Configuring the Transactional Basket Analysis node
| This node/feature is available only if it is enabled in the PolyAnalyst Server license. |
The properties dialog is divided into 3 tabs: Select columns, Settings, and General. Select the columns to analyze on the Select columns tab, configure some algorithm constraints on the Settings tab, and set the name and description of the node on the General tab.
On the first tab, the list of available columns is located on the left. It displays all columns from the input dataset (the output of the preceding node) which can be used as part of the configuration. Note that only columns with certain data types are listed. Users can filter the available columns list to quickly locate a column by name. The list serves as a source of columns to use as the Customer ID, Product ID and or Transaction volume columns.
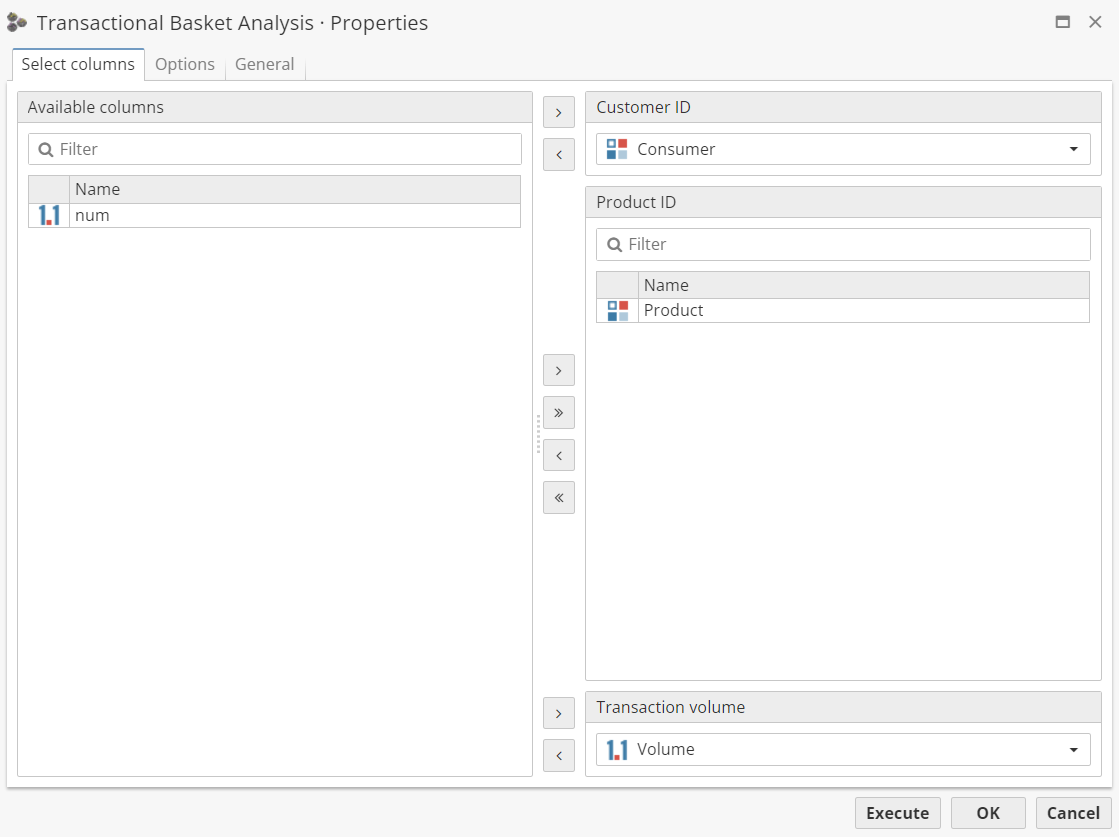
The Customer ID represents the aggregation key by which to group together separate purchases. In the expected data format, there is a column which represents the identifying person or unit by which to group together the transactions. For instance, if a customer purchases a second product, the fact that a second product is purchased is because the two product purchases are linked together by the customer’s ID. This does not have to actually be the ID of some customer. It can be any ID by which to group together the product purchases, like a demographic region (which contains several IDs). It does not even have to represent a person, perhaps it could be "store location", if one desires to consider all products purchased at the same location as a group. The Customer ID is required and must be a String field.
