлов слева направо или сверху вниз, для того, чтобы указать, в каком порядке узлы выполняются.
Примеры скриптов
Когда вы будете изучать приведенные ниже примеры скриптов, постарайтесь обращать внимание на общую схему, а не на отдельные технические детали.
Анализ ответов, полученных в ходе опроса общественного мнения
Следующий скрипт представляет собой простой пример того, как вы можете использовать PolyAnalyst для изучения результатов опроса, содержащего открытый вопрос. Открытый вопрос представляет собой вопрос, на который дается нестандартный развернутый ответ, обычно в форме нескольких предложений, короткой фразы или нескольких абзацев, например: "Насколько вы довольны покупкой?"
В следующем примере узлы были специально расположены таким образом, чтобы подчеркнуть, что позиции узлов неважны. Здесь важно (1) присутствие конкретных узлов и (2) связи между узлами.
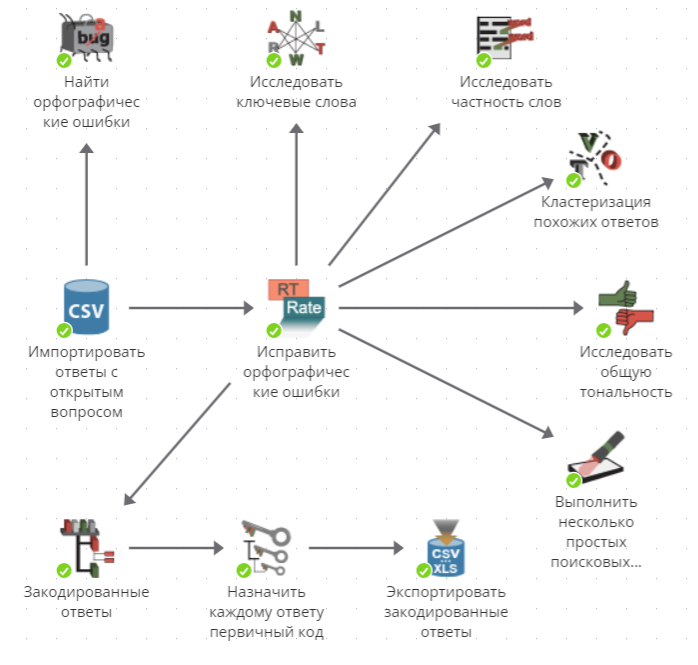
Начальной точкой в данном примере является узел Файлы CSV, названный "Импортировать ответы с открытым вопросом". Данный пример подразумевает, что вы собрали результаты опроса в файле формата CSV. Узел импортирует содержимое файла CSV в PolyAnalyst в виде таблицы. Каждый ряд в данных соответствует респонденту, а каждая колонка - вопросу.
Выходные данные этого узла поступают в узел Замены терминов, названный "Исправить орфографические ошибки". Этот узел ищет неправильно написанные слова и заменяет их в ответах.
Затем исследуется этот вопрос с открытым ответом. С помощью нескольких узлов генерируются разнообразные отчеты для изучения информации, например, по связанным ключевым словам или часто встречающимся словам. Респонденты группируются вместе узлом Кластеризация текстов (Кластеризация похожих ответов) на основе похожих ответов. Узел Анализ тональности (в примере - Исследовать общую тональность) генерирует отчет, показывающий, чьи ответы были в целом положительными, а чьи - в целом отрицательными или нейтральными.
Затем ответы опроса передаются инструменту текстовой классификации, называемому Таксономия (в примере - Закодированные ответы), где каждому ответу присваивается код. Таксономия создает отчет, который позволяет вам исследовать распределение ответов по кодам. Узел Применение таксономии (в примере - Назначить каждому ответу первичный код) затем добавляет в опрос новую колонку, в которой хранится наиболее значимый код для каждого текстового ответа.
Наконец закодированные ответы (вместе с исходными колонками из входных данных) экспортируются в файл.
В обобщенном виде были выполнены следующие шаги:
-
Данные опроса были импортированы.
-
Данные были очищены.
-
Текст ответов был проанализирован.
-
Ответы были разбиты на категории.
-
Категории ответов были экспортированы в файл.
Идеи, собранные в результате исследования данных, помогли сформировать коды, выбранные для классификации данных в узле Таксономия. За разведочным анализом часто применяется моделирование.
Действия от импорта данных опроса до их классификации и экспорта составляют ядро анализа. Если будут доступны результаты нового опроса, для исследования новых результатов можно использовать эту же последовательность. PolyAnalyst разработан так, чтобы свести к минимуму повторную настройку для выполнения аналогичного анализа на новых данных. После однократной настройки процесса вы можете свободно использовать его сколько угодно раз с новыми данными.
Одна из задач разработчиков PolyAnalyst - предоставить пользователям возможность поэтапно корректировать настройки узлов для получения более точных и полезных данных. Если вы нашли ошибку в настройке одного из промежуточных узлов в последовательности, вы можете просто изменить текущий процесс, а не начинать все с самого начала.
Применение моделей
Ниже приведен простой пример обучения модели на выборке данных и применения данной модели к новым данным.
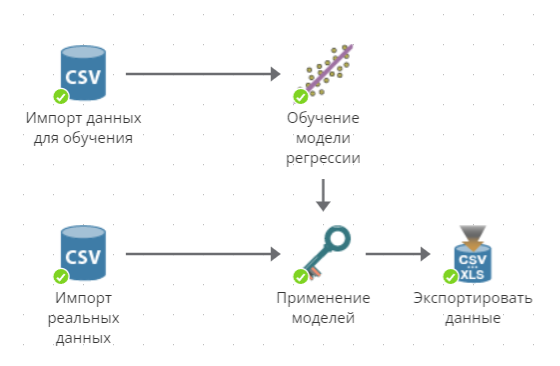
Выборка данных импортируется с помощью узла Файлы CSV, названного "Импорт данных для обучения".