The Product ID represents the identifier of the product that was purchased. If there are multiple product purchases, users can add additional product ID columns, although one is preferred. These product purchases will be aggregated by the customer ID and represented as true/false columns in the output, whether or not the corresponding customer ID was involved in the purchase (there was a record containing an instance of both the customer and the specific product). Product IDs must be Strings. At least one product ID is required.
In some cases, a unit amount is stored along with the purchase (like 5 barrels of hay or 6 stacks of sugar, or 20 dollars of meat). It is also possible to store this amount per customer key. By default, the Transaction volume field is enabled. To hide it, uncheck the Sum identical transactions option in the Node defaults section. If the volume attribute is set, instead of generating Boolean columns representing whether or not a product was purchased, the product columns store the volume amount (summed) per customer. Products not purchased are stored as 0.00. The precision is two digits. It is not required to set this value unless there is the desire to force the algorithm to work based of volume instead of just Boolean yes/no values. Volume amounts are more precise in that the algorithm can see how much of the product was used or purchased, instead of only seeing the fact of whether or not it was used/purchased.
The Model name pattern field is used to set the model name. Click here for detail.
The Settings tab contains options for controlling what association rules can be developed by the algorithm and how it works with the data to find associations.
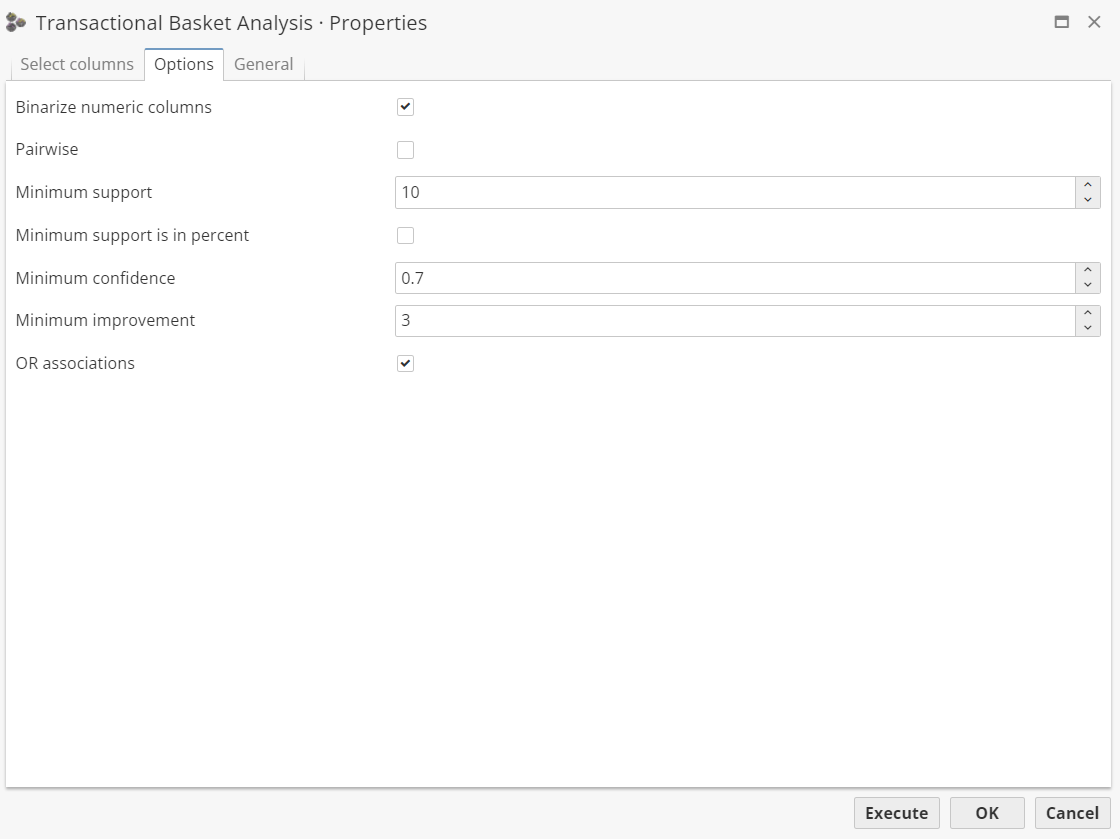
All the options on this tab were described with detail in the section Configuring the Basket Analysis node.