Эти данные используются в качестве входных данных узла Линейной регрессии (Обучение модели регрессии). Выполняется обучающая модель. Затем, параллельно импортируются новые данные, о которых данная модель не оповещается. Модель применяется к другим данным с помощью узла Применение моделей.
Наконец, обработанные данные экспортируются в файл.
Имя и положение новых узлов по умолчанию
Когда вы добавляете узел на скрипт, PolyAnalyst приписывает узлу имя по умолчанию. Имя образуется от основного имени узла, приведенного в палитре узлов.
Каждый узел, который вы добавляете на скрипт проекта, должен иметь уникальное имя. Если вы добавляете один и тот же узел на скрипт несколько раз, PolyAnalyst приписывает ему имя с числовым суффиксом, например, "Имя по умолчанию (1)" или "Имя по умолчанию (2)".
После добавления узла вы можете изменить его имя.
Когда вы добавляете узел на скрипт, вам нужно выбрать положение узла. Узлы можно перемещать путем перетаскивания иконок.
| Для того, чтобы скрипт был понятен, следует избегать наложения узлов друг на друга. |
Добавление узла Файлы CSV на скрипт
Теперь можно приступать к практике.
Например, вы хотите добавить узел Файлы CSV на скрипт проекта.
-
Убедитесь, что проект, который вы создали, открыт. Если он закрыт, в меню выберите опцию Открыть, найдите проект и откройте его.
-
Убедитесь, что Палитра узлов в левой части окна Аналитического клиента не скрыта.
-
В палитре узлов найдите категорию Источник данных.
-
Найдите узел Файлы CSV.
-
Перетащите узел Файлы CSV из палитры узлов в окно скрипта. Для этого левой кнопкой мыши нажмите на имя узла в палитре и удерживая кнопку переместите курсор мыши на окно, а затем отпустите кнопку мыши.
Ваш скрипт теперь выглядит примерно так:
На этом этапе узел не может выполнять никаких действий, он не производит никаких результатов. Данные еще не импортированы.
Другие способы добавления узлов
-
Нажмите дважды на иконку узла или имя узла в палитре узлов. Новый узел будет добавлен автоматически. После создания вы можете его переместить.
-
Правой кнопкой мыши нажмите на узел в палитре узлов и выберите Добавить в проект. Новый узел будет добавлен автоматически.
-
Правой кнопкой мыши нажмите на пустое место в окне скрипта и выберите узел, который нужно добавить, из подменю Добавить узел. Новый узел будет добавлен в то место, куда вы нажали правой кнопкой мыши.
-
Правой кнопкой мыши нажмите на существующий на скрипте узел и выберите узел, который нужно добавить, из подменю Добавить узел…. В этом случае новый узел автоматически соединяется с выбранным вами существующим узлом.
Ниже представлен пример подменю Добавить узел…, которое открывается при нажатии правой кнопкой мыши на существующий узел Файлы CSV на скрипте проекта.
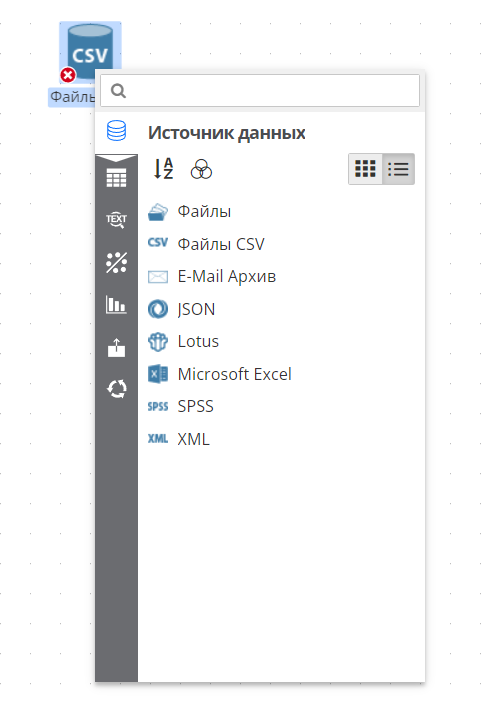
-
Перетащите CSV файл с вашего компьютера на скрипт, что приведет к автоматической загрузке файла и созданию соответствующего предварительно сконфигурированного узла Файлы CSV. Кроме файлов в формате CSV, возможно перетаскивать файлы в форматах XLS, JSON, XML, а также любые изображения, документы и архивы. При этом соответствующие узлы будут автоматически созданы на скрипте.
Общая информация о дереве проекта
Когда вы работаете с проектами с большим количеством узлов, удобнее находить узлы, которые вы уже задействовали в проекте, в дереве проекта, вместо того, чтобы разыскивать их на скрипте. Дерево проекта - это еще один вариант графического отображения иерархии узлов, добавленных в проект. Недостаток дерева проекта состоит в том, что оно не отображает связей между узлами.
Чтобы увидеть дерево проекта, нажмите на кнопку Дерево проекта в левом верхнем углу под кнопкой Палитра узлов.
С более подробной информацией об организации узлов в дереве проекта можно ознакомиться в разделе Знакомство с интерфейсом PolyAnalyst.
Дерево проекта отличается от палитры узлов: палитра содержит узлы, которые могут быть добавлены на скрипт, в то время как дерево проекта отображает узлы, которые уже добавлены.
После того, как вы добавите новый узел на скрипт, он автоматически отразится в дереве проекта. И наоборот, если вы удаляете узел со скрипта, он исчезает из дерева проекта. Дерево проекта - это всего лишь альтернативная форма представления содержания вашего проекта.